示例一:数据排序
1.1 问题描述
“数据排序”是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。
这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。
1.2 实例描述
对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个数字代表原始数据在原始数据集中的位次,第二个数字代表原始数据。
INPUT
file1
==========
82
32342
65224
3332
415
742356
223
file2
==========
786
6788678
2342
55
5464
123
file3
==========
12
88
100
OUTPUT
1 12
2 55
3 82
4 88
5 100
6 123
7 223
8 415
9 786
10 2342
11 3332
12 5464
13 32342
14 65224
15 742356
16 6788678
1.3 设计思路
这个实例仅仅要求对输入数据进行排序,熟悉MapReduce过程的读者会很快想到在MapReduce过程中就有排序,是否可以利用这个默认的排序,而不需要自己再实现具体的排序呢?答案是肯定的。但是在使用之前首先需要了解它的默认排序规则。它是按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String的Text类型,那么MapReduce按照字典顺序对字符串排序。
了解了这个细节,我们就知道应该使用封装int的IntWritable型数据结构了。也就是在map中将读入的数据转化成IntWritable型,然后作为key值输出(value任意)。reduce拿到
1.4 代码实现
package sort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DataSort {
public static class Map extends Mapper {
//实现Map函数
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将输入的纯文本文件的数据转化成String,并去掉前后空白
String line = value.toString().trim();
//context.write(line, 1) 输出以line为key,1为value的数据
if(!"".equals(line)) {
context.write(new IntWritable(Integer.parseInt(line)), new IntWritable(1));
}
}
}
public static class Reduce extends Reducer {
IntWritable line = new IntWritable(1);
@Override
protected void reduce(IntWritable key, Iterable values, Context context) throws IOException, InterruptedException {
//遍历,取出每一个元素
for (IntWritable num:values) {
context.write(line, key);
line = new IntWritable(line.get()+1);
}
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "192.168.125.129:9000");
Job job = new Job(conf, "Data Sort");
job.setJarByClass(DataSort.class);
//设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//设置输入和输出目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0:1);
}
}
1.5 导出JRE包
在sort.java文件上点击右键,选择导出,弹出界面
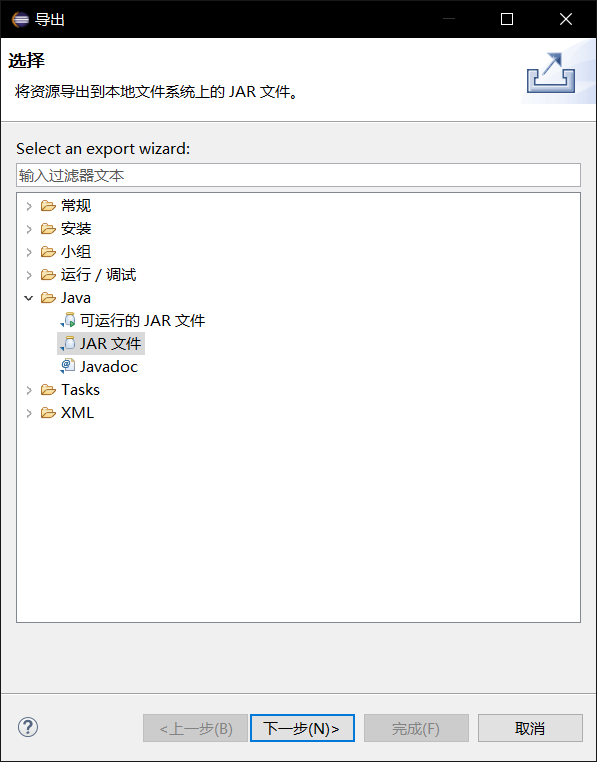
选择Java/JAR文件,点击下一步
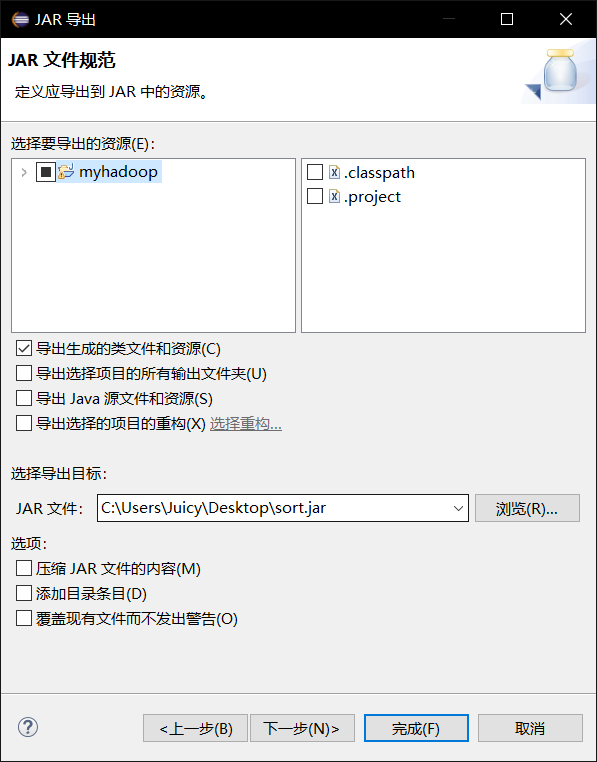
选择要导出的资源和导出的文件位置,点击完成,导出成功。
1.6 执行Hadoop/MapReduce
1.6.1 上传文件
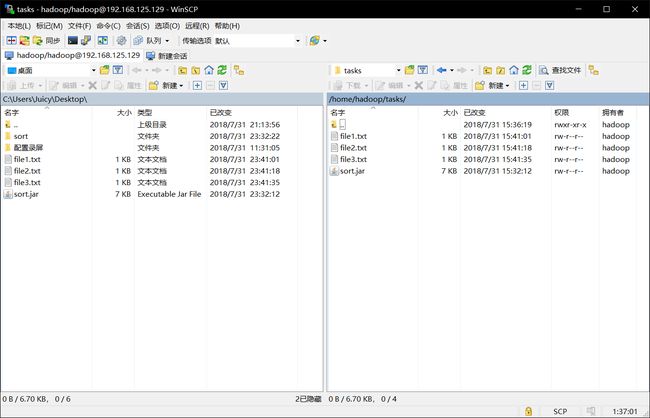
将sort.jar与file1.txt、file2.txt和file3.txt一起上传到Hadoop集群的master主机的/home/hadoop/tasks目录下
1.6.2 启动Hadoop集群
./sbin/start-all.sh
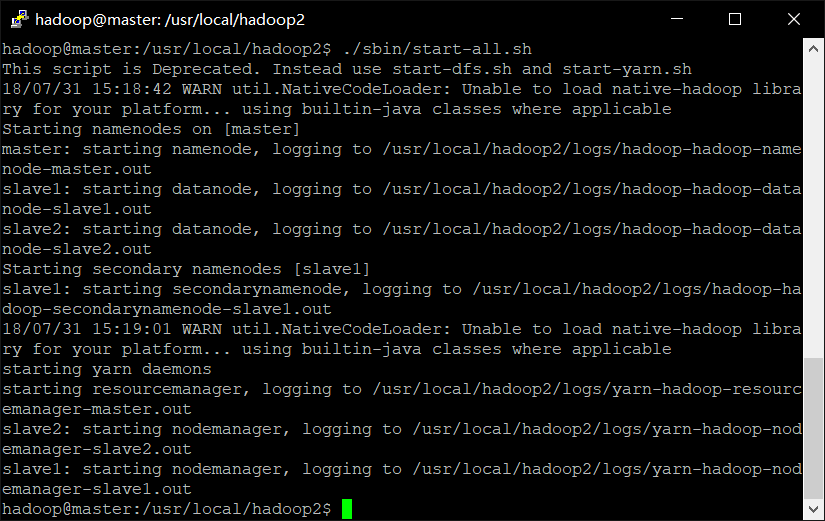
启动完成
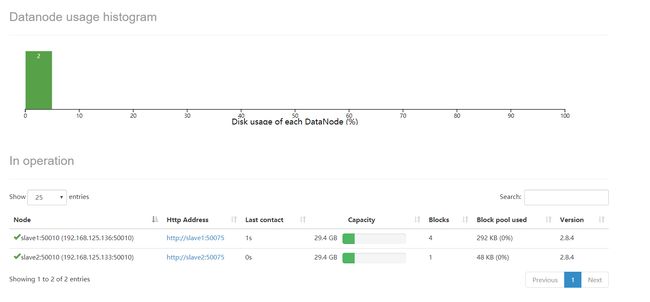
1.6.3 将文件上传到input
cd ~
cd /home/hadoop/tasks
cat file2.txt >> file1.txt
cat file3.txt >> file1.txt
cat file1.txt
再输入:
hadoop fs -mkdir -p input
hadoop fs -copyFromLocal word.txt input
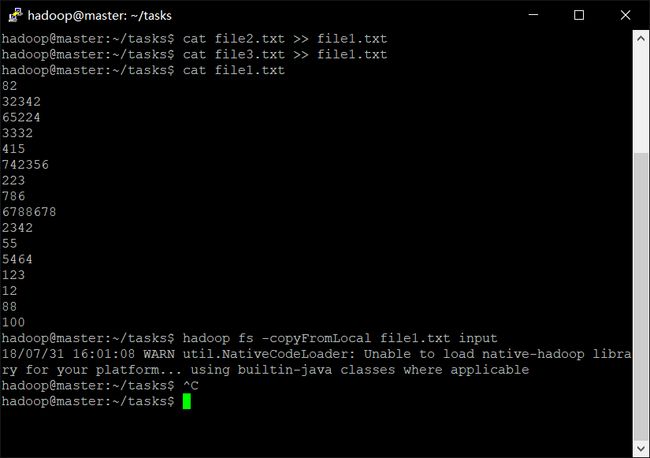
可看到在文件系统的/user/hadoop/input目录下出现了file1.txt
1.6.4 执行Hadoop/MapReduce
./bin/hadoop jar /home/hadoop/tasks/sort.jar sort.DataSort input output
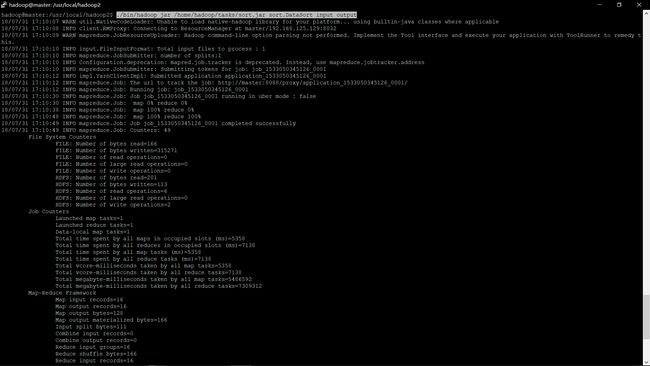
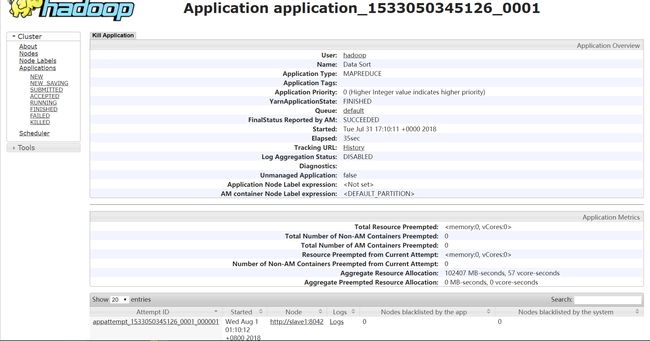
此时的资源管理界面为

该任务详情
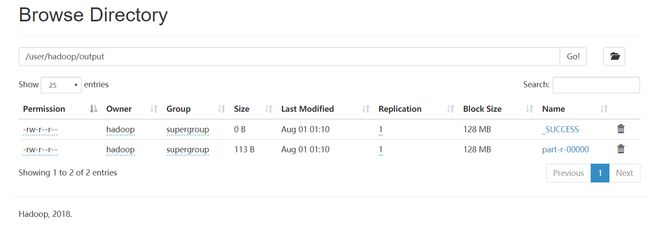
可在/user/hadoop/output文件夹中查看到输出结果
点击
Download即可启动下载输出结果
1.7 输出结果
1 12
2 55
3 82
4 88
5 100
6 123
7 223
8 415
9 786
10 2342
11 3332
12 5464
13 32342
14 65224
15 742356
16 6788678
1.8 参考文档
https://blog.csdn.net/garychenqin/article/details/48223057
示例二:网站统计
2.1 任务描述
1.统计所有IP对网站的有效浏览数平均数:有效浏览数=浏览数+直接访问访问数+间接访问数-闪退数
2.统计每个IP最大有效收藏数
2.2 输入样例
ip编号 浏览数 收藏数 直接访问数 间接访问数 闪退数
ip1 3412344 2424 110 111 990
ip2 12332 25 12 456 230
ip2 535 33 10 3 61
ip1 23424 225 34 5 80
ip5 5677 2 9 76 90
ip6 113 768 435 89 120
ip4 63 133 34 23 21
ip3 5 2 89 56 10
ip3 111115 22 56 67 50
ip6 111 5 67 12 70
ip8 17 3 0 12 71
ip9 3455 0 1 81 90
2.3 代码实现
2.3.1 File:FlowBean.java
package statistics;
import java.io.IOException;
import java.io.DataInput;
import java.io.DataOutput;
import org.apache.hadoop.io.Writable;
public class FlowBean implements Writable {
private String ipNum;
private long aveValidVisitNum;
private long sumValidLikeNum;
// 在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean() {
}
// 为了对象数据的初始化方便,加入一个带参的构造函数
public FlowBean(String ipNum, long aveValidVisitNum, long sumValidLikeNum) {
this.ipNum = ipNum;
this.aveValidVisitNum = aveValidVisitNum;
this.sumValidLikeNum = sumValidLikeNum;
}
// 将对象的数据序列化到流中
public void write(DataOutput out) throws IOException {
out.writeUTF(ipNum);
out.writeLong(aveValidVisitNum);
out.writeLong(sumValidLikeNum);
}
//从流中反序列化对象的数据
//从数据流中读出对象字段时,必须跟序列化的顺序保持一致
public void readFields(DataInput in) throws IOException {
this.ipNum = in.readUTF();
this.aveValidVisitNum = in.readLong();
this.sumValidLikeNum = in.readLong();
}
public String getIPNum() {
return ipNum;
}
public void setIPNum(String ipNum) {
this.ipNum = ipNum;
}
public long getValidVisitNum() {
return aveValidVisitNum;
}
public void setValidVisitNum(long validVisitNum) {
this.aveValidVisitNum = validVisitNum;
}
public long getValidLikeNum() {
return sumValidLikeNum;
}
public void setValidLikeNum(long validLikeNum) {
this.sumValidLikeNum = validLikeNum;
}
public String toString() {
return "" + aveValidVisitNum + "\t" + sumValidLikeNum;
}
}
2.3.2 File:website.java
package statistics;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class website {
FlowBean flowBean = new FlowBean();
public static class Map extends Mapper {
//实现Map函数
protected void map(LongWritable key, Text value,
Mapper.Context context)
throws IOException, InterruptedException {
//将输入的纯文本文件的数据转化成String
String line = value.toString();
//将输入的数据首先按行进行分割
StringTokenizer tokenizerArticle = new StringTokenizer(line, "\n");
//分别对每行进行处理
while (tokenizerArticle.hasMoreElements()) {
//每行按空格划分
StringTokenizer tokenizerLine = new StringTokenizer(tokenizerArticle.nextToken());
String strIPNum = tokenizerLine.nextToken(); //ip地址部分
String strBrowseNum = tokenizerLine.nextToken(); //浏览数
String strLikeNum = tokenizerLine.nextToken(); //收藏数
String strDirectVisitNum = tokenizerLine.nextToken(); //直接访问数
String strIndireVisitNum = tokenizerLine.nextToken(); //间接访问数
String strFlashNum = tokenizerLine.nextToken(); //闪退数
String ipNum = strIPNum;
Long validVisitNum = Long.parseLong(strBrowseNum)+Long.parseLong(strDirectVisitNum)+Long.parseLong(strIndireVisitNum)-Long.parseLong(strFlashNum);
Long likeNum = Long.parseLong(strLikeNum);
//封装数据并输出ip地址、有效访问数和收藏数
context.write(new Text(ipNum), new FlowBean(ipNum, validVisitNum, likeNum));
}
}
}
public static class Reduce extends Reducer {
//框架每传递一组数据调用一次reduce方法
//reduce中的业务逻辑就是遍历values,然后进行累加求和再输出
protected void reduce(Text key, Iterable values,
Reducer.Context context)
throws IOException, InterruptedException {
long max=0; //记录收藏数最大值
long sumValidVisitNum = 0;
long count = 0;
for (FlowBean value:values) {
sumValidVisitNum += value.getValidVisitNum();
max = max >= value.getValidLikeNum()? max:value.getValidLikeNum();
count++;
}
context.write(key, new FlowBean(key.toString(), sumValidVisitNum/count, max));
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "192.168.125.129:9000");
Job job = new Job(conf, "statistics");
job.setJarByClass(website.class);
//设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//设置输入和输出目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0:1);
}
}
2.4 Hadoop启动核心代码
cd /usr/local/hadoop2
./sbin/start-all.sh
cd ~
cd /home/hadoop/tasks
hadoop fs -copyFromLocal website.txt input
cd /usr/local/hadoop2
./bin/hadoop jar /home/hadoop/tasks/web.jar statistics.website input output/web_ouput
2.5 输出数据
ip1 1717479 2424
ip2 6528 33
ip3 55664 22
ip4 99 133
ip5 5672 2
ip6 318 768
ip8 -42 3
ip9 3447 0
2.6 参考文档
https://blog.csdn.net/xw_classmate/article/details/50639848