ACL2018为稀有语言翻译的三角结构
主要就是利用大语种之间的丰富语料去提升包含小语种(稀有数据)的机器翻译的性能。最终是解决低资源语言对的数据稀疏问题。
摘要
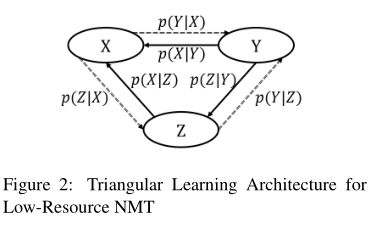
NMT在低资源语言对(X,Z)上表现很差尤其当Z是小语种语言。通过引入其他丰富语言Y,我们提出了一个三角结构(TA-NMT)去利用双语数据(Y,Z)(可能很小)和(X,Y)(可能很大)去提高低资源对的翻译质量。在这个三角架构中,将Z作为中间隐变量,并且在最大化(X,Y)的翻译似然的目标下,用统一的双向EM算法联合优化Z的翻译模型。
在训练期间,使用最大似然估计(MLE)方法优化NMT系统以最大化给定语言对的翻译概率,该方法需要大量双语数据以适合大型参数空间。如果没有足够的数据,这种情况很常见,特别是涉及一种罕见的语言时,NMT通常不能适合低资源语言对(Zoph等,2016)。
【因为神经机器翻译的模型参数量庞大,且训练方法为极大似然估计,所以需要大量的对齐语料,比如数百万个句对,才能得到一个比较理想的翻译模型。研究表明,如果对齐语料数量过少,如只有十几万个句对,那么神经机器翻译模型会在这个小数据集上产生比较严重的过拟合,从而导致其性能低于传统的统计机器翻译模型,这被称为神经机器翻译的数据稀疏性问题(Low-resource Problem)。这个问题普遍存在而且非常关键,尤其是在小语种(Rare Language)的翻译问题上。通常情况下,一个小语种和其他任意一种语言之间的双语数据常常是稀疏的,如果稀疏性问题不解决,将会严重影响神经机器翻译在小语种上的翻译应用。】
Introduction
为了解决NMT的数据稀疏性问题,充分利用容易获取的单语数据是最常用的方法。利用单语数据,back-translation方法以目标端到源端的翻译模型生成伪双语句子,以训练源端到目标端的翻译模型。通过扩展反向翻译,源端到目标端和目标端到源端翻译模型可以联合训练并且相互促进。类似于联合训练,双重学习设计了一个强化学习框架去更好的利用单语数据并联合训练两种模型。除了利用单语数据去丰富低资源双语对,在这篇文章中,我们提出了引入其他丰富语言------------->Z: 小语种; X,Y:大语种; (X,Z)(Y,Z):低资源数据对,因为Z是稀疏的; (X,Y):丰富数据对 目标:(X,Z)
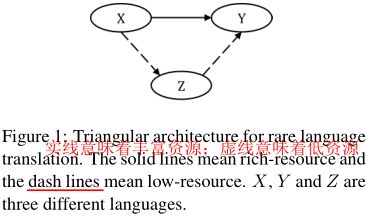
第一个翻译模型在从X到Z的隐藏空间生成一个序列,基于该序列第二个翻译模型在Y中生成翻译。这两个模型带有最大化翻译概率p(y|x)的目标可以被EM框架联合优化。在这个框架里,这两个模型可以通过生成用于模型训练的伪双语数据来相互促进,其中权重来自另一个。
贡献:提出一个新奇的三角结构:在NMT使用EM框架有效解决数据稀疏问题; 我们的方法可以通过引入另一种丰富的语言在模型和数据级别上利用另外两个双语数据集。 我们的方法是统一的双向EM算法,其中两个低资源对上的四个翻译模型被联合训练并相互提升。
2.Method
2.1EM 训练
为了最大化L(θ;D),EM算法可以被利用去最大化他的下界L(Q)。E步,我们使用模型的当前估计去计算变量z的期望,即求后验分布Q(z).。M步:我们最大化下界L(Q)
E步通过最小化L(Q)和L(θ;D)之间的代沟来优化模型p(z|x)去获得一个更好的下界L(Q). 这个下界然后去最大化M步去优化模型p(y|z)。给定新模型p(y|z),E步再次尝试去优化p(z|x)去找到一个更好的下界,再去重新到M步去优化。 这个迭代过程继续下去直到模型收敛,这是由EM算法的收敛保证的。
2.2统一的双向训练
在E-step优化上,模型p(z|y)被作为p(z|x,y)的一个近似。 p(z|x,y) ≈ p(z|y) 由于语言对(Y,Z)是低资源属性,p(z|y)不能被很好的训练。为了解决这个问题,我们可以通过最大化反向翻译概率p(x|y)同样的联合优化p(x|z)和p(z|y)
Direction of X ⇒ Y:在E步骤中,最小化KL项,使得从x到z和从y到z的结果尽可能一致; 在M步骤中,我们最大化优化下界L(Q),最大化从z到y得到的最终翻译期望,
X=>Y方向的训练中的p(z | x)和p(y | z)这两个模型是 在Y=>X方向的 p(z | y)的帮助下共同训练的,p(z | y)和p(x | z)是在p(z | x)的帮助下共同训练的。所以我们可以将两个方向结合起来,进行联合的迭代训练,从而可以同时优化四个小语种翻译模型。
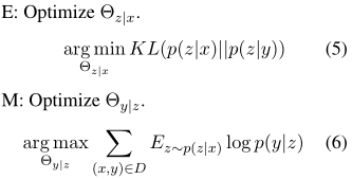
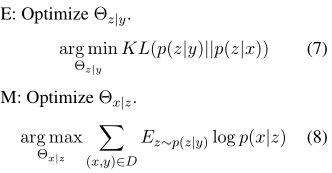
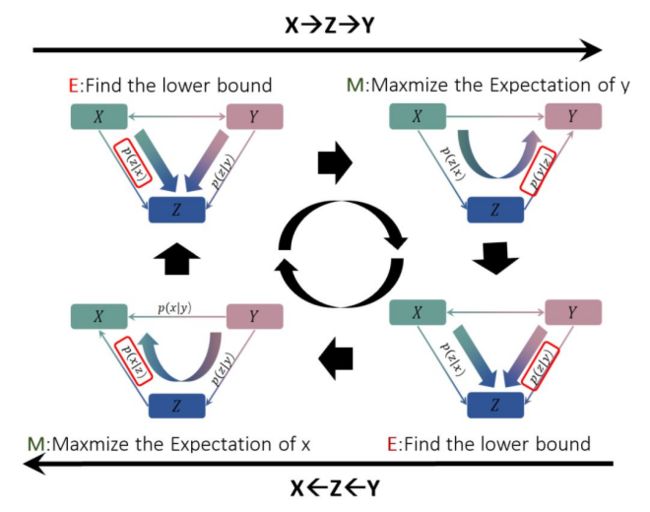
【其实原来论文的这个地方我没看懂,联合EM和单独的EM有什么区别????????? 解答:原来的EM算法是:E-step-》M-step-》E-step-》M-step往复循环下去直到模型参数收敛联合EM算法是:E-step=》M-step-》E2-step-》M2-step-》E-step-》M-step-》E2-step 是两个EM模型联合起来迭代训练】
2.3训练细节
一个主要的困难:翻译候选者的指数搜索空间,可以通过其他的采样和模型近似去解决。在我们的试验中,我们利用抽样方法,简单地生成顶部目标句子进行近似。
类似于强化学习,模型p(z | x)和p(z | y)使用模型本身生成的样本进行训练。根据我们的观察,一些样本是嘈杂的并且对训练过程有害。一个方法去处理这个问题就是利用一些其他的权值(BLEU)去过滤掉坏的这些。然而,在我们的设置中,由于缺少黄金目标(z是基于来自丰富资源对(x,y)的x或y生成),因此在训练期间无法计算BLEU分数。因此,我们选择IBM模型1分数来对生成的翻译候选进行加权,其中基于给定双语数据(低资源对(x,z)或(y,z))计算单词翻译概率。另外,为了稳定训练过程,由模型p(z | x)或p(z | y)生成的伪样本与真正的双语样本在相同的小批量中混合,其比例为1-1。整个训练过程如下
3.experience
3.1数据集
我们的方法与利用单语数据的方法兼容。因此,我们还在两个数据集中找到了一些额外的罕见语言的单语数据,并进行了将反向翻译纳入我们的方法的实验。
MultiUN: rich-resource pair: English-French (EN-FR) (X,Y ) rare language : Arabic (AR) Spanish (ES) (X,Z) and (Y,Z). 确保(X,Z)和(Y,Z)所选的数据在Z中没有重叠的。
IWSLT2012:rich-resource pair: English-French (EN-FR) (X,Y ) rare language : Hebrew (HE) Romanian (RO) (X,Z) and (Y,Z). (X,Z)和(Y,Z)中的Z是严重重叠的 ,单语数据Z是来自于web
3.2baselines
4个baseline模型,一个是经典的神经机器翻译模型RNNSearch,一个是Phrase-based统计机器翻译模型。还有个teacher student和back-translation两个模型。由于TA-NMT中没有用到Z端的单语数据,所以我们将TA-NMT方法进行了进一步扩展,将back-translation训练的模型作为TA-NMT的初始模型,在此基础上进行进一步联合EM训练,将这个方法称为为TA-NMT(GI)。其中GI表示good initialization
RNNSearch : seq2seq+attention在给定小规模双语数据上。经过训练的翻译模型也可用作我们后续训练过程的预训练模型。 PBSMT:基于短语的SMT,PBSMT在低资源语言对上表现很好,所以我们想比较他和我们的方法。 T-S teacher-student alike method: 我们将此方法视为第二个基线,因为如果我们将(X,Z)视为零,它也可以被视为利用(Y,Z)和(X,Y)来改善(X,Z)翻译的方法 ,当训练p(z | x)和p(x | z)时,资源对和p(x | y)作为teacher模型。 back-translation :利用反向的翻译模型,将目标语言端的单语数据翻译成源语言的数据,通过这一方法构造伪双语数据来训练正向的翻译模型。 teacher-student模型:零资源NMT的方法 (x,y)之间没有平行数据(x,z)和(z,y)之间有平行数据 让(z,y)去做一个teacher去指导训练p(y|x)模型。在这篇论文里面就是用的类似于T-S模型的方法,当训练p(z|x)和p(x|z)时,(x,z)作为零资源数据对,p(x|y)作为teacher模型 T-S就可以被视为利用(Y,Z)和(X,Y)去提高(x,z)翻译的方法。teacher模型去指导训练(x,z)这个student模型。通过teacher模型生成伪数据对(我觉得就是训练得到的这个student模型,它得到的z,去和x,组成(x,z)伪双语数据),去和真实数据对混合(这样就增加了稀疏数据的数量)。在训练p(z|y)和p(y|z)时也是一样的。
3.3overall results
可以看到,在没有引入Z端单语数据的情况下,TA-NMT的性能高于RNNSearch、PBSMT、T-S。但对比BackTrans就没有好很多。而对于引入了z端单语数据的TA-NMT(GI)的性能高于BackTrans。所以做了一个额外单语数据对翻译性能的影响的实验
3.4额外单语数据的影响
对比结果之后发现我们的的方法并不是很好、我们推断原因是我们在实验中使用的相对较少的单语数据Z。所以夸大了单语数据的规模,数据的利用率分别设成了0%,10%,30%,60%,100%。结果效果确实有改善。
3.5EM训练曲线
为了更好的说明我们方法的表现,我们打印了训练曲线, 验证了我们的观点 两个弱模型可以彼此改进在我们的EM框架里。比较TA-NMT,TA-NMT(GI)更加的稳定,因为模型在前一个反向翻译阶段可能已经适应了异构数据的混合分布。
3.6我们方法中的强化学习机制
5结论
提出了一个三角架构(TA-NMT)使用一个统一双向的EM框架有效的解决低资源翻译的问题。通过引入其他丰富的语言,我们的方法可以更好地利用额外的语言对来丰富原始的低资源对。在一样的数据层面上和RNN Search ;teach-student方法;back-translation相比,我们的方法获得了满意的提高在数据集上。请注意,我们的方法可以与利用单语数据的方法相结合,用于NMT低资源问题,例如反向翻译,并进行进一步的改进。