笔记:http://blog.csdn.net/linkin1005/article/details/39312735
参考:https://zhuanlan.zhihu.com/p/20432322
主要内容--无监督学习:
- K-means算法
- 混合高斯分布模型 MoG
- 求解MoG模型的EM算法
1. K-means算法
1.1 基本概念
是聚类算法的一种。聚类算法是指将一堆没有标签的数据自动划分成几类的方法,这个方法要保证同一类的数据有相似的特征。
K-Means算法的特点是类别的个数是人为给定的。
假设前提:数据之间的相似度可以使用欧氏距离度量,如果不能使用欧氏距离度量,要先把数据转换到能用欧氏距离度量,这一点很重要。
(注:可以使用欧氏距离度量的意思就是欧氏距离越小,两个数据相似度越高)

比如上图就是非欧几里得空间,同一类的点可能会距离很远,这时候就需要使用KNN和最短路径算法等工具实现非欧空间到欧氏空间转化。
K-Means算法有个很著名的解释,就是牧师-村民模型,其实就是K-means算法的过程:
“有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的居民,于是每个居民到离自己家最近的布道点去听课。
听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的居民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。
牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个居民又去了离自己最近的布道点……
就这样,牧师每个礼拜更新自己的位置,居民根据自己的情况选择布道点,最终稳定了下来。”
伪代码描述:

matlab代码:
clear;clc;close all;
G1 = randn(100,2).*1+10;
G2 = randn(100,2).*1;
G3 = randn(100,2).*1-10;
X = [G1;G2;G3];
k = 3; %给出参数:聚三类
cls = kmeans(X,k);
figure(1)
subplot(1,2,2)
Legends = {'r.','b.','g.'};
hold on
for i = 1:3
plot(X(find(cls==i),1),X(find(cls==i),2),Legends{i})
end
hold off
title('聚类结果')
subplot(1,2,1)
plot(X(:,1),X(:,2),'.')
title('原始数据')

1.2 具体实现和改进
clear;clc;close all;
loli = imread('loli.jpg');
[x,y,channel] = size(loli);
loli_vec = reshape(loli,x*y,channel);
figure(1)
for i = 1:4
K=2^i;
[ ~,cls ] = k_means( double(loli_vec),[],K,[] );
centers = zeros(K,channel);
for k = 1:K
centers(k,:)=mean(loli_vec(find(cls==k),:));
end
centers = uint8(centers);
loli_vec_zip = centers(cls,:);
loli_zip = reshape(loli_vec_zip,x,y,channel);
subplot(1,4,i)
imshow(loli_zip)
imwrite(loli_zip,['loli_zip_' num2str(i) '.jpg'])
disp(['loli_zip_' num2str(i) '.jpg has saved.'])
end
function [ k_means_result,cls_vec ] = k_means( data_set,weight,K,plot2pos )
%% 说明的言叶
%{
data_set:输入的数据集,以行向量为单位
weight:输入的权重,如果是空就自动设为各个数据权值相等
K:K-Means的K还需要我明说么~,~
plot2pos:用来绘图的向量,大小N*2的矩阵,如果是空就不绘图了。(要不然超过三维怎么绘图)
%}
%% 初始化各项参数
[N,dim] = size(data_set);
if isempty(weight)
weight = ones(N,1);
else
weight = weight(:);
end
if isempty(plot2pos)
isdisplay = 0;
else
isdisplay = 1;
end
% 初始化点集
group_center = mean(data_set);
group_range = range(data_set);
centers = (randn(K,dim).*repmat(group_range,K,1)./3+repmat(group_center,K,1));
%各个变量的初始化
dist_vec = zeros(N,K);
rep_tms = 0;
delay = 1e-3;
dumper = 0.1;
p2pc = zeros(K,2);
%J = 0;
logJ = [];
minJ = -1;
%% 如果画图,为画图设置各项Legend(颜色)
if isdisplay == 1
Style = {'o'};
Color = {'r','g','b','m','k','c','y'};
Legends = {};
for i = 1:length(Style)
for j = 1:length(Color)
Legends = [Legends;[Style{i},Color{j}]];
end
end
end
%% 迭代过程
while(1)
for i = 1:K
%求到每一个中心的距离向量,且不用张量求更加节约空间
dist_vec(:,i) = sqrt(sum(...
(data_set - repmat(centers(i,:),N,1)).^2,2)...
);
end
%求出每一个点离哪一个中心更近。
[~,cls_vec] = min(dist_vec,[],2);
lst_cnt = centers;
for i = 1:K
%根据权重重新计算中心
cls_idx = find(cls_vec==i);
if isempty(cls_idx)
centers(i,:) = (randn(1,dim).*group_range./3+group_center);
else
centers(i,:) = sum(data_set(cls_idx,:).*...
repmat(weight(cls_idx),1,dim))...
./sum(weight(cls_idx));
end
end
% 计算代价函数
CMat = (data_set-lst_cnt(cls_vec,:)).^2;
J = sum(CMat(:));
% 根据阻尼比更新
centers = (1-dumper).*centers + dumper.*lst_cnt;
if minJ<0 || J=minJ
rep_tms = rep_tms+1;
else
rep_tms = 0;
end
if rep_tms>=5
break;
end
if isdisplay == 1
% 绘制代价函数及其差分
figure(2)
logJ = [logJ J]; %#ok
subplot(2,1,1)
plot(logJ)
axis tight
subplot(2,1,2)
plot(diff(logJ))
% 绘制分布图
figure(1)
cla
hold on
for i = 1:K
cls_idx = find(cls_vec==i);
if isempty(cls_idx)
p2pc(i,:) = mean(plot2pos);
else
p2pc(i,:) = sum(...
plot2pos(cls_idx,:).*...
repmat(weight(cls_idx),1,2)...
)...
./sum(weight(cls_idx));
end
plot(p2pc(i,1),p2pc(i,2),Legends{1+mod(i,length(Legends))});
scatter(plot2pos(cls_idx,1),plot2pos(cls_idx,2),...坐标
weight(cls_idx)./max(weight).*10,...大小
Color{1+mod(i,length(Color))},'filled');%颜色
end
hold off
pause(delay)
end
end
%% 输出数据集
not_empty_cls = unique(cls_vec);
k_means_result = cell(length(not_empty_cls),1);
for i = 1:length(not_empty_cls)
cls = not_empty_cls(i);
sub_res = cell(3,1);
cls_idx = find(cls_vec==cls);
sub_res{1} = centers(cls,:);
sub_res{3} = cls_idx;
sub_res{2} = data_set(cls_idx,:);
k_means_result{i} = sub_res;
end
end
算法的扩展参考:https://zhuanlan.zhihu.com/p/20445085
2. 混合高斯分布模型 MoG
一种无监督学习算法,常用于聚类。
适用于聚类问题中各个类别的尺寸不同、聚类间有相关关系的时候。
多维高斯(正态)分布概率密度函数PDF定义如下:

- 单高斯模型(Single GaussianModel, SGM)
实际就是以一个单一的高斯密度函数来描述这些数据点的概率密度函数。
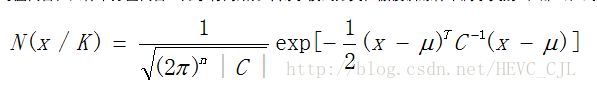
其中K表示类别,计算结果就是样本属于类别K的概率大小。从而将任意测试样本输入式子,均可以得到一个标量,然后根据阈值t来确定该样本是否属于该类别,阈值t可以为经验值,也可以通过实验确定。
- 高斯混合模型(GaussianMixture Model,GMM
为了解决的问题:
假设每个点均由一个单高斯分布生成(如图 1(b),具体参数,未知),而这一批数据共由M(明确)个单高斯模型生成,具体某个数据Xi属于哪个单高斯模型未知,且每个单高斯模型在混合模型中占的比例ai未知,将所有来自不同分布的数据点混在一起,该分布称为高斯混合分布。
从数学上讲,我们认为这些数据的概率分布密度函数可以通过加权函数表示:

其中Nj的值表示第j个SGM的PDF:

令

GMM共有M个SGM,现在,我们就需要通过样本集X来估计GMM的所有参数:
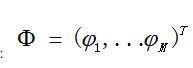
样本X的概率公式为:

对于GMM参数的估计我们就要用到EM算法。
3. EM算法(最大期望算法)
最大期望经常用在机器学习和计算机视觉的数据聚类(Data Clustering)领域。
适用于含有隐变量或潜在变量的概率模型参数的估计。如果只有观测变量而没有隐含变量,可以直接用极大似然估计参数。
为什么要用EM算法??

EM算法就是这样,假设我们估计知道A和B两个参数,在开始状态下二者都是未知的,并且知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。

