http://sylab-srv.cs.fiu.edu/lib/exe/fetch.php?media=paperclub:lkd3ch14.pdf
这里mark一些要点跟总结等。
Anatomy of a Block Device
- 快设备最小寻址单位是sector, 多数是512bytes
- kernel寻址单位block, 是sector大小的power-of-two倍数,不大于page size, 常见512B, 1KB, 4KB
- 机械硬盘的扇区这些概念是对特定block设备的属性,kernel在sector上抽象block
Buffers and Buffer Heads
- block在内存里变现为一个buffer
- 每个buffer有一个buffer head 对应这个buffer的信息(哪个device, block等)
struct buffer_head {
unsigned long b_state; /* buffer state flags */
struct buffer_head *b_this_page; /* list of page’s buffers */
struct page *b_page; /* associated page */
sector_t b_blocknr; /* starting block number */
size_t b_size; /* size of mapping */
char *b_data; /* pointer to data within the page */
struct block_device *b_bdev; /* associated block device */
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated mappings */
struct address_space *b_assoc_map; /* associated address space */
atomic_t b_count; /* use count */
};
The bio Structure
struct bio {
sector_t bi_sector; /* associated sector on disk */
struct bio *bi_next; /* list of requests */
struct block_device *bi_bdev; /* associated block device */
unsigned long bi_flags; /* status and command flags */
unsigned long bi_rw; /* read or write? */
unsigned short bi_vcnt; /* number of bio_vecs off */
unsigned short bi_idx; /* current index in bi_io_vec */
unsigned short bi_phys_segments; /* number of segments */
unsigned int bi_size; /* I/O count */
unsigned int bi_seg_front_size; /* size of first segment */
unsigned int bi_seg_back_size; /* size of last segment */
unsigned int bi_max_vecs; /* maximum bio_vecs possible */
unsigned int bi_comp_cpu; /* completion CPU */
atomic_t bi_cnt; /* usage counter */
struct bio_vec *bi_io_vec; /* bio_vec list */
bio_end_io_t *bi_end_io; /* I/O completion method */
void *bi_private; /* owner-private method */
bio_destructor_t *bi_destructor; /* destructor method */
struct bio_vec bi_inline_vecs[0]; /* inline bio vectors */
};
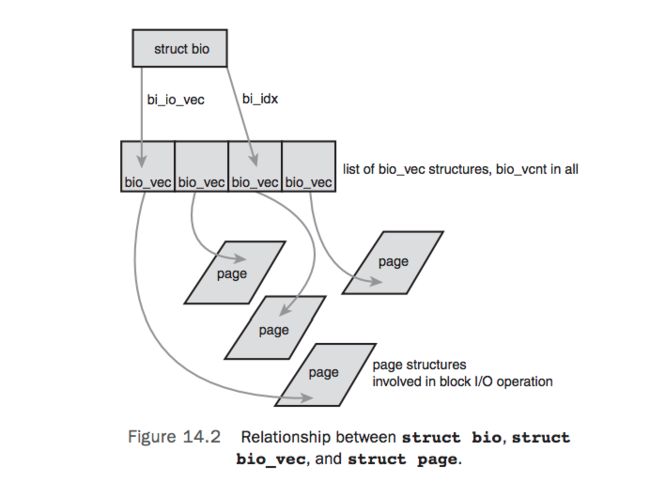
- bio 替代buffer_head表示一次io 操作,buffer只跟block对应
- The basic container for block I/O within the kernel is the bio structure。
The Old Versus the New
- bio 可以容易表示high memory, bio处理对应物理page,不是pointer
- 可以同时表示 normal page I/O 跟direct I/O
- 容易处理涉及多个物理页的操作
- 相比buffer head更轻量, 只包含一个block I/O操作需要的信息
buffer head的概念仍然需要,但只表示block到buffer的对应,bio表示in-flight I/O.
Request Queues
- 设备维护一个request queues存储pending的block I/O request, 有定义在
里的request_queue structure表示,包含一个请求的双向链表跟相关信息。 - request由高层的代码如文件系统添加。
- queue非空快设备驱动就从queue里队首获取request提交到对应块设备。
- 一个request由
里的struct request表示,可以包含多个bio, 因为一个request可以操作多个连续的disk blocks.
I/O Schedulers
如果kernel需要io request的时候就丢到queue的那么性能会很差(考虑磁盘seek操作)。所以kernel会有merging跟sorting的操作来提升性能,提供这些操作的子系统就叫做 I/O scheduler。
The Job of an I/O Scheduler
一个I/O scheduler管理块设备的request queue.它通过决定request被分发到块设备的顺序跟时间来提高整体的吞吐。
- merging
两个或多个request合并成一个。比如文件系统提交一个request,但queue里已经有一个request读取相邻的section,可以合并减少overhead&seed - sorting
没有相邻的request不能合并,但有相近的section请求可以调整顺序。比如把读第3个sector的放在读第1个sector的请求后面。(想下电梯调度)
The Linus Elevator
Linus Elevator 是第一个I/Oscheduler, 2.4默认,2.6后被其它替代。
Linus Elevator会执行merging和sorting操作,但添加一个request是,会在queue里检查每个request看有没相邻(前或后相邻)的request合并。
如果不能merging会找一个sectorwise的合适位置插入,不然插入的队列末尾。另外如果有request在队列里超过了一定时间也会把当前request放到队列而不是插入到合适位置,这个为了比较某个位置的大量请求饿死其它位置的请求。
总的说当添加一个request有4个操作按序可能:
- 队列里有相邻的request, 合并.
- 队列里有相当old的request.没处理了, 把新的插到队尾防止饿死其它更老的requests.
- 有合适的sector-wise位置在队列里插入到对应位置,让队列保持按磁盘物理顺序排序。
- 没合适位置,简单插到队尾。
The Deadline I/O Scheduler
Deadline I/O Scheduler用来解决Linux Elevator产生的饥饿问题。为了减少seeks的时间,大量同一区域的磁盘操作容易饿死距离较远的request, 这不公平。
更糟糕的是,上面的request 饥饿问题会产生write starving reads.写request当丢到队列就可以当提交了,对应用异步。读当应用提交request, 应用会block到reqeust处理完拿到数据。这样read lantency对上层应用很重要,虽然希望对于写 lantency也不能太大。
读请求更加趋向于互相依赖。例如读取大量文件,每个读在一个很小的buffered chunks。应用不会读取下个chunk(活着说下个文件),知道前一个chunk已经读取并返回到应用,更糟糕的是写也要读(文件系统读取元数据如inode)。读取这些block会串行化I/O。因此,每个读请求都饥饿的化对于应用操作的lantency会很大。Deadline I/O scheduler实现若干特性来确保读饥饿最小化。
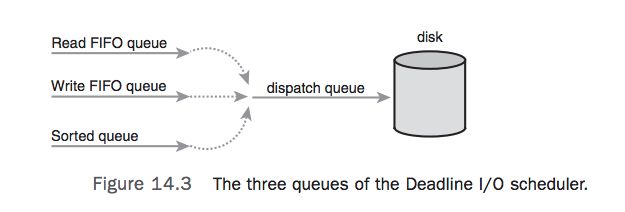
要知道减少读饥饿会带来全局吞吐下降的问题。Linux Elevator也是这样,Linux Elevator提供更好的吞吐(通过更大力度的减小 seeks)。Deadline I/O scheduler通过努力限制饥饿同时提供好的全局吞吐。
在Deadline I/O scheduler每个request会有一个超时时间。默认读500ms, 写5s。如图Deadline scheduler会维护一个类似the Linux Elevator的队列,这个队列按磁盘物理排序,同样会执行merging与sorting的操作。同时根据读或者写的类型插入对另一对应队列(FIFO, 即按时间排序)。Deadline scheduler从sorted queue垃取request到dispatch queue给磁盘驱动消费,这个最小化seeks次数时间。
当在read queue或write queue的request超时了的时候,Deadline scheduler 就从这些FIFO的队列拿取request而不是sorted queue。通过如此,Deadline scheduler尝试确保没有请求远大于它的超时时间。
所以不确保在超时时间内处理,但通过给读请求一个相当小的超时时间这可以防止write starve read, 读会提供更好的lantency。
The Anticipatory I/O Scheduler
The Complete Fair Queuing I/O Scheduler
CFQ类似the Linux Elevator,但是每个进程维护一个queue, 分别merge跟sort, round robin处理每个进程(默认每次获取4个request)。
为多媒体workload设计,但对于多数情景也很好。
(应该是2.6的默认scheduler)
The Noop I/O Scheduler
会做merging但不sorted,基本没什么操作,对于random-access的设备比较好。
Conclusion
- bio 表示 in-flight I/O
- buffer_head 表示一个block-to-page mapping
- request structure 表示一个特定的I/O请求。
request最后到scheduler处理调度,由driver处理。
一般来说 NOOP 调度器最适合于固态硬盘,DeadLine 调度器适用于写入较多的文件服务器,比如Web服务器,数据库应用等,而CFQ 调度器适合于桌面多任务及媒体应用。
看最新linux(4.12)代码下有的I/O scheduler
➜ linux git:(master) ✗ ll block/*iosched.c
-rw-r--r-- 1 huangjiahao staff 162K May 23 2017 block/bfq-iosched.c
-rw-r--r-- 1 huangjiahao staff 127K May 23 2017 block/cfq-iosched.c
-rw-r--r-- 1 huangjiahao staff 11K May 23 2017 block/deadline-iosched.c
-rw-r--r-- 1 huangjiahao staff 21K May 23 2017 block/kyber-iosched.c
-rw-r--r-- 1 huangjiahao staff 2.6K May 23 2017 block/noop-iosched.c
bfq跟kyber应该是4.12才加入的,参见:https://lwn.net/Articles/720675/
看完可能想看下当前硬盘上用什么调度器了
➜ ~ cat /sys/block/sda/queue/scheduler
noop deadline [cfq]
括号起来的cfq就是当前用的,当前有3种可以配置使用。