CPU的性能开销分为两大类:
- 引擎模块
- 游戏代码
其中, 引擎模块又可以细分为:
- 渲染模块 (Top1)
- UI模块 (Top2)
- 加载模块 (Top3)
- 动画模块
- 物理模块
- 粒子系统
- GC调用
一. 渲染模块
因为所有游戏都离不开场景, 物体和特效的渲染. 对于渲染模块的优化, 主要由两方面入手:
1. 降低Draw Call
什么是Draw Call? Batch?
要把GameObject画到屏幕上, 引擎模块会向显卡API(OpenGL或者Direct3D)发起一个绘图请求 -- Draw Call (下文简称DC). OpenGL的绘制流程是: 设置颜色 -> 绘图方式 -> 顶点坐标 -> 绘制 -> 结束. 每帧都会重复这个过程.
通常认为, DC越高, CPU开销越大. 具体原理看这里.
CPU会为每个DC创建一个数据包Batch, 可以把Batch想像成一个箱子, 里面装着物件的顶点资料, 由CPU送往GPU, GPU接手后, 将物件画出来.
Draw Call 的度量标准
nvidia在GDC上说, 25K Batchs/sec 会吃满1GHz的CPU. 你希望游戏跑30帧, 在2GHz的CPU上占用20%, 那么每帧可以跑多少DC呢, 333个.
333 Batchs/Frame = (25K * 2 * 0.2) / 30
怎么降低Draw Call?
首先, 降低DC的主要方法是减少材质球, 如果多个物体共用一个材质球(相同贴图和shader), 那么就可以合并到同一个DC里去(仅仅是Batch里传递的顶点坐标变成多个).
其次是通过Unity的Draw Call Batching技术来减少其数量, 分两种:
- Dynamic batching (动态合并)
如果Meshes(网格)比较小, 会在CPU上进行转换, 把相似的顶点合组, 然后一次画出来. - Static batching (静态合并)
把不会移动的GameObject合并到大Meshes里去, 然后渲染它们.
在Unity中如何使用这两种技术, Unity官方文档在这里.
Draw Call 越低越好吗?
但要注意, DC并非绝对的越小越好, 还有一个相关参数叫总线带宽. 降了渲染次数, 意味着每一次渲染的数据增加, 数据太大遇到带宽不足就会堵车(GPU要等待), 反而降低了游戏的运行帧率. 所以要用度量工具来观察数据, 找到一个平衡点.
2. 简化资源
大多数手机游戏中, 因为对美术规范的认识不足, 这些要渲染的资源其实是"过量"的, 过大的网格, 不合规的纹理资源等等. 简单的说, Res目录下的资源要被度量, 被规范.
3. 其它
使用LOD, Occlusion Culling和Culling Distance等优化技巧.
二. UI模块
1. NGUI 还是 UGUI
艺高人胆大的团队, 战斗界面用UGUI, 战斗以外的界面用NGUI.
我们现在只用UGUI.
2. UI首次渲染的开销
降低UI渲染的开销其实本质还是通过DC合并来降低DC, 在UI资源的制作和摆布上都要理解这些适用于UGUI的规则.
(1). 度量标准和工具
纯UI的DC控制目标: 40个(大概2ms的CPU耗时), 而度量工具有:
- Profiler: Window / Profile (⌘7) / Rendering
- Frame Debugger: Window / Frame Debugger
(2). DC合并规则-图标不能重叠
美术输出的图标都是矩形, 在引擎中也都是按矩形处理.
容易造成重叠的需求:
- 不规则图标的摆放 (比如moba的技能框)
- UI元素的旋转 (原来的边长, 变成了矩形框的对角线, 面积大大增加)
- 动态遮挡 (点击以后放大图标, 浮现起来)
-
3D UI
 image.png
image.png
并不是说这些需求不行, 而是需要主美理解这些规则, 设计的时候心中有数.
(3). DC合并规则-分层合并

第一张图, 一个组件有4个层(Index), 分别是蓝白红绿, 它们在各自的图集中(4个图集), 如果复制一份出来(小心别重叠), 同层数同图集, 那么还是只有4个DC, 因为触发了分层合并, 这是我们期望的.
第二张图, 把右边的组件加了一个黑色的层, 这时候DC会增加到9, 这是因为两边对应的层数不一样了, 无法进行分层合并, 这就是坑.
第三张图, 两边的的层数又一致了, DC数就为5.

而UGUI的这个"层数"是在hierarchy中体现的.
在Unity 5.x 的UGUI, 还有一个限制, "Z值"要同为0

红白分属两个图集, 左边的DC为2是期望的, 右边修改了Z值, 就无法分层合并, DC就会变成8, 不过这是UGUI的特性而不是bug, 它在3D UI是有意义的.

icon打在一个图集里, 红点打在一个图集里, 这样是合理的, DC会合并为2, 但要注意如果红点太大与旁边的icon穿插重叠的话, DC一下就上去了. 如果在Hierarchy里像左图那样排布, 即使穿插了, 也会合并, 不过这这样摆布图标是有点反直觉的, 而且红点层配合icon层的位置对齐比较麻烦(可以写个脚本来算位置). 看取舍了, 你是想用传统直觉来排布图标就要小心穿插, 你想随意穿插, 就要在Hierarchy这样主动分层.
(4). Overdwaw
- 减少UI重叠
- 遮挡场景时, 关闭场景相机
- 不用Image检测事件
3. UI重建的开销
- 动静分离, 细分Canvas, 拆分UIPancel
如果UI动静不分, 都在1个DC中渲染出来, 在首次渲染的确很省, 但是因为有动的元素(经验条)始终在重建, 那么每次重建都会把那些静的元素连累一起重建, 增大开销.
降低更新频率
-
避免敏感操作
 image.png
image.png 优化选项
动态元素要少用Outline(描边), Tiled Sprite, 长文本
隐藏UI元素的方法, Scale = 0 或 Alpha Group = 0
三. 加载模块
目前加载模块的性能开销主要在场景切换, 分别为前一场景的场景卸载和下一场景的场景加载.
1. 场景卸载
- Destroy
引擎在切换场景时会收集未标识成"DontDestoryOnLoad"的GameObject及其Component, 然后进行Destroy. 同时, 代码中的OnDestory被触发执行, 这里的性能开销主要取决于OnDestroy回调函数中的代码逻辑.
- Resources.UnloadUnusedAssets
一般情况下, 场景切换过程中, 该API会被调用两次, 一次为引擎在切换场景时自动调用, 另一次则为用户手动调用(一般出现在场景加载后, 用户调用它来确保上一场景的资源被卸载干净). 在我们测评过的大量项目中, 该API的CPU开销主要集中在500ms~3000ms之间. 其耗时开销主要取决于场景中Asset和Object的数量, 数量越多, 则耗时越慢.
2. 场景加载
- 资源加载
资源加载几乎占据了整个加载过程的90%时间以上, 其加载效率主要取决于资源的加载方式(Resource.Load或AssetBundle加载), 加载量(纹理, 网格, 材质等资源数据的大小)和资源格式(纹理格式, 音频格式等)等等. 不同的加载方式, 不同的资源格式, 其加载效率可谓千差万别.
- Instantiate实例化
在场景加载过程中, 往往伴随着大量的Instantiate实例化操作, 比如UI界面实例化, 角色/怪物实例化, 场景建筑实例化等等. 在Instantiate实例化时, 引擎底层会查看其相关的资源是否已经被加载. 如果没有, 则会先加载其相关资源, 再进行实例化, 这其实是大家遇到的大多数"Instantiate耗时"的根本原因, 这也是为什么我们在之前的AssetBundle文章中所提倡的资源依赖关系打包并进行预加载, 从而来缓解Instantiate实例化时的压力.
另一方面, Instantiate实例化的性能开销还体现在脚本代码的序列化上, 如果脚本中需要序列化的信息很多, 则Instantiate实例化时的时间亦会很长.
四. 代码效率
逻辑代码在一个较为复杂的游戏项目中往往占据较大的性能开销. 这种情况在MOBA, ARPG, MMORPG等游戏类型中非常常见.
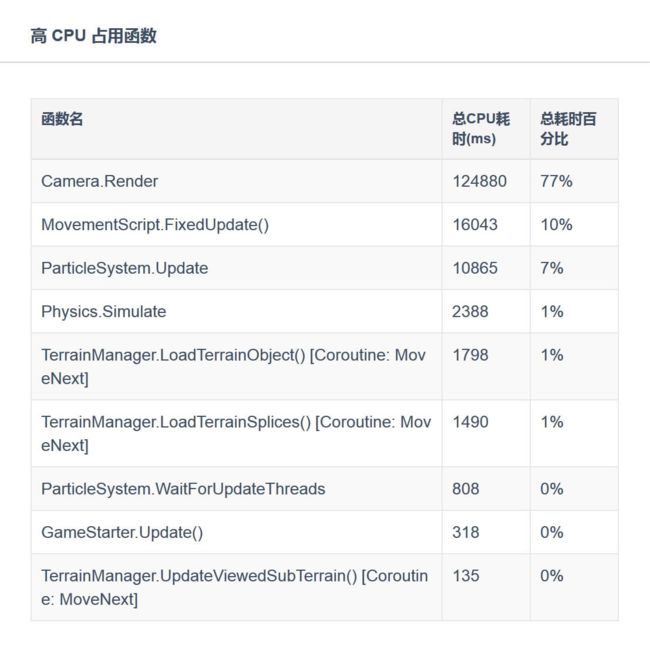
高CPU占用函数
引用
性能优化,永无止境---CPU篇
https://blog.uwa4d.com/archives/optimzation_cpu.html
UWA 六月直播季 | 6.29 Unity UI模块中的优化案例精讲
https://blog.uwa4d.com/archives/1875.html
每天一点UWA:第一周
http://caihua.tech/2017/07/29/%E6%AF%8F%E5%A4%A9%E4%B8%80%E7%82%B9UWA-%E7%AC%AC%E4%B8%80%E5%91%A8/