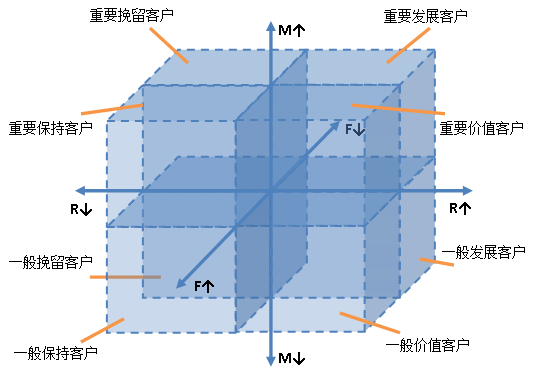
RFM是什么
在CRM系统中经常要对用户进行划分,以标记不同的标签,进行个性化的营销触达动作。通常的用户群体划分会使用用户的一些属性信息,例如年龄,职业,性别等。但是这些属性基本上都是用户本身的特征属性,并不是和品牌关联产生的属性信息。另外一种常用的用户模型,就是RFM模型,是以用户的实际购买行为数据作为基础,进行用户群体的划分的,在实践中更加具有实际价值。
RFM模型由三个指标组成,分别为:
最近一次消费 (Recency)
消费频率 (Frequency)
消费金额 (Monetary)
可以看到这三个属性都是通过用户的购买行为计算得出的,这些指标基本上代表了用户是否活跃,购买能力,忠诚度等信息。
而我们的目标是通过对每个用户的RFM属性进行计算,将用户群体划分为不同的种类进行区分,以便我们进行分析和精准营销。例如我们可以分析出高价值用户,重点发展用户,流失用户等群体进行针对性营销动作。
本文将使用Python的一些工具包,对用户数据集进行分析处理,例如建立RFM模型,数据标准化,以及使用k-means聚类算法将用户群体进行划分。需要读者具有一些基础的Python和数据统计知识。
通过数据建立RFM模型
首先我们通过一些订单数据分析得到一部分用户的样本数据来:
user_id,total_order_count,total_order_price,last_order_date
161526959,1,11878,2017-07-13 19:22:43.0
38972904,1,20735,2017-08-11 00:51:06.0
136664518,1,12680,2017-02-26 10:48:20.0
3921846,3,24722,2017-08-17 23:31:49.0
103291929,6,218720,2018-02-12 14:17:54.0
71742617,1,8919,2018-01-10 00:57:43.0
15114544,1,2935,2017-02-17 15:57:25.0
......
这里包括了用户的id,总购买笔数,总购买金额以及最后一笔订单时间的信息。我们将文件加载进来,截取一部分后对字段类型进行处理:
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
df = pd.read_csv('./membersData.csv')
df = df.drop(df.index[5000:])
df['last_order_date'] = pd.to_datetime(df['last_order_date'])
为了将其转化为我们要使用的RFM属性,我们需要对last_order_date进行处理,转换为最后一次订单时间到目前的天数。这样我们就获得了RFM的基本属性,分别为last_order_day_from_now(R), total_order_count(F), total_order_price(M)。处理完成后对数据进行可视化观察数据分布:
df['last_order_day_from_now'] = (pd.to_datetime('today') \
- df['last_order_date']).dt.days
df.plot.scatter(x='last_order_day_from_now',
y='total_order_count',
c='total_order_price',
cmap='viridis_r', s=50);
其散点图为:
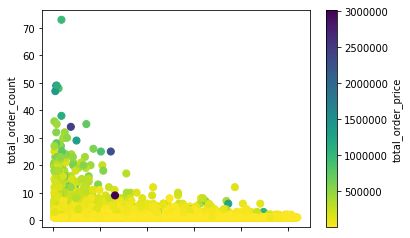
我们会发现实际上的数据大部分都聚集在了一起,并且有一些非常离散的极端值数据,这对我们后续进行数据聚类会产生不利影响,所以我们使用log函数对数据进行处理,让其分布的更加均匀:
df['total_order_count_log'] = np.log10(df['total_order_count'])
df['total_order_price_log'] = np.log10(df['total_order_price'])
df['last_order_day_from_now_log'] = np.log10(
df['last_order_day_from_now'])
df.plot.scatter(x='last_order_day_from_now_log',
y='total_order_count_log',
c='total_order_price_log',
cmap='viridis_r', s=50);
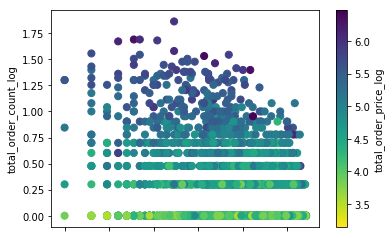
可以看到现在数据分布的已经比较均匀了,这为我们进行聚类打下一个比较好的基础。但同时我们也会发现RFM这三个属性的单位却并不相同,分别是天数,交易笔数和交易金额。这就造成了其数值差别巨大。而聚类算法一般都是使用不同向量间的距离进行计算划分的,属性单位不同造成的数值差异过大会造成计算距离时的权重分布不均衡,也并不能反映实际情况,所以我们还要对数据进行标准化处理,这里我们使用z-score对RFM属性进行加工运算。
z-score是一种数据标准化的计算方法,其公式为:
z = (x – μ) / σ
μ代表x所属数据组的平均值,σ代表x所属数据组的方差。所以通过z-score计算,我们将绝对值数据转化为一个数据在所属数据组中的位置(得分),这样不同单位和类型间的数据使用z-score做相互的比较也就有了一定的意义。
df['total_order_count_zscore'] = stats.zscore(df['total_order_count_log'])
df['total_order_price_zscore'] = stats.zscore(df['total_order_price_log'])
df['last_order_day_from_now_zscore'] = stats.zscore(
df['last_order_day_from_now_log'])
df.plot.scatter(x='last_order_day_from_now_zscore',
y='total_order_count_zscore',
c='total_order_price_zscore',
cmap='viridis_r', s=50);
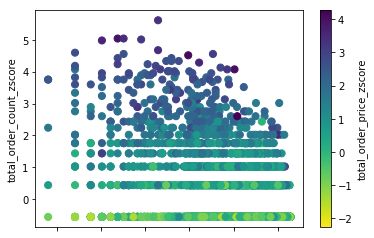
这时候会看到数据不但分布较为均匀,而且不同维度间的数值差异也很小了,这样我们可以把三种不同单位的属性一起进行处理。
基于RFM模型对用户数据进行分类
当我们建立好RFM的数据模型之后,期望通过不同的RFM值,对用户进行区分以进行精准化营销。当然我们可以通过对RFM这三组数值的平均值或者中位数和每个用户进行比较,以建立起一个数据立方,进行群体划分。但另外一方面,一般来说用户群体会大致符合28原则,80%左右的收入是由20%左右的客户所贡献的,所以根据平均值或者中位数进行群体划分也并不能总是科学的反应出不同的用户群体来,所以我们也可以基于数据本身的特性,使用聚类算法进行处理,以便让数据更加“自然”的区分。
这里我们选用非常常用的k-means算法进行聚类计算,k-means聚类的原理并不复杂,首先随机的或者通过更高效的方式(例如k-means++)选取k个点,然后不断迭代的计算,修正这k个点的坐标,目的是让集合中的每个点的距离(有很多种距离算法,比较常用的是欧氏距离)都和k个点里的其中一个尽量的近,而和其他的尽量的远。这样数据集合就能根据自身的分布规律,自然的区分出不同的类别来。
from sklearn.cluster import KMeans
sampleArray = df.iloc[:,8:].values
kmeans = KMeans(n_clusters=3, random_state=0).fit(sampleArray)
df.plot.scatter(x='last_order_day_from_now_zscore',
y='total_order_count_zscore',
c=kmeans.labels_,
cmap='viridis_r',
norm=None, s=50);
这里我们将k值设定为3,也就是将数据划分为三个部分,通过使用我们处理后的RFM属性进行计算,最终我们得到:
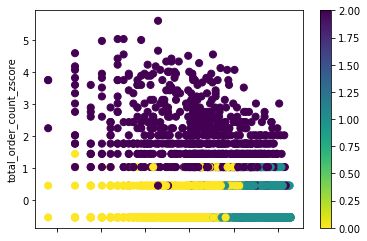
可以看到不同的颜色代表不同的用户类别,可以简单的认为标记为0的是流失用户,1是重点发展用户,2是高价值用户。这样我们就可以对不同的群体使用适合的营销策略了,同时当有新的用户加入后,我们也可以使用得到的k-means模型对其进行预测划分。
可能遇到的问题
在使用这种方式做实际的数据处理时,可能因为数据分布的原因导致区分度并不是特别好,因为根据销售数据进行用户区分,并不是总能发现比较明显的区分“界限”,也就是不同群体间的边界其实是非常模糊和混杂的(从上面的最终分析图也可以看出这样的情况),所以从这个角度讲,单纯通过RFM模型和聚类进行用户群体划分也是有它的局限性的。