该文章为本系列的第二篇
第一篇为 : Java POI操作Excel(User Model)
第三篇为 : Java POI操作Excel(Event User Model)
第四篇为 : 使用POI封装一个轻量级Excel解析框架
前言
在上一篇文章中,我们不仅对POI有了基本的认识,也学会了使用POI的User model(Dom)的方式进行Excel解析.
但是这种方式在进行大数据量Excel解析的时候,要一次性的解析完整个Excel.而在我们的系统中,是存在多个用户同时上传的情况,这种情况对内存的压力是很大的.轻则Full GC.严重的话甚至会OOM.
所以,POI还提供了抽象程度相比User Model更低,但是也更节约内存的方式来解析Excel.也就是今天要整理的Event Model(Sax)的方式.
xls & xlsx的存储形式
xls采用的是一种名为BIFF8(BinaryInterchangeFileFormat)的文件格式.而xlsx则是采用OOXML(Office open Xml)的格式存储数据.
xls格式Excel的数据组织由于使用的是二进制,没找到太直观的方式展示.故不做特殊说明(实际上是没搞明白怎么看)
xlsx格式Excel则采用Xml来组织数据.所以我们可以很轻易的看到.如下图:

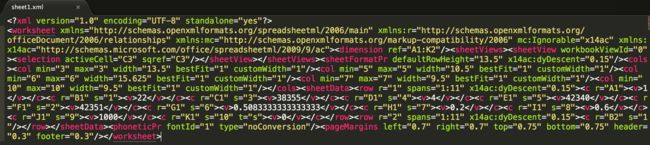
上面的xml只是sheet1对应的xml.而sheet2则对应另一个xml.
Event Model节约内存原理
User Model的缺点是一次性将文件读入内存,构建一颗Dom树.并且在POI对Excel的抽象中,每一行,每一个单元格都是一个对象.当文件大,数据量多的时候对内存的占用可想而知.
Event Model使用的方式是边读取边解析,并且不会将这些数据封装成Row,Cell这样的对象.而都只是普通的数字或者是字符串.并且这些解析出来的对象是不需要一直驻留在内存中,而是解析完使用后就可以回收.
所以相比于User Model,Event Model更节省内存.效率也更高.但是作为代价,相比User Model功能更少.门槛也要高一些.
解析
关于解析代码,使用POI官网提供的代码.并做一些局部的修改来达到学习的目的.
http://poi.apache.org/spreadsheet/how-to.html
开发环境
Java版本 :1.8.0_40
Maven版本:3.3.9
POI版本 :3.15
解析xls
Excel内容如下图:

解析代码:
public class ReadExcel2003 implements HSSFListener {
private SSTRecord sstrec;
/**
* This method listens for incoming records and handles them as required.
*
* @param record The record that was found while reading.
*/
public void processRecord(Record record) {
switch (record.getSid()) {
// the BOFRecord can represent either the beginning of a sheet or the workbook
case BOFRecord.sid:
BOFRecord bof = (BOFRecord) record;
if (bof.getType() == bof.TYPE_WORKBOOK) {
System.out.println("Encountered workbook");
// assigned to the class level member
} else if (bof.getType() == bof.TYPE_WORKSHEET) {
System.out.println("Encountered sheet reference");
}
break;
case BoundSheetRecord.sid:
BoundSheetRecord bsr = (BoundSheetRecord) record;
System.out.println("New sheet named: " + bsr.getSheetname());
break;
case RowRecord.sid:
RowRecord rowrec = (RowRecord) record;
System.out.println("Row found, first column at "
+ rowrec.getFirstCol() + " last column at " + rowrec.getLastCol());
break;
case NumberRecord.sid:
NumberRecord numrec = (NumberRecord) record;
System.out.println("Cell found with value " + numrec.getValue()
+ " at row " + numrec.getRow() + " and column " + numrec.getColumn());
break;
// SSTRecords store a array of unique strings used in Excel.
case SSTRecord.sid:
sstrec = (SSTRecord) record;
for (int k = 0; k < sstrec.getNumUniqueStrings(); k++) {
System.out.println("String table value " + k + " = " + sstrec.getString(k));
}
break;
case LabelSSTRecord.sid:
LabelSSTRecord lrec = (LabelSSTRecord) record;
System.out.println("String cell found with value "
+ sstrec.getString(lrec.getSSTIndex()));
break;
}
}
/**
* Read an excel file and spit out what we find.
*
* @param args Expect one argument that is the file to read.
* @throws IOException When there is an error processing the file.
*/
public static void main(String[] args) throws IOException {
// create a new file input stream with the input file specified
// at the command line
FileInputStream fin = new FileInputStream("workbook05.xls");
// create a new org.apache.poi.poifs.filesystem.Filesystem
POIFSFileSystem poifs = new POIFSFileSystem(fin);
// get the Workbook (excel part) stream in a InputStream
InputStream din = poifs.createDocumentInputStream("Workbook");
// construct out HSSFRequest object
HSSFRequest req = new HSSFRequest();
// lazy listen for ALL records with the listener shown above
req.addListenerForAllRecords(new ReadExcel2003());
// create our event factory
HSSFEventFactory factory = new HSSFEventFactory();
// process our events based on the document input stream
factory.processEvents(req, din);
// once all the events are processed close our file input stream
fin.close();
// and our document input stream (don't want to leak these!)
din.close();
System.out.println("done.");
}
}
输出
Encountered workbook
New sheet named: sheet01
String table value 0 = This is a String
Encountered sheet reference
Row found, first column at 0 last column at 5
Row found, first column at 0 last column at 5
Row found, first column at 0 last column at 5
Cell found with value 1.0 at row 0 and column 0
Cell found with value 42932.0 at row 0 and column 1
String cell found with value This is a String
Cell found with value 42932.0 at row 0 and column 3
Cell found with value 2.0 at row 1 and column 1
Cell found with value 42932.0 at row 1 and column 2
String cell found with value This is a String
Cell found with value 42932.0 at row 1 and column 4
Cell found with value 3.0 at row 2 and column 2
Cell found with value 42932.0 at row 2 and column 3
String cell found with value This is a String
done.
我们实现了HSSFListener接口的processRecord方法来自定义了当我们遇到不同Record之后的操作.
现在我们的需求就是Event Model要像User Model那种解析出指定Sheet,指定Row,指定Cell的数据.
我们先来对代码一下小观察:
- 只能一次性的解析所有的sheet数据.不能分页解析.(这个功能在Dom解析的时候是有的)
- 解析Row中数据的时候,并不会解析空Cell
- 先解析了所有的Row,然后才解析了Cell.而不是Row,Cell的嵌套关系.
- 但是我们可以获取到Cell对应的行号.
通过上面的分析,我们就具备了满足前面所说需求的能力.
具体来说,换页的时候,Cell对应的行号会变成0.我们可以通过这个方案,来判断到了第几个Sheet.
关于指定的Row数据,我们可以根据判断Cell的行号来判断是否需要解析.
而具体的Cell数据,我们可以在一开始传入列数.将每一行的数据解析成一个指定大小的List.并且用空字符串填满这个List.在解析过程中,使用Cell的列号去覆盖List指定位置的值,这样.最终的List中就有这一行中包括空值的数据.想要第一列就获取第几列即可.
解析xlsx
excel的话,我们仍旧使用上面的,仅仅把格式转换为xlsx.
关于代码我们依旧使用官网的demo代码.
解析代码:
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.xml.sax.*;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
import java.io.InputStream;
import java.util.Iterator;
public class ReadExcel2007 extends DefaultHandler{
public void processOneSheet(String filename) throws Exception {
OPCPackage pkg = OPCPackage.open(filename);
XSSFReader r = new XSSFReader( pkg );
SharedStringsTable sst = r.getSharedStringsTable();
XMLReader parser = fetchSheetParser(sst);
// To look up the Sheet Name / Sheet Order / rID,
// you need to process the core Workbook stream.
// Normally it's of the form rId# or rSheet#
InputStream sheet1 = r.getSheet("rId1");
InputSource sheetSource = new InputSource(sheet1);
parser.parse(sheetSource);
sheet1.close();
}
public void processAllSheets(String filename) throws Exception {
OPCPackage pkg = OPCPackage.open(filename);
XSSFReader r = new XSSFReader( pkg );
SharedStringsTable sst = r.getSharedStringsTable();
XMLReader parser = fetchSheetParser(sst);
Iterator sheets = r.getSheetsData();
while(sheets.hasNext()) {
System.out.println("\nProcessing new sheet:");
InputStream sheet = sheets.next();
InputSource sheetSource = new InputSource(sheet);
parser.parse(sheetSource);
sheet.close();
System.out.println("");
}
}
public XMLReader fetchSheetParser(SharedStringsTable sst) throws SAXException {
XMLReader parser =
XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser"
);
ContentHandler handler = new SheetHandler(sst);
parser.setContentHandler(handler);
return parser;
}
/**
* See org.xml.sax.helpers.DefaultHandler javadocs
*/
private static class SheetHandler extends DefaultHandler {
private SharedStringsTable sst;
private String lastContents;
private boolean nextIsString;
private SheetHandler(SharedStringsTable sst) {
this.sst = sst;
}
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
// c => cell
if(name.equals("c")) {
// Print the cell reference
System.out.print(attributes.getValue("r") + " - ");
// Figure out if the value is an index in the SST
String cellType = attributes.getValue("t");
if(cellType != null && cellType.equals("s")) {
nextIsString = true;
} else {
nextIsString = false;
}
}
// Clear contents cache
lastContents = "";
}
public void endElement(String uri, String localName, String name)
throws SAXException {
// Process the last contents as required.
// Do now, as characters() may be called more than once
if(nextIsString) {
int idx = Integer.parseInt(lastContents);
lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString();
nextIsString = false;
}
// v => contents of a cell
// Output after we've seen the string contents
if(name.equals("v")) {
System.out.println(lastContents);
}
}
public void characters(char[] ch, int start, int length)
throws SAXException {
lastContents += new String(ch, start, length);
}
}
public static void main(String[] args) throws Exception {
ReadExcel2007 example = new ReadExcel2007();
example.processOneSheet("workbook07.xlsx");
example.processAllSheets("workbook07.xlsx");
}
输出结果
A1 - 1
B1 - 42932
C1 - This is a String
D1 - 42932
C2 - D3 -
Processing new sheet:
A1 - 1
B1 - 42932
C1 - This is a String
D1 - 42932
C2 - D3 -
Processing new sheet:
A1 - 111
学过xml解析的肯定不会陌生,这段代码完全就是解析Xml的Sax解析代码.如果你只看到了官网的这段demo代码,你一定是一脸懵逼的.你并不知道xml的格式.而我已经在前面为你提供了xml的格式,相信你就不会因此而迷茫了.
几点说明:
- xlsx的Event Model是可以指定sheet来解析的.并且是以1为第一个sheet.
- 如果单元格里没有值,则不会有v标签.在真正解析的时候要考虑到这个因素.
- 在做User Model的时候也说过,Excel中使用SST来存储字符串常量.所以无论是Xls,Xlsx都有SST.具体的单元格的真是存储实际是SST中的下标.
总结
本文介绍了使用Event Model解析两种格式Excel的Demo代码.官网中也没有对这些代码如何应用于生产提供具体的指导.所以在一开始学习和应用于项目中,都会遇到一些不可避免的问题.
但是在遇到的问题的时候,我们一定要记住,User Model也是基于Event Model.只不过是抽象层级更高.所以理论上的Event Model是可以实现所有User Model的功能.只不过需要我们做更多的思考和探索.但是我相信通过不停的思考与实践.没有问题是解决不掉的.
参考资料
The New Halloween Document