目录
- 序列化介绍
- 为什么需要更高效的序列化框架
- Flatbuffers介绍
- Flatbuffers使用
- 总结
序列化介绍
在App中,网络交互功能都是必备功能,你很难想象如今的一个App没有网络模块。
一旦我们客户端要与服务器端进行网络交互,那么我们就必须迎来一个严峻的问题:网络的传输都是基于二进制字节传输的,怎么才能将我们定义好的类、对象传输给服务器?
聪明的程序员先贤自然就约定发明了一种协议,既能够将数据结构或对象转换成二进制串,也能把在生成的二进制串转换成数据结构或者对象,这就是序列化和反序列化.
关于序列化协议有很多,比如XML、JSON、Protobuf、Thrift、Avro、CORBA等等,每种序列化协议都有各自的优缺点,这些优缺点源自于它们设计之初时面临的应用场景,总结下来说,评价一款序列化协议的优劣能从这么几个特点去看:
- 通用性(是否支持跨平台、跨语言,是否学习成本很低)
- 可调试性/可读性
- 性能(空间开销、时间开销)
- 可扩展性/兼容性
- 安全性/访问限制
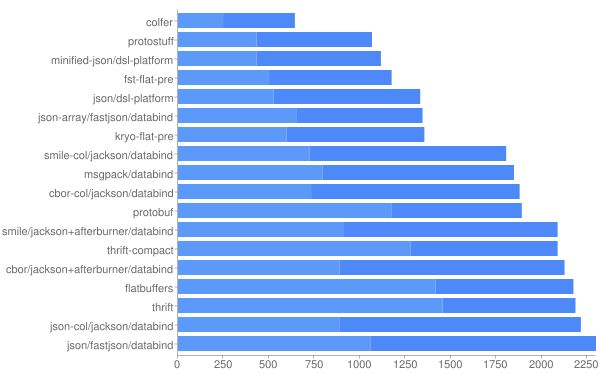
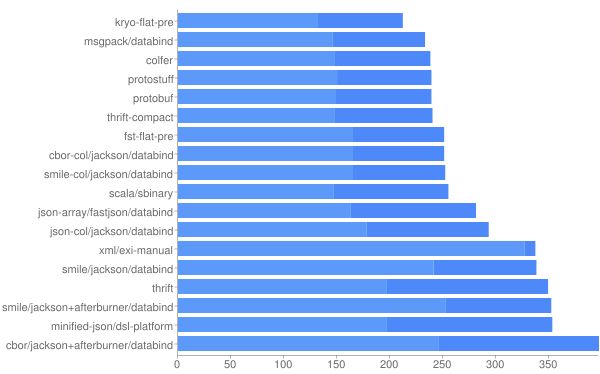
另外关于基于这些协议的框架的横向性能比较,我们可以看一下GitHub上名字叫jvm-serializers的一个文档,便于我们选择更适合自己项目的序列化方案。
** Ser Time+Deser Time (ns)**
Size, Compressed size [light] in bytes
为什么需要高效的序列化框架
很多人可能会问,我们用JSON或者XML用的好好的,为什么我们还要去换一些其他的序列化协议?
其实理由很简单,就是二个字:性能。
随着数据时代的来临,很多App都需要高频或者高量的向服务器端拉取或者传输数据,使用诸如XML/JSON之类的序列化协议,已经不能满足这些App对于性能的基本要求,比如在前年的时候,Facebook就发布了一篇文章,说明它们为什么要在安卓中采用FlatBuffers的理由,这里摘抄一段给大家看看。
在Facebook上,人们可以通过阅读状态更新和查看照片同他们的家人和朋友来往。在我们的后端,我们保存了组成这些连接的社交图谱的所有数据。在我们的移动客户端,我们不能下载完整的图谱,而是以一个本地的树结构的形式下载一个节点及它的一些连接。
下面的图片描述了在一个含有照片附件的story中这是如何工作的。在这个例子中,John创建了一个story,他的朋友们很喜欢它并加了评论。图片的左边是社交图谱,用来描述Facebook后端的人际关系。当Android app查询story时,我们获得一个以story开始的树结构,包含了参与者的信息,反馈,和附件(如图片的右边所展示的那样)。
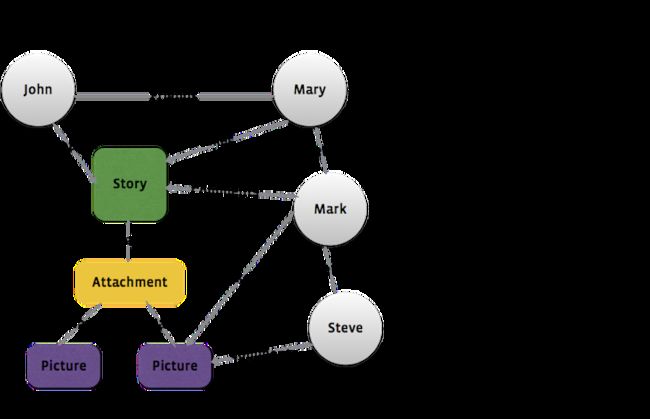
我们要处理的一个重要问题是如何在app中表示并存储数据。规格化所有这些数据为不同的表并放进SQLite数据库不太现实,因为我们查询节点并关联来自于后端的树结构的方式非常非常多,因此我们直接存储树结构。
一个解决方案是将树结构存储为JSON,但那将需要我们在它能够被用于UI展示之前先解析JSON,并转换为一个Java对象。而且,JSON解析耗费时间。我们过去常常在Android平台上使用Jackson JSON解析器,但我们发现了它的一些问题:
解析速度。它要耗费35 ms来解析一个20 KB(Facebook中一个典型的响应的大小)的JSON流,这超出了UI帧刷新的16.6 ms的间隔了。使用这种方法,我们无法在滚动时,按照需要及时地从磁盘缓存中加载stories而不出现丢帧(视觉上的抖动)。
解析初始化。一个JSON解析器在它可以开始解析之前,需要构建一个字段映射,这可能要耗费100 ms到200 ms,这大幅地降低了应用的启动时间。
垃圾回收。在JSON解析的过程中要创建大量的小对象,在我们的探索研究中发现,解析一个20 KB的JSON 流时,大概要分配 100 KB的瞬时内存,这将给Java的垃圾回收器带来巨大的压力。
Flatbuffers介绍
上面摘抄的一段内容足以说明JSON在面对App要求的高性能序列化解析上,显得有一些力不从心,毕竟它的解析流程非常繁琐:
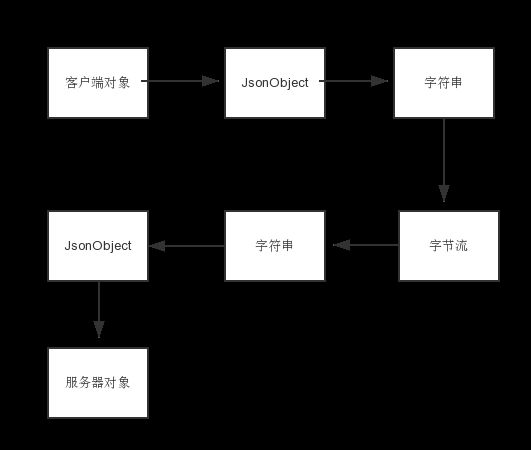
而这个时候Flatbuffers就应运而生了,它不同于JSON解析,需要多次把对象数据进行编组/解组,它通过二进制缓存直接获取里面的结构化数据,不需要解析,速度秒杀JSON,有图为证:
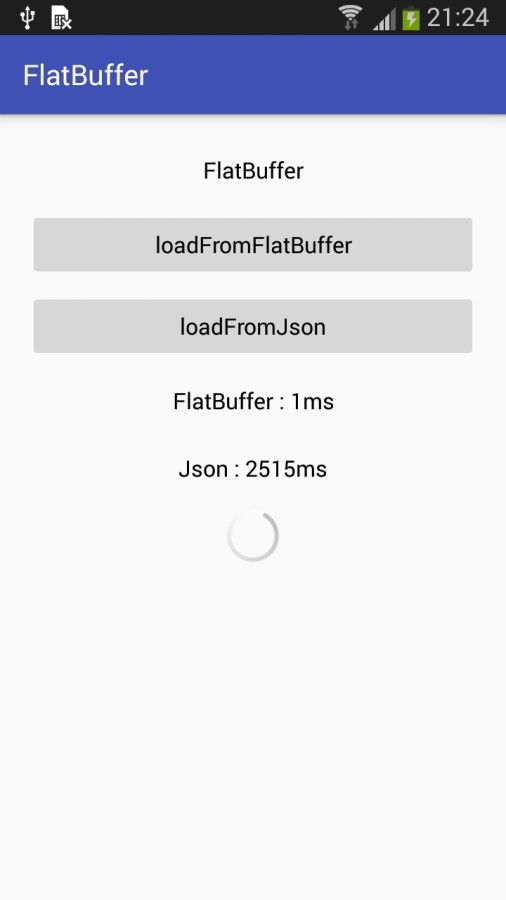

当然,除了速度快,FlatBuffers还有多个特点,这里总结如下:
不需要解析/拆包就可以访问序列化数据
内存高效速度快
灵活
强类型,编译时报错
Flatbuffers使用
了解了Flatbuffers的特点以后,我们来快速上手,使用一把Flatbuffers。
1.配置Flatbuffers环境
Flatbuffers的环境配置略显麻烦,特别是在Mac/Linux环境下,对于Mac下配置Flatbuffers环境,推荐看一下这篇文章。
2.编写schema文件
首先,我们需要将准备序列化的数据结构编写为一个schema文件,关于schema的语法,我们可以参照官网文档。
比如我们的数据结构是这样的
class Person {
String name;
int friendshipStatus;
Person spouse;
Listfriends;
}
那么,它的schema需要这样编写:
// Person schema
namespace com.race604.fbs;
enum FriendshipStatus: int {Friend = 1, NotFriend}
table Person {
name: string;
friendshipStatus: FriendshipStatus = Friend;
spouse: Person;
friends: [Person];
}
root_type Person;
3.生成java文件
将我们编写的scheme保存命名为person.fbs,然后执行flatc命令
flatc --java person.fbs
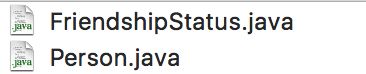
如果执行成功,可以看到在执行目录下生成一个包目录,里面有二个文件
4.在android中使用
首先,我们需要把下载的Flatbuffers中的java目录的文件拷贝到我们的工程,其实主要就是这四个文件:

然后将生成的java文件拷贝到我们的工程当中,就可以通过Flatbuffers进行操作序列化对象:
private ByteBuffer createPerson() {
FlatBufferBuilder builder = new FlatBufferBuilder(0);
int spouseName = builder.createString("Mary");
int spouse = Person.createPerson(builder, spouseName, FriendshipStatus.Friend, 0, 0);
int friendDave = Person.createPerson(builder, builder.createString("Dave"),
FriendshipStatus.Friend, 0, 0);
int friendTom = Person.createPerson(builder, builder.createString("Tom"),
FriendshipStatus.Friend, 0, 0);
int name = builder.createString("John");
int[] friendsArr = new int[]{ friendDave, friendTom };
int friends = Person.createFriendsVector(builder, friendsArr);
Person.startPerson(builder);
Person.addName(builder, name);
Person.addSpouse(builder, spouse);
Person.addFriends(builder, friends);
Person.addFriendshipStatus(builder, FriendshipStatus.NotFriend);
int john = Person.endPerson(builder);
builder.finish(john);
return builder.dataBuffer();
}
对于Flatbuffers的具体使用,个人还是推荐官网文档,写的非常详细。
总结
通过上面的文章,我们了解到Flatbuffers虽然性能上非常卓越,但与Json、Xml等序列化协议相比,可读性较差,构建scheme比较麻烦,从易用性上远远不如前二者,因此短时间内绝无可能代替这二个协议成为主流。
那么什么时候应该用到Flatbuffers呢?就是自己项目需要经常的进行序列化数据操作或者对性能要求达到吹毛求疵的地步,那么就需要Flatbuffers这一把利器了。