转自:http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy3/index.html
智能推荐大都基于海量数据的计算和处理,然而我们发现在海量数据上高效的运行协同过滤算法以及其他推荐策略这样高复杂的算法是有很大的挑战的,在面对解决这个问题的过程中,大家提出了很多减少计算量的方法,而聚类无疑是其中最优的选择之一。 聚类 (Clustering) 是一个数据挖掘的经典问题,它的目的是将数据分为多个簇 (Cluster),在同一个簇中的对象之间有较高的相似度,而不同簇的对象差别较大。聚类被广泛的应用于数据处理和统计分析领域。Apache Mahout 是 ASF(Apache Software Foundation) 的一个较新的开源项目,它源于 Lucene,构建在 Hadoop 之上,关注海量数据上的机器学习经典算法的高效实现。本文主要介绍如何基于 Apache Mahout 实现高效的聚类算法,从而实现更高效的数据处理和分析的应用。
聚类分析
什么是聚类分析?
聚类 (Clustering) 就是将数据对象分组成为多个类或者簇 (Cluster),它的目标是:在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。所以,在很多应用中,一个簇中的数据对象可以被作为一个整体来对待,从而减少计算量或者提高计算质量。
其实聚类是一个人们日常生活的常见行为,即所谓“物以类聚,人以群分”,核心的思想也就是聚类。人们总是不断地改进下意识中的聚类模式来学习如何区分各个事物和人。同时,聚类分析已经广泛的应用在许多应用中,包括模式识别,数据分析,图像处理以及市场研究。通过聚类,人们能意识到密集和稀疏的区域,发现全局的分布模式,以及数据属性之间的有趣的相互关系。
聚类同时也在 Web 应用中起到越来越重要的作用。最被广泛使用的既是对 Web 上的文档进行分类,组织信息的发布,给用户一个有效分类的内容浏览系统(门户网站),同时可以加入时间因素,进而发现各个类内容的信息发展,最近被大家关注的主题和话题,或者分析一段时间内人们对什么样的内容比较感兴趣,这些有趣的应用都得建立在聚类的基础之上。作为一个数据挖掘的功能,聚类分析能作为独立的工具来获得数据分布的情况,观察每个簇的特点,集中对特定的某些簇做进一步的分析,此外,聚类分析还可以作为其他算法的预处理步骤,简化计算量,提高分析效率,这也是我们在这里介绍聚类分析的目的。
不同的聚类问题
对于一个聚类问题,要挑选最适合最高效的算法必须对要解决的聚类问题本身进行剖析,下面我们就从几个侧面分析一下聚类问题的需求。
聚类结果是排他的还是可重叠的
为了很好理解这个问题,我们以一个例子进行分析,假设你的聚类问题需要得到二个簇:“喜欢詹姆斯卡梅隆电影的用户”和“不喜欢詹姆斯卡梅隆的用户”,这其实是一个排他的聚类问题,对于一个用户,他要么属于“喜欢”的簇,要么属于不喜欢的簇。但如果你的聚类问题是“喜欢詹姆斯卡梅隆电影的用户”和“喜欢里奥纳多电影的用户”,那么这个聚类问题就是一个可重叠的问题,一个用户他可以既喜欢詹姆斯卡梅隆又喜欢里奥纳多。
所以这个问题的核心是,对于一个元素,他是否可以属于聚类结果中的多个簇中,如果是,则是一个可重叠的聚类问题,如果否,那么是一个排他的聚类问题。
基于层次还是基于划分
其实大部分人想到的聚类问题都是“划分”问题,就是拿到一组对象,按照一定的原则将它们分成不同的组,这是典型的划分聚类问题。但除了基于划分的聚类,还有一种在日常生活中也很常见的类型,就是基于层次的聚类问题,它的聚类结果是将这些对象分等级,在顶层将对象进行大致的分组,随后每一组再被进一步的细分,也许所有路径最终都要到达一个单独实例,这是一种“自顶向下”的层次聚类解决方法,对应的,也有“自底向上”的。其实可以简单的理解,“自顶向下”就是一步步的细化分组,而“自底向上”就是一步步的归并分组。
簇数目固定的还是无限制的聚类
这个属性很好理解,就是你的聚类问题是在执行聚类算法前已经确定聚类的结果应该得到多少簇,还是根据数据本身的特征,由聚类算法选择合适的簇的数目。
基于距离还是基于概率分布模型
在本系列的第二篇介绍协同过滤的文章中,我们已经详细介绍了相似性和距离的概念。基于距离的聚类问题应该很好理解,就是将距离近的相似的对象聚在一起。相比起来,基于概率分布模型的,可能不太好理解,那么下面给个简单的例子。
一个概率分布模型可以理解是在 N 维空间的一组点的分布,而它们的分布往往符合一定的特征,比如组成一个特定的形状。基于概率分布模型的聚类问题,就是在一组对象中,找到能符合特定分布模型的点的集合,他们不一定是距离最近的或者最相似的,而是能完美的呈现出概率分布模型所描述的模型。
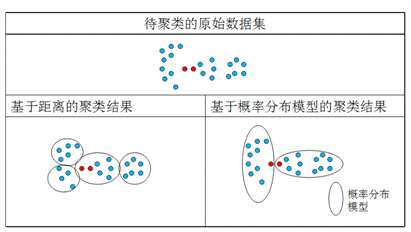
下面图 1 给出了一个例子,对同样一组点集,应用不同的聚类策略,得到完全不同的聚类结果。左侧给出的结果是基于距离的,核心的原则就是将距离近的点聚在一起,右侧给出的基于概率分布模型的聚类结果,这里采用的概率分布模型是一定弧度的椭圆。图中专门标出了两个红色的点,这两点的距离很近,在基于距离的聚类中,将他们聚在一个类中,但基于概率分布模型的聚类则将它们分在不同的类中,只是为了满足特定的概率分布模型(当然这里我特意举了一个比较极端的例子)。所以我们可以看出,在基于概率分布模型的聚类方法里,核心是模型的定义,不同的模型可能导致完全不同的聚类结果。
图 1 基于距离和基于概率分布模型的聚类问题