容器技术近年来越来越火,作为云原生技术的最底层基石,要开发云原生应用,就有必要对于容器技术有一个更加深入的了解。容器的概念特别多,docker、oci、cri、runc、containerd名字容易看晕,这边做一下总结
Container
首先先来了解一下,什么是容器?这边我们一般说的“容器”,都是“Linux容器”(当然现在微软也在搞容器,但还没linux上面那么成熟)。不同于一般认识,其实容器本身并不是一个特别新的技术,早在2000年就已经有了,当时是用来在chroot环境(隔离mount namespac的工具)中做进程隔离(使用namespac和cgroups),容器的历史可以看这篇文章。而现在docker所用的容器技术,和当时并没有本质上的区别。容器的本质,一句话解释,就是一组受到资源限制,彼此间相互隔离的进程。实现起来也并不复杂,隔离所用到的技术都是由linux内核本身提供的(所以说目前绝大部分的容器都是必须要跑在linux里面的)。其中namespace用来做访问隔离(每个容器进程都有自己独立的进程空间,看不到其他进程),cgroups用来做资源限制(cpu、内存、存储、网络的使用限制)。总的来说容器就是一种基于操作系统能力的隔离技术,这和基于hypervisor的虚拟化技术(能完整模拟出虚拟硬件和客户机操作系统)复杂度不可同日而语。这边是一个对比图
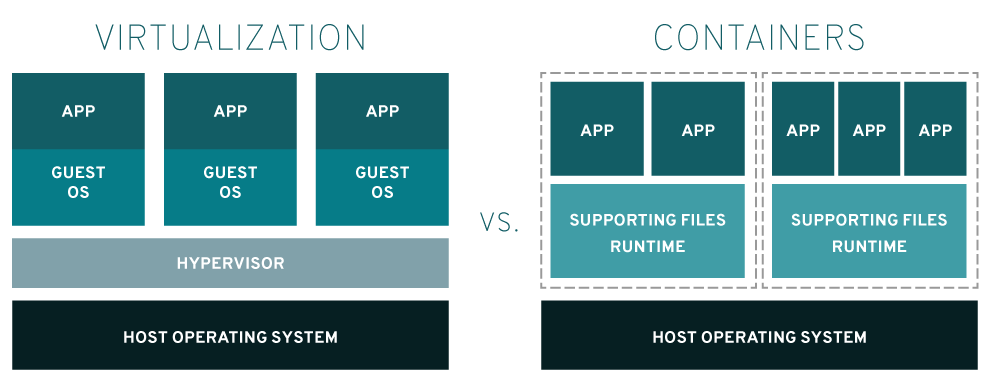
可以看出,容器是没有自己的OS的,直接共享宿主机的内核,也没有hypervisor这一层进行资源隔离和限制,所有对于容器进程的限制都是基于操作系统本身的能力来进行的,由此容器获得了一个很大的优势:轻量化,由于没有hypervisor这一层,也没有自己的操作系统,自然占用资源很小,而打出来的镜像文件也要比虚拟机小的多。对于虚拟机和容器的区别,刘超老师有一个很形象的比喻:虚拟机好比房子,容器好比衣服。衣服是跟着人的,人站起来了,衣服也跟着起来,人躺下了,衣服也躺下了,而房子永远在那里,不管人是躺着还是站着。所以说基于容器的技术原理,它天生对应用友好,轻量化,又具备了一定的隔离性,大火也就不奇怪了。
了解了容器的技术原理,接下来就可以说说容器的那些名词概念了
OCI
Open Container Initiative,是由多家公司共同成立的项目,并由linux基金会进行管理,致力于container runtime的标准的制定和runc的开发等工作。所谓container runtime,主要负责的是容器的生命周期的管理。oci的runtime spec标准中对于容器的状态描述,以及对于容器的创建、删除、查看等操作进行了定义。
runC
是对于OCI标准的一个参考实现,是一个可以用于创建和运行容器的CLI(command-line interface)工具。runc直接与容器所依赖的cgroup/linux kernel等进行交互,负责为容器配置cgroup/namespace等启动容器所需的环境,创建启动容器的相关进程。runC基本上就是一个命令行小工具,它可以不用通过Docker引擎,直接就可以创建容器。这是一个独立的二进制文件,使用OCI容器就可以运行它。
containerd
containerd 是一个守护进程,它可以使用runC管理容器,并使用gRPC暴露容器的其他功能。相比较Docker引擎,使用 gRPC ,containerd暴露出针对容器的增删改查的接口,Docker engine调用这些接口完成对于容器的操作。
Docker架构
docker在早期所有功能都是做在docker engine里面的,但是之后功能越来越多,越来越重,很多功能已经和基础的容器运行时没有关系了(比如swarm项目)。所以为了响应社区的呼声,也为了兼容oci标准,docker也做了架构调整。将容器运行时相关的程序从docker daemon剥离出来,形成了containerd。Containerd向docker提供运行容器的API,二者通过grpc进行交互。containerd最后会通过runc来实际运行容器。调整完后的docker架构图如下(docker 1.12版本以后):
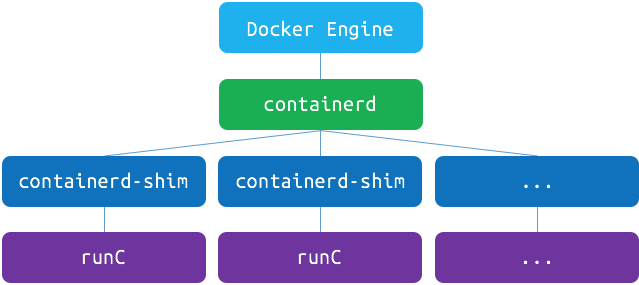
其中containerd-shim称之为垫片,它使用runC命令行工具完成容器的启动、停止以及容器运行状态的监控。containerd-shim进程由containerd进程拉起,并持续存在到容器实例进程退出为止(和容器进程同生命周期)。这种设计的优点是,只要是符合OCI规范的容器,都可以通过containerd-shim来进行调用(比如kata-runtime)
执行
ps -ef|grep docker,可以看到当前正在运行的docker进程
[root@localhost ~]# ps -ef|grep docker
root 1431 1 1 2018 ? 10:35:01 /usr/bin/dockerd --bip=10.1.100.1/24 --ip-masq=true --mtu=1472
root 1498 1431 0 2018 ? 01:23:31 docker-containerd -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --shim docker-containerd-shim --runtime docker-runc
root 1802 1431 0 2018 ? 00:00:03 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 4567 -container-ip 10.1.100.2 -container-port 4567
root 1820 1431 0 2018 ? 00:00:03 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 443 -container-ip 10.1.100.2 -container-port 443
root 1848 1498 0 2018 ? 00:00:07 docker-containerd-shim 2abb8ab1515e9dd491fc6e7d747e6ec8cdff3e98bcb6ae67c9b90ddfa120f1ed /var/run/docker/libcontainerd/2abb8ab1515e9dd491fc6e7d747e6ec8cdff3e98bcb6ae67c9b90ddfa120f1ed docker-runc
root 1852 1431 0 2018 ? 00:13:47 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 80 -container-ip 10.1.100.2 -container-port 80
root 1869 1431 0 2018 ? 00:00:03 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 10022 -container-ip 10.1.100.2 -container-port 22
root 1886 1498 0 2018 ? 01:24:27 docker-containerd-shim dd06d2cc632f45af1c53cd8df219c6275862bd94fed811bd3331290f8cf4a9a7 /var/run/docker/libcontainerd/dd06d2cc632f45af1c53cd8df219c6275862bd94fed811bd3331290f8cf4a9a7 docker-runc
root 15443 30672 0 13:08 pts/0 00:00:00 grep --color=auto docker
从上图可以看出,dockerd、docker-containerd、docker-containerd-shim分别对应上述架构图中的docker daemon、containerd、containerd-shim,在这边我启动了两个docker容器,所以会有两个docker-containerd-shim进程。docker-runc就是docker-containerd-shim调用的真正来创建容器的模块。
总结一下,其实docker总的架构来说,真正用来创建容器的就是runC,其他的都是一些容器的管理和增强功能,所以说你如果想创建一个容器玩一下,直接下载一个runC的二进制跑一下就行了,当然生产上面不能这么搞。
CRI
kubernetes在初期版本里,就对多个容器引擎做了兼容,因此可以使用docker、rkt对容器进行管理。以docker为例,kubelet中会启动一个docker manager,通过直接调用docker的api进行容器的创建等操作。
kubelet做适配的问题,就是容器项目每次升级更新,kubelet都需要相应的进行配合变更测试,很多api可能这一版能用,下一版就不能用了,由于容器项目一直在高速迭代,k8项目组苦不堪言。痛定思痛后,sig-node项目组在k8s 1.5版本之后,推出了自己的运行时接口api--CRI(container runtime interface)。cri接口的推出,隔离了各个容器引擎之间的差异,而通过统一的接口与各个容器引擎之间进行互动。
与oci不同,cri与kubernetes的概念更加贴合,并紧密绑定。cri不仅定义了容器的生命周期的管理,还引入了k8s中pod的概念,并定义了管理pod的生命周期。在kubernetes中,pod是由一组进行了资源限制的,在隔离环境中的容器组成。而这个隔离环境,称之为PodSandbox。在cri开始之初,主要是支持docker和rkt两种。其中kubelet是通过cri接口,调用docker-shim,并进一步调用docker api实现的。
如上文所述,docker独立出来了containerd。kubernetes也顺应潮流,孵化了cri-containerd项目,用以将containerd接入到cri的标准中。
CRI-O
为了进一步与oci进行兼容,kubernetes还孵化了cri-o,成为了架设在cri和oci之间的一座桥梁。通过这种方式,可以方便更多符合oci标准的容器运行时,接入kubernetes进行集成使用。可以预见到,通过cri-o,kubernetes在使用的兼容性和广泛性上将会得到进一步加强。
Kubernetes架构

看到这张图可能大家都晕了,其实这也反应了容器及容器编排技术高速发展的现状,K8的容器接入方案分别经历了四个阶段(从右往左):
1.最早是在kubelet这一层进行适配,通过启动docker-manager来访问docker(不同的容器产品有不同的manager,这部分代码是kubelet项目标准代码的一部分)
2.K8 1.5之后引入了CRI接口,通过docker-shim(垫片)的方式接入docker。shim程序一般由容器厂商根据CRI规范自己开发,实现方式可以自己定义(即CRI规范定义了要做什么,怎么做可以基于自己的理解)。而docker-shim由于历史原因,还是k8项目组来做的,这部分代码也包含在kubelet代码里面,但架构上是分开的。
3.docker在分出containerd后,k8也顺应潮流,孵化了cri-containerd项目,用于和containerd对接,这样就不走docker daemon了。
4.目前孵化的cri-o项目,则连containerd都绕过了,直接使用runC去创建容器(你可以把cri-o看作是k8生态里面的containerd)
值得注意的是,在containerd的1.1版本中,甚至已经去除了cri-containerd这样一个守护进程,cri接口以插件的形式直接整合在了containerd项目里面,目前docker和kubernetes分别调用containerd的架构图如下:

容器项目发展趋势
可以看到,随着k8生态的不断成熟和业界影响力的不断增大,k8项目对于docker的依赖已经越来越少,从cri-containerd开始就已经可以脱离docker体系,到cri-o更是连docker的影子都看不到了(containerd项目主要还是docker在维护)。而现在还有crictl这样的工具,连容器的日常维护都不需要使用docker命令了。Docker inc.基于自身的商业诉求,也是不断再往平台化发展(swarm项目),也在不断添加复杂的功能,可惜凭一己之力还是很难和谷歌一手搭建出来的CNCF的宏伟蓝图去抗争。
目前在CNCF里面有两个容器运行时项目,分别是rkt和containerd。rkt从目前的发展情况看很有可能被移出CNCF,cri-o和containerd都在同时发展,这两个项目其实重合度是比较高的,做的事情也差不多,只不过cri-o是专门为k8s设计的,而containerd设计之初的定义就是一个通用的容器运行时平台,有说containerd即将通过委员会评审,从CNCF中毕业。
安全容器
最后讨论一个比较前沿的话题,叫做“安全容器”。根据前面的介绍,相信你也了解了,容器有诸多好处,但也并不是完美的。它有个很大的软肋--隔离性。基于内核提供的namespace功能,其实很多东西还是无法隔离的,一个简单的例子就是时间,一旦在某个容器内修改了系统时间,所有运行在这个宿主机上的容器内的时间都会改变,这显然不符合“沙盒”原则。再比如容器里面的jvm,如果不修改内核代码的话,看到的都是宿主机的cpu和内存情况。而更加严重的问题是,由于共享宿主机内核,一旦某个容器被植入恶意代码,攻击宿主机内核,会影响到该宿主机上的所有容器。而这个问题在虚拟机时代是不存在的,因为虚拟机都是独立操作系统和内核,里面可以随便你折腾。目前所有的公有云,还都是使用虚拟机进行多租户管理,安全性是一个很重要的原因。
基于上述情况,很容易就能想到,是否有一种技术,既可以拥有容器的速度,还可以拥有虚拟机的隔离性呢?你别说,还真有人在研究这个,而且已经有了几个有一定成熟度的项目,比如kata container和gvisor。
kata containers是由OpenStack基金会管理,但独立于OpenStack项目之外的容器项目。kata containers整合了Intel的 Clear Containers 和 国内HyperHQ团队 的 runV项目,它的本质是在容器中建立一个经过裁剪的,轻量化的内核,所以在你启动一个kata container后,你就能看到一个正常的虚拟机在运行,而Qemu就是这个虚拟机的VMM(虚拟机管理程序)。作为标准的虚拟机,kata container自然原生就带了pod的概念,一个虚拟机就是一个pod,而用户定义的容器,就是这个pod里面的进程。这边是kata container的一个架构图:
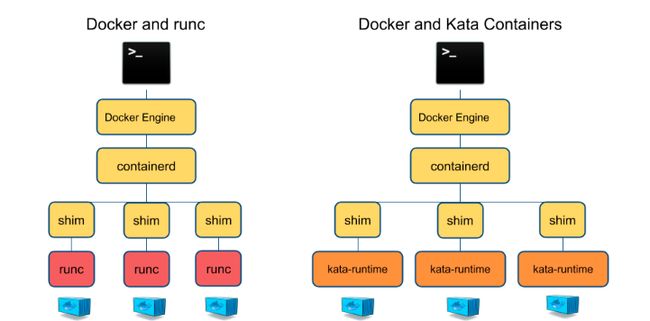
从这个架构图可以看到,kata-runtime是和runc平级的,而kata container是完全按照OCI规范来进行设计的。大家不难想到,根据前面的介绍,containerd可以直接通过containerd-shim来对kata-runtime进行调用,所以对于docker来说,完全可以通过原来的方式创建kata容器,管理的方式也都和原来一样。而你也不难想到,k8自然也是可以非常方便的创建和管理kata container容器(通过docker-shim、cri-containerd或者cri-o)。
可以看到,kata container项目基本还是走的传统虚拟机的路子,通过裁剪出一个精简的guest kernel(这个内核是经过高度优化的,只用于一个容器的运行),以及通过hypervisor(QEMU)虚拟出来的硬件设备,提供一个完整的虚拟机环境。相对而言,gVisor设计更加激进,gVisor的设计中有个一个sentry进程,负责转发应用对于内核各类功能的调用,简单说,就是对应用“冒充”内核的系统组件,在这种思想下,不难理解,sentry需要自己实现一个完成的linux内核的网络栈,以便于处理应用进程间的通讯请求。目前gVisor还处于早期阶段,能调用的内核功能还相当有限,并且在重I/O或者重网络的情况下性能会急剧下降。但这种通过用户态去运行一个操作系统内核,来为应用进程提供强隔离的思路,确实是未来安全容器进一步演化的一个方向。
就目前来说,我更加看好kata container的发展。一方面gVisor这种“冒充内核组件”的方式虽思路很好,但还不够成熟,功能和性能各方面还有限制,另外更重要的是,gVisor本质上不是内核,它所有的调用还是要依赖于宿主机内核的能力,而kata container是一个独立内核,这可以让kata起来的内核版本不同于宿主机的内核,提供真正虚拟机级别的隔离性,对于cilium这类对于内核版本要求非常高的项目具有非常重大的意义。其实目前业界其实已有这方面的试水,华为云的CCI(云容器实例)明确提到了是基于kata container的安全容器技术,阿里也推出了ECI(弹性容器实例,是不是基于kata不确定),应该说安全容器的发展前景还是非常良好的。
kata container与service mesh
这两个一个是基于虚拟化技术的容器运行时,一个是微服务治理框架,有什么关系呢?先来看一下下面这个图
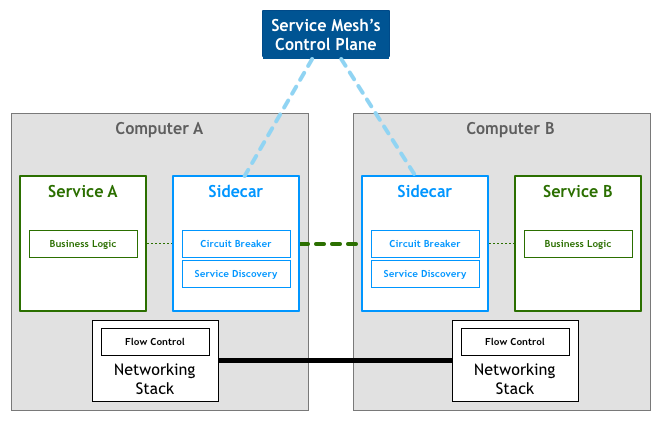
这是一个典型的service mesh的架构图,service 和sidecar分别部署为独立的进程,所有的服务治理逻辑诸如服务发现、服务注册、负载、限流/熔断/降级、分布式跟踪、灰度等功能都放在sidecar里面实现,由服务网格统一管理所有的sidecar,应用无感知。这就是所谓的 服务治理下沉到基础设施,这也是service mesh的核心理念。
service mesh理念很好,真正实现起来难度却很大。究其原因,sidecar仍然是一个用户态的进程,proxy拦截了所有进出service的流量,iptables本身性能就不行,对于服务调用来说又多了几跳,用户态的上下文切换,性能必然会有损失,事实上istio的性能问题至今一直为人诟病,也不能大规模使用于生产环境。为了解决这个问题,也诞生了诸如cilium这样的项目,直接绕过内核的tcp堆栈来提高性能。而安全容器项目,为这个问题的解决提供了一个新的思路,因为kata container本身就是一个精简的guest kernel,那为何不把这部分服务治理逻辑直接下沉到guest kernel中,作为内核网络协议栈的一部分,真正的成为基础设施。这样只要基于虚拟化的容器启动,自动就具有了服务治理的全部功能,而且是内核级别的,应用完全无感知。之前小剑老师分享的service mesh介绍中,有这么一张PPT
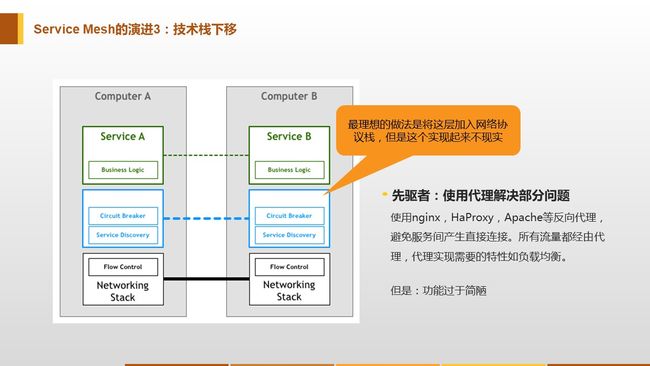
当时小剑的结论是把服务治理这一层加入内核的网络协议栈是最理想的,但是实现起来不现实。而kata container里面运行的是一个真正的内核(哪怕是精简的),要定制一些功能相对没那么难,此外基于内核态还可以做很多用户态做不了的事情。当然这里面还有很多工作要做,但无疑虚拟化的容器项目无疑给我们打开了新世界的大门。