
1. Abstract
Boosting tree是一种有广泛应用的技术。听到boosting一词都知道它是一种迭代的更新的逐步降低模型整体的误差的办法如Adboost,当年Adboost跟SVM统治了整个机器学习界。最近我阅读了XGboost(下面简称XGB)论文,想跟大家分享一下自己的读后感,也自己的学习做个笔记。首先先说说XGB在实战上面的成就吧。
Take the challenges hosted by the machine learning competition site Kaggle for example. Among the 29 challenge winning solutions 3 published at Kaggle’s blog during 2015, 17 solutions used XGBoost. Among these solutions, eight solely used XGBoost to train the model, while most others combined XGBoost with neural nets in ensembles.
以机器学习竞赛网站Kaggle举办的挑战为例。在2015年Kaggle博客发布的29个挑战获胜解决方案3中,17个解决方案使用XGBoost。在这些解决方案中,八个单独使用XGBoost来训练模型,而其他大多数人则将XGBoost与神经网络合并在一起。
可见XGB在kaggle上是大杀伤力武器,除了实战以外XGB在理论上面也是state-of-the-art。
- 相对GBDT来说,XGB在增加二阶梯度有更高的精度。
- XGB的节点划分策略带有进行预排序,利用样本在损失函数上面的二阶梯度作为权值。
- XGB对稀疏的特征划分方式。
- 在处理特征的粒度上进行多线程的优化。
- 使用近似算法替代每个样本逐个判断最佳分裂点的Exact Greedy Algorithm算法。
以上是本文对XGB几个要点的展开。(由于对公式支持比较差,大家可以转到我的知乎上查看XGBoost论文阅读及其原理,以后可能更多文章在知乎上优先发表)。今日是母亲节,也祝妈妈身体健康,每天都开开心心咯!
2. Main Work
2.1 Tree Boosting with Loss function
给定一个数据集D中有n个样本,每个样本有m维特征。通过训练数据集D,我们得到K棵树。这K棵树累加的值为我们的预测值。

其中fk(xi)是样本xi在第k棵树的叶子上的权值。因此我们也可以这样定义。
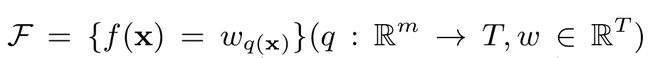
有了输出值,我们就可以代入损失函数当中,损失函数可以是Mean Square Error,也可以是Cross entropy Loss。当然这个不是特别重要,因为我们最后要的是他们梯度。最后我们加上我们的Regularized Learning Objective,整个损失函数就出来了。

那我们就有优化的目标了。
2.2 Gradient Tree Boosting
对于损失函数我们可以将它预测值展开成k棵树的预测叠加形式。在t次迭代当中,我们可以将树展开成:
yi = f1(xi) + f2(xi) + ... + f(t-1)(xi) + ft(xi)
那么损失函数可以变成:

这是我们可以利用我们熟悉的二阶泰勒展开进行近似:

其中gi为第i个样本预测值在前t次迭代的损失函数的一阶梯度,hi为第i个样本预测值在前t次迭代的损失函数的二阶梯度。
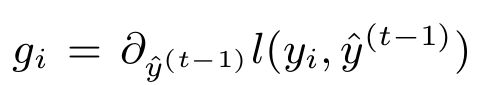

接下来我们就对损失函数的展开式进行转换为关于ft(xi)的二元函数并移除与ft(xi)无关的常数项:

然后我们再定义:

进一步简化损失函数为:

显然我们就可以知道在当前第t次迭代当中,损失函数的极值点值(叶子节点的权值),

并计算处最优损失函数值
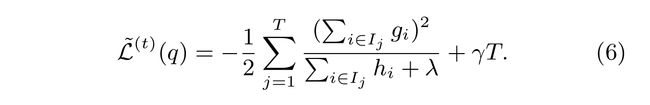
其实eq 6就是用来衡量用哪个特征做分裂,用在哪个特征值上做分裂。这样说起来就有点像我们在DT里面的“纯度”衡量值(Gini,Entropy)但我们里是最能够使得损失函数值最小的分裂点。跟DT一样我们会将左右两个字节点“衡量值”(在这里就是eq 6)与父节点的“衡量值”相减,得到分支后的损失函数降低程度,当然我们希望下降程度越大越好啦。

如下图所示,损失值越低结构也就越好啦。

2.3 子采样和权值收缩
其实这两个技巧都是为了减低overfitting,首先子采样分为样本子采样和特征子采样。子采样算是RF的代表了,通常来说我们使用特征取样更多。鄙人私下认为,特征子采样从不同角度去考量样本能让模型更具有多样性。另外权值收缩也就是对叶子节点的权值乘上收缩因子,该收缩因子是人为设定的参数。其作用是为了给后面的迭代保留优化空间。大家想想假如一棵树把损失函数降得很低很低,那么后续的优化空间就少了,训练的样本和特征也就少了,最后也就overfitting。当然XGB不仅仅只有这些tricks,例如leaf-wise, 后剪枝,树高度控制等。
2.4 Approximate Algorithm
大多数的DT里面分支算法是极其关键的算法,对于连续型的特征,我们通常都是对某一系列的特征的所有样本逐个进行分裂判断。这样也是Exact Greedy Algorithm啦。

Exact Greedy Algorithm这个算法的时间复杂度O(d * m + m * log(m)) = O(m * (d + log(m))),m * log(m)是因为对样本特征进行约排序,d * m是对每个样本的每个特征进行分裂判断。
然后就有近似算法(Approximate Algorithm),其实它就是对连续型特征进行离散化。那么在XGB又是怎么做特征离散化呢。其实这里利用到的还是二阶梯度。对于数据集D={(x1k , h1), (x2k , h2) · · · (xnk , hn)},其中k是样本的第k个特征值,h是xik在损失函数的二阶梯度。对于特征而言,我们不在乎特征值是1, 2, 3, 4.... , n还是说百分比,只要分裂节点的“纯度”提高或者说损失函数值降低就可以了。于是我们定义下面rank公式用于排序使用。

rank的计算是对某一个特征上,样本特征值小于z的二阶梯度除以所有的二阶梯度总和。其实就是对样本的二阶梯度进行累加求和,那二阶梯度在这里就是代表样本在特征k上的权值。于是我们就对样本重新组合成为{sk1 , sk2 , · · · skl}分裂点,ski是指每个buckets的边界点。再有:

上面的eps用于设定最大的rank值,其中eps在(0, 1)的区间上。我们可以大致的认为有1 / eps个buckets。而我们对这么多个buckets进行分支判断。显然,比起对m个样本找分裂节点,对1 / eps个buckets找分裂节点更快捷,而且eps越大buckets数量越少,粒度越粗。至于我们为什么用二阶梯度作为样本的权值,我们可以回顾一下eq (3)里面的损失函数,将其转换为(这里这个说话好像有点牵强,我待会再细看appendix):

这里hi可以看作是样本Square Error的权值。
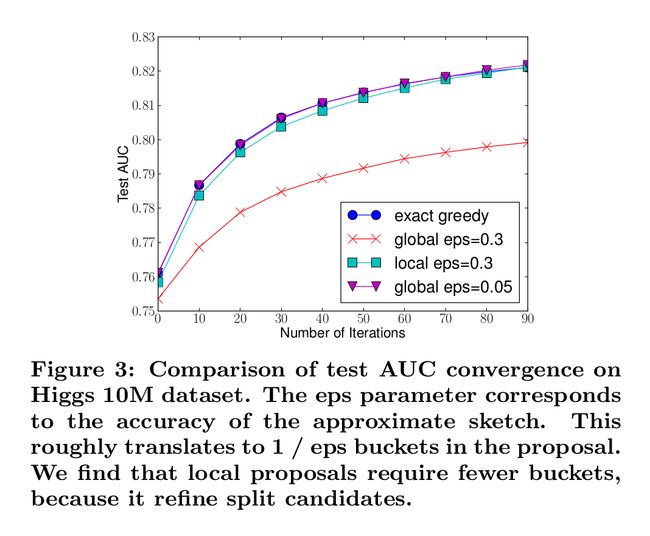
对于这种离散化的方式有两种:一种是在建立第k棵树的时候利用样本的二阶梯度对样本进行离散化,每一维的特征都建立buckets。在建树的过程中,我们就重复利用这些buckets去做。另一种是每次进行分支时,我们都重新计算每个样本的二阶梯度并重新构建buckets,再进行分支判断。前者我们称之为全局选择,后者称为局部选择。显然局部选择的编码复杂度更高,但是实验当中效果极其的好,甚至与Exact Greedy Algorithm一样。
2.5 Sparsity-aware Split Finding
很多时候训练数据都是稀疏的(如TF-IDF),数据都是有缺失值的。很多机器学习的算法都是没有具体办法处理稀疏数据,如SVM,NN等。XGB训练数据的时候,它使用没有缺失的数据去进行节点分支。然后我们将特征上缺失的数据尝试放左右节点上,看缺失值应当分到那个分支节点上。我们把缺失值分配到的分支称为默认分支。

3 Other work
在整个系统设计上,XGB也是很讲究的。下面我就简要的介绍一下:
利用列块进行并行计算:在我们训练过程中我们主要是做分支处理,分支处理就要对每一列(特征)找出适合的分裂点。通常来说,我们更青睐使用csc存储,这样我们就方便取出来。再者我们在分支的时候都会预先对数据按照其特征值进行排序。所以我们将数据按照列存储成一个数据块方便我们在分支的时候并行处理。所以我们要知道XGB的并行计算的粒度不在树上,而是在特征上,尤其是不同分支节点上(leaf-wise)。当然这也成为XGB的一个问题所在,需要额外的空间存储pre-sort的数据。而且每次分支后,我们都要找处落在下一个子节点上的样本,并组织好它。后来就有了LightGBM,下次我再将其整理出来。
-
缓存处理能力:对于有大量数据或者说分布式系统来说,我们不可能将所有的数据都放进内存里面。因此我们都需要将其放在外存上或者分布式存储。但是这有一个问题,这样做每次都要从外存上读取数据到内存,这将会是十分耗时的操作。因此我们使用预读取(prefetching)将下一块将要读取的数据预先放进内存里面。其实就是多开一个线程,该线程与训练的线程独立并负责数据读取。此外,我还要考虑block的大小问题。如果我们设置最大的block来存储所有样本在k特征上的值和梯度的话,cache未必能一次性处理如此多的梯度做统计。如果我们设置过少block size,这样不能充分利用的多线程的优势,也就是训练线程已经训练完数据,但是prefetching thread还没把数据放入内存或者cache中。经过测试,作者发现block size设置为2^16个examples最好:
 block size比较
block size比较
- 数据块以外的计算力提高:对于超大型的数据,我们不可能都放入放入内存,因此大部分都放入外存上。假如我们将数据存于外存上将给我们带来读写速度受限的问题。文中有两种方法,一种是对数据进行压缩存于外存中,到内存中需要训练时再解压,这样来增加系统的吞吐率,尽管消耗了一些时间来做编码和解码但还是值得的。另一种就是多外存存储,其实本质上就是分布式存储。这样说有多个线程对分布式结构管理,吞吐率自然高啦。
4 References
- https://arxiv.org/pdf/1603.02754.pdf
- https://github.com/dmlc/xgboost
- http://xgboost.readthedocs.io/en/latest/
- https://www.zhihu.com/question/58883125/answer/206813653