1. 字段查询
通过模型类.objects属性可以调用如下函数,实现对模型类对应的数据表的查询。
| 函数名 |
功能 |
返回值 |
说明 |
| get |
返回表中满足条件的一条且只能有一条数据。 |
返回值是一个模型类对象。 |
参数中写查询条件。 1)如果查到多条数据,则抛异常MultipleObjectsReturned。 2)查询不到数据,则抛异常:DoesNotExist。 |
| all |
返回模型类对应表格中的所有数据。 |
返回值是QuerySet类型 |
查询集 |
| filter |
返回满足条件的数据。 |
返回值是QuerySet类型 |
参数写查询条件。 |
| exclude |
返回不满足条件的数据。 |
返回值是QuerySet类型 |
参数写查询条件。 |
| order_by |
对查询结果进行排序。 |
返回值是QuerySet类型 |
参数中写根据哪些字段进行排序。 |
get、all前面已经使用过了,下面主要讲解filter、exclude和order_by的使用。
准备数据:
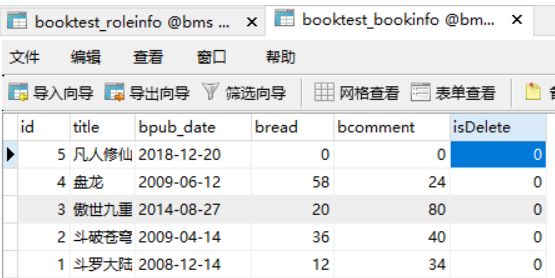
index.html:
<html> <head> <title>图书列表title> head> <body> <h1>{{title}}h1> {%for i in list%} {{i.id}}<br> {{i.btitle}}<br> {{i.bpub_date}}<br> {{i.bread}}<br> {{i.bcomment}}<br> {%endfor%} body> html>
我们后面的查询只需要在views.py中修改代码就行了。
1.1 查看mysql数据库日志
为了方便查看查询结果,我们先配置下,让系统生成mysql日志文件。
我使用的是mysql5.7版本,其他版本可以参考这个,但是建议是自己去百度。
查看mysql数据库日志可以查看对数据库的操作记录需要做如下配置:
首先查看是否开启了binlog:show binary logs;

发现没有开启logs,那么我们就可以开始配置了。
我们要去C:\ProgramData\MySQL\MySQL Server 5.7路径下找到my.ini文件。
然后编辑这个文件,我们可以使用搜索功能。
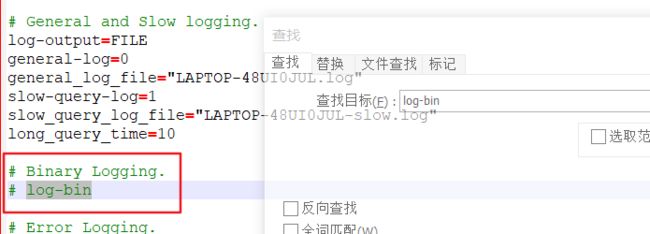
修改成这样:
# Binary Logging. log-bin=mysql-bin binlog-format=Row

如果不能修改,就使用管理员权限打开。
然后重启mysql服务。
验证binlog是否开启:show variables like 'log_bin'; 和 show binary logs;
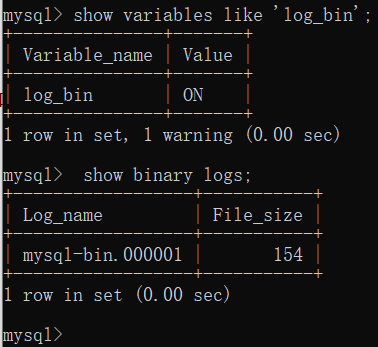
binlog文件的位置:如果在修改my.ini的binlog时给的是全路径,那么生成的日志文件就在指定的目录下;如果只给一个名字,那么生成的binlog日志的位置为:

如果给的全路径配置为:
log-bin=指定路径\mysql-bin
binlog-format=Row
那么就会在指定路径下生成文件。
1.2 条件运算符
1.2.1 查询
exact:表示判断等于,和 = 差不多。
例:查询编号为1的图书。
list=BookInfo.objects.filter(id__exact=1)
可简写为:
list=BookInfo.objects.filter(id=1)

1.2.2 模糊查询
contains:是否包含。
如果要包含%无需转义,直接写即可。
list = BookInfo.objects.filter(btitle__contains='斗')

startswith、endswith:以指定值开头或结尾。
例:查询书名以'天'结尾的图书。
list = BookInfo.objects.filter(btitle__endswith='天')

以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith。
1.2.3 空查询
isnull:是否为null。
例:查询书名不为空的图书。
list = BookInfo.objects.filter(btitle__isnull=False)

1.2.4 范围查询
in:是否包含在范围内。
例:查询编号为1或3或5的图书。
list = BookInfo.objects.filter(id__in=[1, 3, 5])

1.2.5 比较查询
gt、gte、lt、lte:大于、大于等于、小于、小于等于。
例:查询编号大于3的图书。
list = BookInfo.objects.filter(id__gt=3)

不等于的运算符,使用exclude()过滤器。
例:查询编号不等于3的图书
list = BookInfo.objects.exclude(id=3)

1.2.6 日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
例:查询2009年发表的图书。
list = BookInfo.objects.filter(bpub_date__year=2009)

例:查询2008年12月14日后发表的图书。
from datetime import date ... list = BookInfo.objects.filter(bpub_date__gt=date(2008, 12, 14))

1.3 F对象
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 答:使用F对象,被定义在django.db.models中。
语法如下:
F(属性名)
例:查询阅读量大于等于评论量的图书。
from django.db.models import F ... list = BookInfo.objects.filter(bread__gte=F('bcomment'))

可以在F对象上使用算数运算。
例:查询阅读量大于2倍评论量的图书。
list = BookInfo.objects.filter(bread__gt=F('bcomment') * 2)

1.4 Q对象
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
例:查询阅读量大于20,并且编号小于3的图书。
list=BookInfo.objects.filter(bread__gt=20,id__lt=3)
或
list=BookInfo.objects.filter(bread__gt=20).filter(id__lt=3)

如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符,Q对象被义在django.db.models中。
语法如下:
Q(属性名__运算符=值)
例:查询阅读量大于20的图书,改写为Q对象如下。
from django.db.models import Q ... list = BookInfo.objects.filter(Q(bread__gt=20))

Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或。
例:查询阅读量大于20,或编号小于3的图书,只能使用Q对象实现。
list = BookInfo.objects.filter(Q(bread__gt=20) | Q(pk__lt=3))

Q对象前可以使用~操作符,表示非not。
例:查询编号不等于3的图书。
list = BookInfo.objects.filter(~Q(pk=3))

1.5 聚合函数
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg,Count,Max,Min,Sum,被定义在django.db.models中。
例:查询图书的总阅读量。
from django.db.models import Sum ... sum = BookInfo.objects.aggregate(Sum('bread'))
修改界面
<html> <head> <title>图书列表title> head> <body> <h1>{{title}}h1> {{sum}}<br> body> html>
以及
from django.shortcuts import render from booktest.models import BookInfo from django.db.models import Sum def index(request): sum = BookInfo.objects.aggregate(Sum('bread')) context = {'title': '图书列表', 'sum': sum} return render(request, 'booktest/index.html', context)

注意aggregate的返回值是一个字典类型,格式如下:
{'聚合类小写__属性名':值}
如:{'sum__bread':3}
使用count时一般不使用aggregate()过滤器。
例:查询图书总数。
count = BookInfo.objects.count()
参照上面修改代码

注意count函数的返回值是一个数字。
2. 查询集
查询集表示从数据库中获取的对象集合,在管理器上调用某些过滤器方法会返回查询集,查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果,从Sql的角度,查询集和select语句等价,过滤器像where和limit子句。
返回查询集的过滤器如下:
- all():返回所有数据。
- filter():返回满足条件的数据。
- exclude():返回满足条件之外的数据,相当于sql语句中where部分的not关键字。
- order_by():对结果进行排序。
返回单个值的过滤器如下:
- get():返回单个满足条件的对象
- 如果未找到会引发"模型类.DoesNotExist"异常。
- 如果多条被返回,会引发"模型类.MultipleObjectsReturned"异常。
- count():返回当前查询结果的总条数。
- aggregate():聚合,返回一个字典。
判断某一个查询集中是否有数据:
- exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。
2.1 两大特点
- 惰性执行:创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用。
- 缓存:使用同一个查询集,第一次使用时会发生数据库的查询,然后把结果缓存下来,再次使用这个查询集时会使用缓存的数据。
示例:查询所有,编辑booktest/views.py的index视图,运行查看。
list=BookInfo.objects.all()

2.2 查询集的缓存
每个查询集都包含一个缓存来最小化对数据库的访问。
在新建的查询集中,缓存为空,首次对查询集求值时,会发生数据库查询,django会将查询的结果存在查询集的缓存中,并返回请求的结果,接下来对查询集求值将重用缓存中的结果。
演示:运行项目shell。
python manage.py shell
情况一:如下是两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载。
from booktest.models import BookInfo [book.id for book in BookInfo.objects.all()] [book.id for book in BookInfo.objects.all()]

情况二:经过存储后,可以重用查询集,第二次使用缓存中的数据。
list=BookInfo.objects.all() [book.id for book in list] [book.id for book in list]

2.3 限制查询集
可以对查询集进行取下标或切片操作,等同于sql中的limit和offset子句。
注意:不支持负数索引。
对查询集进行切片后返回一个新的查询集,不会立即执行查询。
如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()如果没有数据引发DoesNotExist异常。
示例:获取第1、2项,运行查看。
list=BookInfo.objects.all()[0:2]
