前言
Java内存模型(Java Memory Model,简称JMM),是针对Java在多线程并发下可能出现的各种问题而提出的一种解决方案。主要围绕可见性、原子性和有序性来展开陈述。要阐述清楚JMM,我们需要从最底层的内存屏障、同步机制的内存语义,再到最上层的happen-before规则,逐步解析JMM的前世今生。希望能通过这篇文章,让自己对JMM有一个比较清晰的理解。
java内存模型的基础
两个关键问题
JMM主要是解决两个问题:线程间如何通信、线程间如何同步。
我们知道线程间通信的方式一般有两种
- 共享内存,通过读-写公共状态来隐式通信
- 消息传递,没有公共状态,只能通过收发消息来显式通信
两个问题中,其中一个是线程间如何同步,那么什么是同步呢?同步是指线程中用于控制不同线程间操作发生相对顺序的机制。
- 共享内存,同步必须显式指定某个方法或某段代码在线程间互斥执行
- 消息传递,发送必须在接受之前,所以同步是隐式进行的
Java并发采用的是共享内存的方式。
JMM的抽象结构
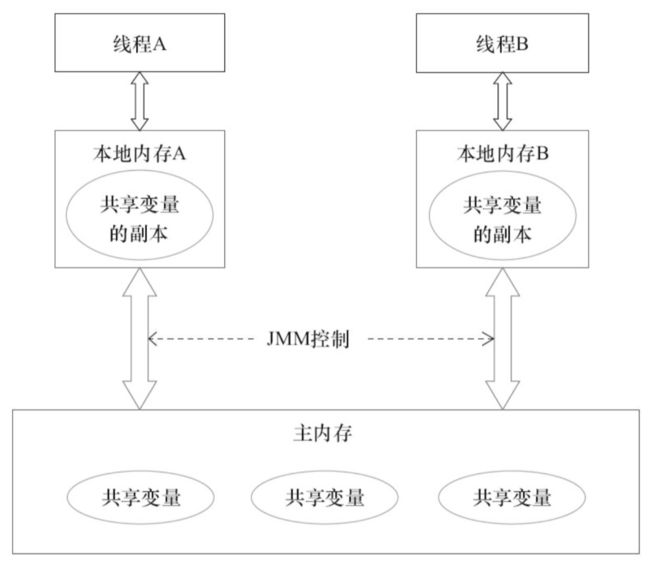
Java线程间通信由JMM控制,JMM决定一个线程对共享变量的修改何时对另一个线程可见。
Java为了提高程序执行效率,将内存分为两种:主内存和本地内存。
- 主内存,存放着共享变量
- 本地内存,存放着共享变量的副本或拷贝,本地内存并不真实存在,而是JMM的一个抽象概念
下图为两者之间的关系
重排序
重排序的目的是为了提高性能,但是必须在不改变程序语义的前提下。重排序大概分为以下几类:
- 编译器优化的重排序
- 指令级并行的重排序。现代cpu通过指令级并行技术将多条指令重叠执行。
- 内存系统的重排序??没懂!
JMM编译器重排序会禁止特定类型重排序,对于特定类型会在生成指令序列时插入内存屏障,通过内存屏障来禁止处理器重排序。
数据依赖性
单个处理器和单个线程中,如果两个操作访问同一个变量,且其中一个操作为写操作,我们就认为这两个操作存在数据依赖性。
- 写后读,a = 1; b = a;
- 写后写,a = 1; a = 2;
- 读后写,b = a; a = 1;
因为如果对数据依赖性的操作进行重排序会改变执行结果,所以编译器和处理器并不会重排序数据依赖性的两个操作。
as if serial && 程序顺序规则
不管如何重排序,单线程程序的执行结果不能被改变。
编译器和处理器不会对存在数据依赖性的两个操作重排序。但是如果两个操作不存在数据依赖性,这些操作就可能被重排序。
- double pi = 3.13; // A
- double r = 1.0; // B
- double area = pi * r * r; // C
上述例子的A和B可能被重排序。虽然被重排序了,但是给人的感觉就像串行执行的。
软件技术和硬件技术有一个共同目标:在不改变程序执行结果的前提下,尽可能提高并行度。编译器和处理器遵从这一目标,JMM同样也遵从这一目标。
重排序对多线程的影响
class RecorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
}
}
}
4能看到1处的更改吗?答案是:不一定
首先,1和2重排序可能出现的问题,执行的流程可能为:2 -> 3 -> 4 -> 1
- flag = true
- if (flag)
- int i = a * a // 这时a的值为0
- a = 1
3和4重排序也可能出现问题。步骤4可能被拆分为两个操作:temp = a * a和int i = temp
- temp = a * a
- a = 1
- flag = true
- if (flag)
- int i = temp // 这时i的值仍然是a被修改之前的值相乘
其实步骤3和步骤4其实存在控制依赖关系,但是控制依赖关系可能会影响执行的并行度。所以编译器和处理器会采用猜测技术来提升性能。所谓猜测,就是线程可以提前计算a*a,然后将结果保存在重排序缓存中。当步骤3判断为true时,直接将结果从重排序缓存中拿出来并写入到变量i中。
猜测执行导致的重排序破坏了多线程的语义。单线程中对控制依赖关系的操作重排序没有任何问题,但是多线程环境中就有问题了。
顺序一致性模型
顺序一致性是一个理论参考模型,JMM会以顺序一致性模型作为参照。
数据竞争和顺序一致性
什么是数据竞争?一个线程写一个变量,另外一个线程读这个变量,且写和读之间没有通过同步来排序。数据未正确同步时会出现数据竞争,正确同步时不会出现。那么,JMM如何怎么判断程序是正确同步呢?
如果程序是正确同步的,程序的执行将具有顺序一致性。也就是说,程序的执行结果与该程序顺序一致性模型的执行结果相同。该同步是一个广义的同步。
顺序一致性模型的定义
顺序一致性模型有两个特性
- 单线程中的所有操作必须按照程序的顺序执行
- 所有线程都只能看到一个单一的执行操作顺序。即:每个操作都必须原子执行,且执行结果立即对所有线程可见。
上述第二点其实就是没有本地内存的概念了。所有线程的操作都是在主内存上,且任意时间点最多只有一个线程可以操作主内存。
我们举一个例子,A线程执行A1、A2、A3,B线程执行B1、B2、B3。
第一步,假设A线程的执行和B线程的执行都在同一个监视器下执行,那么可能的执行结果如下:
A1 -> A2 -> A3 -> B1 -> B2 -> B3
A的所有操作都先于B的所有操作
第二步,假设A线程的执行和B线程的执行是在顺序一致性模型下执行,可能的执行结果如下:
B1 -> A1 -> A2 -> B2 -> A3 -> B3
整体看上去可能是无序的。但是,在A看来,A的所有操作是有序的;在B看来,B的所有操作也是有序的。同时该结果中,每个操作都对后面的所有操作可见。
第三步,JMM并不会有顺序一致性模型的保证
JMM中看到的结果不仅整体无序,而且所有线程看到的操作执行顺序也可能不一样。除了单线程的数据依赖性之外,没有任何顺序的保证。
同步程序的顺序一致性效果
class RecorderExample {
int a = 0;
boolean flag = false;
public synchronized void writer() {
a = 1; // 1
flag = true; // 2
}
public synchronized void reader() {
if (flag) { // 3
int i = a * a; // 4
}
}
}
虽然加了synchronized,但是同步块内可以重排序,比如1和2、3和4。
JMM具体实现有一个基本的方针:在不改变(正确同步的)程序执行结果的前提下,尽可能地为编译器和处理器的优化打开方便之门。
volatile内存语义
如何理解volatile?可以简单地把单个变量的读写,看成使用锁对其进行了同步操作。例如:
class VolatileExample {
volatile long v1 = 0L;
public void set(long l) {
v1 = l;
}
public void getAndIncrement() {
v1++;
}
public long get() {
return v1;
}
}
其和下面的例子等同
class VolatileExample {
volatile long v1 = 0L;
public synchronized void set(long l) {
v1 = l;
}
public void getAndIncrement() {
long temp = get();
temp += 1L;
set(temp);
}
public synchronized long get() {
return v1;
}
}
【注】:volatile具有原子性和可见性的特性,但volatile修饰的变量和其他操作组合时并不具有原子性,例如自增操作。
volatile写读的happen-before关系
volatile的内存可见性比volatile自身的特性更重要!从内存语义看,volatile的写-读和锁的释放-获取有相同的内存效果:
- volatile的写和锁的释放有相同的内存语义
- volatile的读和锁的获取有相同的内存语义
volatile可以禁止指令重排序。
volatile写读的内存语义
- volatile写的内存语义:当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存
- volatile读的内存语义:当读一个volatile变量时,JMM会把该线程对应本地内存置为无效,接下来将从主内存中读取共享变量
我们总结一下:
- volatile写,其实是向其他线程发出了消息
- volatile读,其实是接受了之前某个线程发出的消息
- 两个线程,一个线程A写,另外一个线程B读,其实就是A通过主内存向B发送消息
volatile内存语义实现原理
- 第2个操作为volatile写时,不管第一个操作是什么,都不能重排序
- 第1个操作为volatile读时,不管第2个操作是什么,都不能重排序。
- 第1个操作为volatile写,第2个操作为volatile读,不能重排序
JMM如何保证volatile内存语义呢?
其实是通过编译器在生成字节码的时候,在指令序列中插入内存屏障来禁止特定类型的处理器重排序。因为不同处理器在内存屏障的支持上可能不同,所以JMM采取保守策略。怎样的保守策略呢?
- volatile写前面插入StoreStore
- volatile写后面插入StoreLoad
- volatile读后面插入LoadLoad
- volatile读后面插入LoadStore
需要注意的是,编译器和jvm实现会对屏障进行优化
- 在不改变语义的情况下,编译器会省略掉不必要的屏障。
- 另外,不同的处理器也有不同的内存处理模型,所以这一层JVM实现的时候还可以继续进行优化。
JSR133为什么需要对volatile内存语义进行增强
因为旧的内存模型只会禁止volatile变量间的重排序,但是不禁止volatile和普通变量的重排序,所以会出现问题:
- 线程A,普通变量写 // 1
- 线程A,volatile写 // 2
- 线程B,volatile读 // 3
- 线程B,普通变量读 // 4
可能的执行顺序为:2 -> 3 -> 4 -> 1,就会导致4读取的数据可能是1修改之前的数据。
所以旧的内存模型中,volatile的写-读并不具有锁的释放-获取所具有的内存语义
我在再来对volatile和锁总结一下。锁能保证整个临界区的原子性,volatile只能保证单个变量的原子性,所以功能上锁更强大,但是在可伸缩性和执行性能上volatile更有优势。
锁内存语义
happen-before关系
MonitorExample {
int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
} // 6
}
假设线程A执行writer方法,随后线程B执行reader方法
- 根据程序次序规则,1 happen before 2, 2 happen before 3, 4 happen before 5, 5 happen before 6
- 根据监视器锁规则,3 happen before 4
- 根据传递性规则,2 happen before 5
因为有上述happen-before规则,所以线程A在释放锁之前所有可见的内存变量,在线程B获取到同一个锁之后,将立即对线程B可见。
内存语义
- 线程A释放一个锁,实际上是线程A向接下来将要获取这个锁的某个线程发出了消息
- 线程B获取一个锁,实际上是线程B接受到了之前某个线程发出的消息
- 线程A释放锁,线程B获取锁,实际上是线程A通过主内存向线程B发送消息
【注】:消息,其实可以简单看成是对共享变量的修改。
内存语义的实现
我们借助于重入锁来分析锁的内存语义。
使用公平锁,加锁方法lock的流程如下:
- ReentrantLock.lock()
- FairLock.lock()
- AbstractQueuedSynchronizer.acquire(int arg)
- ReentrantLock.tryAcquire(int acquires)
第4步才开始加锁,所以我们直接从第4步开始分析。
private volatile int state;
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
锁的释放最终会修改volatile变量。
非公平锁其实和公平锁比较类似,调用流程如下:
- ReentrantLock.lock()
- UnFairLock.lock()
- AbstractQueuedSynchronizer.compareAndSetState()
第三步才真正开始加锁,内部调用的是Unsafe.compareAndSwap,简称CAS。
CAS方法在jdk文档说明如下:如果当前状态值等于预期值,则以原子方式将同步状态设置为给定的更新值,该操作具有和volatile写读相同的内存语义。
为什么CAS具有和volatile写读相同的内存语义呢?回顾一下volatile的内存语义
- 编译器不能对volatile读和之后的操作重排序
- 编译器不能对volatile写和之前的操作重排序
组合一下,其实就是编译器不能对CAS、CAS前面的操作、CAS后面的操作重排序。也就是说执行的顺序一定是:
CAS前面的操作 -> CAS -> CAS后面的操作
查看x86或x64的c++源码得知
int mp = os::is_MP();
__asm {
// …
LOCK_IF_MP(mp)
copxchg dword ptr [edx], ecx
}
- 程序在多处理器上运行,需要加上lock
- 程序在单处理器上运行,去掉lock(单处理器自身会维护顺序一致性)
intel对lock的说明如下
- 确保读-改-写的原子操作,老的版本lock会锁总线,开销比较昂贵;新版本只会lock缓存,开销就大大降低了
- 禁止该指令与之前和之后的读或写指令重排序
- 所有缓冲区的数据刷新到内存
第2点和第3点其实就足可以实现volatile的内存语义了
最后,我们总结锁的内存语义。其实锁的内存语义包含两种
- volatile写-读的内存语义
- CAS附带的volatile读和volatile写组合的内存语义
concurrent包的实现
组合volatile和CAS,我们可以发现java线程之间的通信变成了4种方式
- A线程volatile写,B线程volatile读
- A线程volatile写,B线程CAS更新
- A线程CAS更新,B线程CAS更新
- A线程CAS更新,B线程volatile读
concurrent源代码的实现大体是下面这样的模式
- 首先,声明共享变量为volatile
- 然后,使用CAS更新来实现线程间的同步
- 同时,配合CAS、volatile读、volatile写的内存语义实现多线程间的通信
concurrent的基础类AQS和AtomicXxx都是这样的模式,而高级类又是依赖于基础类
final内存语义
final变量的重排序规则
- 写final变量重排序。在构造方法内对一个final变量的写入,与随后把这个构造方法所属的对象的引用赋值给另一个引用变量,这两个操作之间不能重排序
- 读final变量重排序。初次读一个包含final变量的对象的引用,与随后初次读这个final变量,这两个操作之间不能重排序
我们举一个例子看看
FinalExample {
int i;
final int j;
static FinalExample obj;
public FinalExample() {
i = 1;
j = 2;
}
public static void writer() {
obj = new FinalExample();
}
public static void reader() {
FinalExample object = obj;
int a = object.i;
int b = object.j;
}
}
写final变量的重排序规则
实现包含两个方面
- JMM禁止编译器把final变量的写重排序到构造方法之外
- 编译器会在final变量写之后,构造方法return之前,插入StoreStore屏障。该屏障会禁止处理器把final变量的写重排序到构造方法之外
上述例子中,普通变量i可能被重排序到构造方法之外,那么reader线程可能错误地读取i在构造方法中赋值之前的值。
读final变量的重排序规则
编译器会在读final变量之前插入LoadLoad屏障。该屏障会限制:读final变量一定在读对象引用之后。而读对象的时候final变量已经被writer线程初始化过了。
final变量为引用类型
这时,仍然满足重排序规则的第2点,构造方法return之前,插入StoreStore屏障。所以构造方法内的所有变量都将刷新到主内存
为什么final引用不能从构造方法“溢出”
写final变量的重排序规则,需要额外的一个保证:构造方法内部,不能让构造对象的引用被其他线程可见,即:对象引用不能在构造方法中溢出。
class FinalReferenceEscapeExample {
final int i;
static FinalReferenceEscapeExample obj;
public FinalReferenceEscapeExample() {
i = 1; // 1,写final变量
obj = this; // 2,this引用溢出
}
public static void writer() {
obj = new FinalReferenceEscapeExample();
}
public static void reader() {
if (obj != null) { // 3
int temp = obj.i; // 4
}
}
}
假如线程A执行writer方法,线程B执行reader方法。因为操作2使得还未构造完的对象就为线程B可见。即使操作2在构造方法里写在最后。B仍然可能无法看到final域被初始化后的值,因为1和2可能被重排序。
例如可能的执行顺序为:2 -> 3 -> 4 -> 1
final语义在处理器中的实现
因为X86或X64不会对写-写做重排序,所以StoreStore屏障会被去掉
同时也不会对存在间接依赖关系的操作做重排序,所以也会把LoadLoad去掉
happen-before规则
现在,我们可以引申出对程序员至关重要的happen-before规则了。
- 程序顺序规则。线程中的每个操作,happen-before该线程中的任意后续操作。
- 监视器锁规则。对一个锁的解锁,happen-before于随后对这个锁进行加锁。
- volatile变量规则。对一个volatile变量的写操作,happen-before后续对这个volatile变量的读操作
- 传递性。如果A happen-before B,B happen-before C,那么A happen-before C
- start规则。线程A执行Thread.start启动线程B,A线程的start操作happen-beforeB中的任何操作
- join规则。如果线程A执行Thread.join线程B并成功返回,那么线程B中的任何操作happen-beforeA从join操作成功的返回
- interrupt规则。如果线程A执行Thread.interrupt线程B操作,那么线程A
interrupt之前的操作happen-before线程B检测到中断事件的发生 - 对象终结规则。一个对象初始化完成,happen-before它的
finallize()的调用。
双重检查锁与类的延迟初始化
由来
- 非安全的单例实现
- 双重检查锁的单例实现
因为普通变量的不可见性,所以多个线程可能出现对同一个变量进行初始化。因此,聪明的程序员想到了使用锁+多次判断的方式来实现单例,比如下面的代码:
public class DoubleCheckedLocking {
private static Instance instance;
public static Instance getInstance() {
if (instance == null) {
synchronized (DoubleCheckedLocking.class) {
if (instance == null) {
instance = new Instance();
}
}
}
return instance;
}
}
问题的根源
instance = new Instance();可以分解为下面3行代码
- memory = allocate(); // 1. 分配对象的存储空间
- actorInstance(memory); // 2. 初始化对象
- instance = memory; // 3. 设置instance指向刚分配的内存地址
- 访问对象instance // 4
其中2和3可能发生重排序
- memory = allocate(); // 1. 分配对象的存储空间
- instance = memory; // 3. 设置instance指向刚分配的内存地址。这时对象还没有初始化!!
- actorInstance(memory); // 2. 初始化对象
- 访问对象instance // 4
java语言规范要求所有线程必须遵守intra-thread semantics,即:内部线程语义。该规范允许单个线程内不会改变单线程执行结果的重排序。上面的2和3有可能被重排序,前提是重排序能提高程序的执行性能。
- 单线程下,因为单线程有
intra-thread semantics,所以不会有问题 - 多线程下,假如线程A执行上述重排序后的4步操作,线程B在2和3之间执行“判断instance是否为空; 初次访问instance”。则会有问题:B访问instance的时候可能instance都还没有初始化,也就是说线程B可能访问还没有初始化的对象,使用的时候将出现问题!!
那么,我们有没有办法解决重排序导致的问题呢?其实,不管2和3如何重排序,只要保证4在2和3之后,那么就没问题。那么如何解决呢?有两种解决方法:
- 禁止2和3重排序 // 可以使用volatile变量的方式
- 允许2和3重排序,但是不允许其他线程看到这个
重排序// 使用类初始化的方式,后面会解释
类初始化
JVM在类的初始化阶段(类加载之后,且被线程使用之前),会执行类的初始化。在执行类初始化期间,JVM会获取一个锁。这个锁会同步多个线程对同一个类的初始化。
那么类初始化会做哪些事情呢?
- 执行类的静态块
- 初始化类中的静态字段
那么什么时候会对类或接口进行初始化呢?假如被初始化的类为T
- 假如T是一个类,且T的实例被创建
- 假如T是一个类,且T中的一个静态方法被调用
- T中声明的一个静态字段被赋值
- T中声明的一个静态字段被赋值,且该字段不是一个常量字段
- T是一个顶级类,且T被嵌套在一个断言里面被执行
线程安全的类初始化实现方案:
public class InstanceFactory {
private static class Holder {
public static Instance instance = new Instance();
}
public static Instance getInstance() {
return Holder.instance;
}
}
这儿的例子满足第4个条件。
总结
前面说了这么多,在结束之前,我们需要对JMM做一个总结。
- JMM抽象化了硬件的内存模型,屏蔽了CPU和操作系统的差异性
- JMM最根本解决的问题是主内存和本地内存的操作顺序
- JMM围绕着原子性、可见性和有序性来展开并设置规范的
-
synchronized实现了这三种特性,volatile只实现了可见性和有序性,final也能实现可见性 - happen-before规则定义了volatile和锁在使用的时候哪些不能重排序
- 【注】最重要的还是,JMM是并发的基础,不了解JMM,就不可能高效地并发。