0x00 前言
最近在使用impala,顺便学习一下相关的原理部分。
下面的组织结构会先介绍一下impala的大致原理和涉及的技术,然后对每块涉及到的技术做一个梳理,最后再深入一点impala的原理。
impala是什么
- 开源数据库系统
- 类MPP并行数据库执行
- Dremel系
- 基于hadoop
0x01 MPP
一、服务器三大体系:SMP、NUMA、MPP
从系统架构来看,商用服务器大体可以分为三类:
- SMP:对称多处理器结构(Symmetric Multi-Processor),
- NUMA:非一致存储访问结构(Non-Uniform Memory Access),
- MPP:以及海量并行处理结构(Massive Parallel Processing)。
SMP:
所谓对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此SMP也被称为一致存储器访问结构(UMA:Uniform Memory Access)。
缺点:SMP服务器的主要特征是共享,系统中所有资源(CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,那就是它的扩展能力非常有限。
NUMA:
由于SMP在扩展能力上的限制,人们开始探究如何进行有效地扩展从而构建大型系统的技术,NUMA就是这种努力下的结果之一。利用NUMA技术,可以把几十个CPU(甚至上百个CPU)组合在一个服务器内。
NUMA服务器的基本特征是具有多个CPU模块,每个CPU模块由多个CPU(如4个)组成,并且具有独立的本地内存、I/O槽口等。由于其节点之间可以通过互联模块(如称为Crossbar Switch)进行连接和信息交互,因此每个CPU可以访问整个系统的内存。显然,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问NUMA的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同CPU模块之间的信息交互。
缺点:由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。
MPP:
和NUMA不同,MPP提供了另外一种进行系统扩展的方式,它由多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制。
在MPP系统中,每个SMP节点也可以运行自己的操作系统、数据库等。但和NUMA不同的是,它不存在异地内存访问的问题。换言之,每个节点内的CPU不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution)。
二、MPP database
基于MPP架构的数据库系统。
- greenplum
- vertica
0x02 Dremel
Dremel 是Google 的“交互式”数据分析系统。Google开发了Dremel将处理时间缩短到秒级,作为MapReduce的有力补充。Dremel作为Google BigQuery的report引擎,获得了很大的成功。
根据Google公开的论文《Dremel: Interactive Analysis of WebScaleDatasets》可以看到Dremel的设计原理。还有一些测试报告。论文写于2006年,公开于2010年。
一、BigQuery
BigQuery允许用户上传他们的超大量数据并通过其直接进行交互式分析,从而不必投资建立自己的数据中心。
二、Dremel特点
- 大规模系统。在一个PB级别的数据集上面,将任务缩短到秒级,无疑需要大量的并发。
- MR交互式查询能力不足的补充。需要GFS这样的文件系统作为存储层。
- 数据模型是嵌套(nested)的。Dremel支持一个嵌套(nested)的数据模型,类似于Json。
- 列式存储。减少CPU和磁盘的访问量。
- 多级服务树查询,将一个相对巨大复杂的查询,分割成较小较简单的查询。大事化小,小事化了,能并发的在大量节点上跑。
- SQL-like的接口,就像Hive和Pig那样。
三、Dremel原理
大致总结一些Dremel的原理,还有好多没明白......
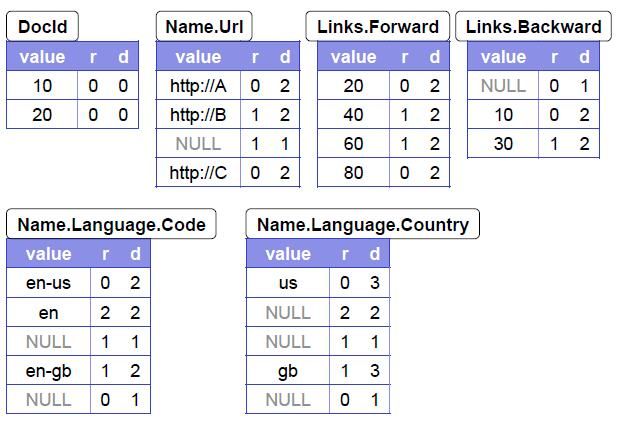
1.列式存储

按记录:在按记录存储的模式中,一个记录的多列是连续的写在一起的。
按列:在按列存储中,可以将数据按列分开。也就是说,可以仅仅扫描A.B.C而不去读A.E或者A.B.C。
注意: 如何能同时高效地扫描若干列,不晓得是怎么实现的。
2.数据模型
在Google, 用Protocol Buffer常常作为序列化的方案。其数据模型可以用数学方法严格的表示如下:
t=dom|
其中t可以是一个基本类型或者组合类型。其中基本类型可以是integer,float和string。组合类型可以是若干个基本类型拼凑。星号(*)指的是任何类型都可以重复,就是数组一样。问号(?)指的是任意类型都是可以是可选的。简单来说,除了没有Map外,和一个Json几乎没有区别。
下图是例子,Schema定义了一个组合类型Document.有一个必选列DocId,可选列Links,还有一个数组列Name。可以用Name.Language.Code来表示Code列。
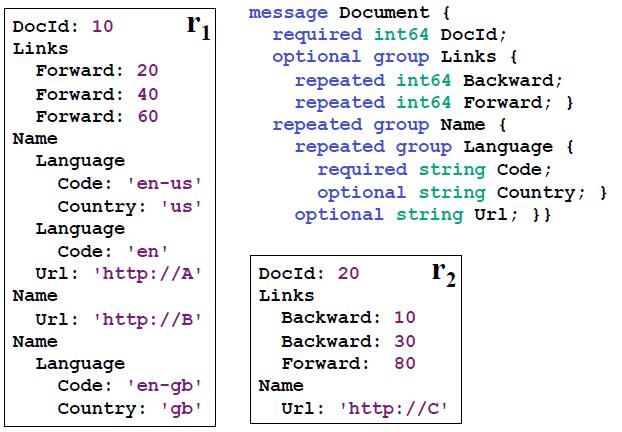
这种数据格式是语言无关,平台无关的。可以使用Java来写MR程序来生成这个格式,然后用C++来读取。在这种列式存储中,能够快速通用处理也是非常的重要的。
上图,是一个示例数据的抽象的模型;下图是这份数据在Dremel实际的存储的格式。
3.服务树结构
如下图,是Dremel的服务树架构的示意图。
root server:最上层有一台的根服务器(root server),负责接收用户查询,并根据sql命令找到命令中设计的数据表,读出相关数据表的元数据,改写原始查询后推入下一层服务器(中间服务器)。同时负责接收中间服务器返回的结果,进行全局聚合,并返回给用户。
intermediate servers:中间服务器改写由上层服务器传递来的查询语句并以此下推,直到最底层的叶节点服务器。在接收到叶节点的结果后进行局部聚集等操作,最后返回跟服务器。
leaf servers: 节点服务器可以访问数据存储层或者直接访问本地磁盘,通过扫描本地数据的方式执行分配给自己的sql语句,在获得查询结果后仍然按照服务树层级由低到高逐层返回结果。

举个栗子:
stage1:对于请求:
SELECT A, COUNT(B) FROM T GROUP BY A
stage2:根节点收到请求,从元数据中获取数据表T的所有子表,以及其对应的服务器,然后改写查询如下:
SELECT A, SUM(c) FROM (R1 UNION ALL ... Rn) GROUP BY A
其中Ri代表root server中从第1个服务器到第n个服务器节点执行的返回结果。
stage3:对子表的查询。
Ri = SELECT A, COUNT(B) AS c FROM Ti GROUP BY A
结构集一定会比原始数据小很多,处理起来也更快。根服务器可以很快的将数据汇总。具体的聚合方式,可以使用现有的并行数据库技术。
0x03 Impala
一、主要组件
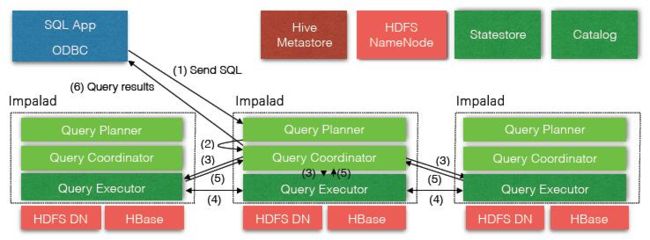
1.Impala Daemon
The core Impala component is a daemon process that runs on each DataNode of the cluster, physically represented by the impalad process.
Impala的核心组件是运行在各个节点上面的impalad这个守护进程(Impala daemon),它负责读写数据文件,接收从impala-shell、Hue、JDBC、ODBC等接口发送的查询语句,并行化查询语句和分发工作任务到Impala集群的各个节点上,同时负责将本地计算好的查询结果发送给协调器节点(coordinator node)。
你可以向运行在任意节点的Impala daemon提交查询,这个节点将会作为这个查询的协调器(coordinator node),其他节点将会传输部分结果集给这个协调器节点。由这个协调器节点构建最终的结果集。在做实验或者测试的时候为了方便,我们往往连接到同一个Impala daemon来执行查询,但是在生产环境运行产品级的应用时,我们应该循环(按顺序)的在不同节点上面提交查询,这样才能使得集群的负载达到均衡。
Impala daemon不间断的跟statestore进行通信交流,从而确认哪个节点是健康的能接收新的工作任务。它同时接收catalogd daemon(从Impala 1.2之后支持)传来的广播消息来更新元数据信息,当集群中的任意节点create、alter、drop任意对象、或者执行INSERT、LOAD DATA的时候触发广播消息。
2.Impala Statestore
Impala Statestore检查集群各个节点上Impala daemon的健康状态,同时不间断地将结果反馈给各个Impala daemon。这个服务的物理进程名称是statestored,在整个集群中我们仅需要一个这样的进程即可。如果某个Impala节点由于硬件错误、软件错误或者其他原因导致离线,statestore就会通知其他的节点,避免其他节点再向这个离线的节点发送请求。
由于statestore是当集群节点有问题的时候起通知作用,所以它对Impala集群并不是有关键影响的。如果statestore没有运行或者运行失败,其他节点和分布式任务会照常运行,只是说当节点掉线的时候集群会变得没那么健壮。当statestore恢复正常运行时,它就又开始与其他节点通信并进行监控。
3.Impala Catalog
Imppalla catalog服务将SQL语句做出的元数据变化通知给集群的各个节点,catalog服务的物理进程名称是catalogd,在整个集群中仅需要一个这样的进程。由于它的请求会跟statestore daemon交互,所以最好让statestored和catalogd这两个进程在同一节点上。
catalog服务减少了REFRESH和INVALIDATE METADATA语句的使用。在之前的版本中,当在某个节点上执行了CREATE DATABASE、DROP DATABASE、CREATE TABLE、ALTER TABLE、或者DROP TABLE语句之后,需要在其它的各个节点上执行命令INVALIDATE METADATA来确保元数据信息的更新。同样的,当你在某个节点上执行了INSERT语句,在其它节点上执行查询时就得先执行REFRESH table_name这个操作,这样才能识别到新增的数据文件。
二、Impala的查询处理过程
如图是impala的查询处理过程。

三、查询计划
举个栗子
select count(*) from trace.apptalk
生成的执行计划
----------------
Estimated Per-Host Requirements: Memory=1.13GB VCores=1
WARNING: The following tables are missing relevant table and/or column statistics.
trace.apptalk
F01:PLAN FRAGMENT [UNPARTITIONED]
03:AGGREGATE [FINALIZE]
| output: count:merge(*)
| hosts=8 per-host-mem=unavailable
| tuple-ids=1 row-size=8B cardinality=1
|
02:EXCHANGE [UNPARTITIONED]
hosts=8 per-host-mem=unavailable
tuple-ids=1 row-size=8B cardinality=1
F00:PLAN FRAGMENT [RANDOM]
DATASTREAM SINK [FRAGMENT=F01, EXCHANGE=02, UNPARTITIONED]
01:AGGREGATE
| output: count(*)
| hosts=8 per-host-mem=10.00MB
| tuple-ids=1 row-size=8B cardinality=1
|
00:SCAN HDFS [trace.apptalk, RANDOM]
partitions=88/88 files=17578 size=67.11MB
table stats: unavailable
column stats: all
hosts=8 per-host-mem=1.13GB
tuple-ids=0 row-size=0B cardinality=unavailable
----------------
2016-03-26 17:30:00 hzct
作者:dantezhao | | CSDN | GITHUB
文章地址:http://www.jianshu.com/p/720df3b85b3a
个人主页:http://www.jianshu.com/u/2453cf172ab4
文章可以转载, 但必须以超链接形式标明文章原始出处和作者信息
