
本文经AI新媒体量子位(公众号ID:qbitai )授权转载,转载请联系出处。
近日,一名叫Matt Fraser的小哥用Cloud AutoML制作了一个分类器,能识别分类澳大利亚的各种毒蜘蛛。
在这篇文章中,小哥手把手教你如何在零基础的情况下也做一个图像分类器出来,非常简单容易上手,可以说是好玩又实用了。量子位将这篇文章全文翻译整理,与大家分享。
警告:这篇文章中包含蜘蛛(and蜘蛛侠)的照片,过敏患者请绕行

~

简介
两个月前,谷歌发布了全自动训练AI无需写代码的Cloud AutoML,即使你不懂机器学习,也能训练出一个定制化的机器学习模型了,这则消息当时还震惊了AI圈。
对,在这篇文章中,我就小露一手自己是怎样在几个小时之内,用开发利器Cloud AutoML训练出一个毒蜘蛛图片分类器的。在开始训练前我手头没有任何数据,它仅仅需要你对机器学习相关的基本概念有一个基础的了解。
我可能可以教会老妈也训练一个出来!
获取数据

获取数据是训练机器学习模型的第一步,可我不想跑去澳大利亚的丛林收集毒蜘蛛的照片。
怎么办!
幸好,谷歌还提供另外一个工具帮我做这件事:谷歌图像搜索

。
手动下载数百张照片也挺麻烦,所以我用了一个简单的Python脚本小工具批量下载了图片。
批量下载小工具代码:https://github.com/hardikvasa/google-images-download
我用“whitetail spider(白尾蜘蛛)”和“redback spider(红背蜘蛛)”关键词搜索,每种蜘蛛各搜集100张照片。
至此,获取数据这步完美通关。
如果你的很多图片是没有标记的,你可以将它们导入Cloud AutoML Vision服务中,然后选择Human Labeling Service人工打标签。
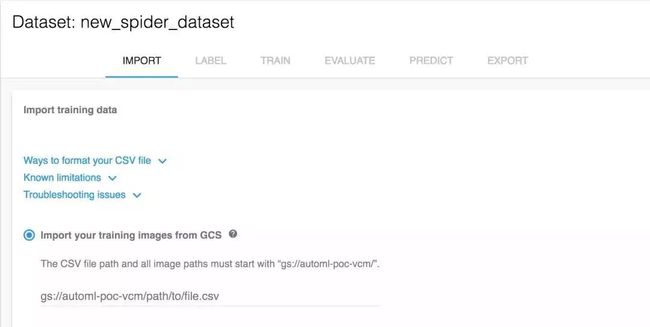
将数据集导入Cloud AutoML

Cloud AutoML先把搜集的照片放入谷歌云存储系统中,你可以用UI将图像导入这个工具。为了节约时间,我用gcloud command line tool将图像复制到系统里。
接下来,我需要包含每个图像bucket url和标签的CSV。谷歌图像搜索下载工具将其结果放入文件夹中,因此及我编写了一个脚本将文件的列表一一放在下面格式的CSV中,最后上传到同一个bucket里。
gs://my-automl-bucket/path/to/image,whitetailgs://my-automl-bucket/path/to/image,redback
之后我在Cloud AutoML中创建了一个新数据集,给出了我分类的CSV的位置:

训练模型

导入标记了的图像后,训练模型只需要“基础”和“高级”选项之间选择再一个,之后点击一下就能一键训练模型了。
我选择的是免费方案,不到20分钟我就收到了电子邮件,告知我的模型已经训练好了!
模型评估
模型训练好后,Cloud AutoML会提供一些不错的工具帮助评估模型是否有效。如果你之前了解过一些机器学习的相关概念,能帮助你更好完成这一步。
你也可以上传一些新照片检测模型是否能正确分类。我上传了下面两张图片,可以看出,虽然训练示例图像的像素很低,但运行效果还不错。
当给模型一张高脚蛛的图片时我有些困惑,因为这是它从未见过的品种。模型的整个“世界观”都是基于在训练集中提供的标签,所以不管给它什么,它都会根据这些标签做出预测。
我又给模型一张蜘蛛侠的照片,有趣的是我发现它有有点分不清了。
可不是嘛!

使用模型
训练完成后模型就会自动部署。这意味着只要你实现了模型的准确性,就可以通过Cloud Vision API指定模型在生产中使用它。理论上讲目前数据集还是太小,你需要更多种类蜘蛛的更多的照片才能保证效果。
结论
谷歌的Cloud AutoML Vision服务标志着机器学习技术向“人人可用”迈出了一大步。有了这样的工具,任何开发者可以轻松构建一个自定义图像分类的应用程序。
可能你不久之后就会在应用商店中看到“ Spiderapp”这个应用,到时候不要太惊讶

。
最后,附原文地址:
https://shinesolutions.com/2018/03/14/using-google-cloud-automl-vision-to-classify-poisonous-australian-spiders/amp/?__twitter_impression=true
End