一、path模块
1.path.normalize(path) 方法规范化给定的path,解析‘..’和‘.’片段。
当找到多个连续的路径段分隔符时,则它们将被替换为单个平台特定的路径段分隔符,尾部的分隔符会保留,如果path 是零长度的字符串,则返回'.',表示当前工作目录。
2.path.join([...paths]);方法使用平台特定的分隔符作为定界符将所有给定的path片段连接在一起,然后规范化生成的路径。零长度的path片段会被忽略,如果连接的路径字符串是零长度的字符串,则返回'.',表示当前工作目录。
3.path.reslove([...paths]);方法将路径或者路径皮那段的序列解析为绝对路径。
给定的路径序列从右到左进行处理,每个后续的path前置,直到构造处一个绝对路径
4.path.basename(path[,ext]);方法返回path的最后一部分,尾部的目录分隔符将被忽略。
5.path.dirname(path);方法返回path的目录名,尾部的目录分隔符被忽略 。
6.path.parse(path);方法返回一个对象,其属性表示path 的重要元素,尾部的目录分隔符将被忽略,返回的对象有以下属性(dir
7.path.format(pathObject);方法从对象返回路径字符串,与上面的parse相反
当为pathObject提供属性的时候,注意以下组合。其中一些属性优先于另一些属性。
如果提供了pathObject.dir 则忽略pathObject.root,也就是如果dir和root不一样时,采用dir的内容
如果pathObject.base 存在,则忽略pathObject.ext和pathObject.name 也就是如果base和ext,name不一样的时候,使用base 的内容。
8.path.sep 提供平台特定的路径片段分隔符
POSIX上面是/ windows上是\
9.path.delimiter 提供平台特定的路径定界符
‘;’用于Windows
‘:’用于POSIX
10.path.win32 属性提供对特定于Windows的path方法的实现的访问。
11.path.posix 属性提供对 path 方法的 POSIX 特定实现的访问。
12.__dirname、process.cwd()、./的区别

a、__dirname 和 __filename 总是返回文件的绝对路径
b、process.cwd() 总是返回执行node命令所在文件夹
c、./ 在require方法中总是相对当前文件所在文件夹,只跟在哪里调用的命令有关系,即和process.cwd() 一样,相对node启动文件夹
二、 Buffer
1.Buffer用于处理二进制数据流
2.实例类似整数数组,大小固定
3.C++ 代码在V8堆外分配物理内存
4.Buffer的大小在被创建时确定
5.Buffer类在Node.js中是一个全局变量,因此无需使用require('buffer').Buffer.
6.Buffer.alloc(size[,fill[,encoding]])
size: 新Buffer的所需长度(如果size不是数字 则抛出TypeError)
fill 用于预填充新Buffer的值 默认值是0
encoding 如果fill是一个字符串 则这是它的字符编码 默认值是utf8
7.Buffer.allocUnsafe(size)
size: 新建的Buffer的长度
以这种方式创建的Buffer实例的底层是未初始化的,新创建的Buffer的内容是未知的。而Buffer.alloc() 可以创建以0初始化的Buffer实例
调用Buffer.alloc() 可能比替代额Buffer.allocUnsafe() 慢得多,带能确保新创建的Buffer实例的内容永远不会包含敏感的数据。
8.Buffer.from() 有很多。。。
9.Buffer.byteLength(string[,encoding])
string:要计算的长度的值
encoding: 如果string是字符串,则这是它的字符编码 默认值是utf8
10.Buffer.isBuffer(obj);
如果obj是一个Buffer 则返回true 否则返回false
11.buf.length(); 返回内存中分配给buf 的字节数 不一定反应buf中可用数据的字节量。也就是开辟空间是多少 length就是多少,如果想改变一个Buffer的长度,应该将length视为只读的。
12.buf.toString([encoding[,start[,end]]])
encoding : 使用的字符编码 默认值是utf8
start:开始解码的字节偏移量 默认是0
end:结束解码的字节偏移量(不包含)默认值buf.length
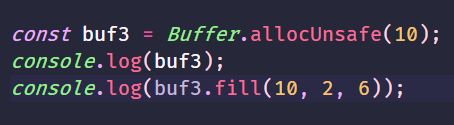
13.buf.fill(value[.offset[,end]][,encoding])
value:用来填充buf 的值
offset:开始填充bug 的偏移量 默认值是0
end:结束填充buf 的偏移量(不包含 默认值是buf.length)
encoding 如果value是字符串,则指定value的字符编码 默认值是utf8
返回buf 的引用
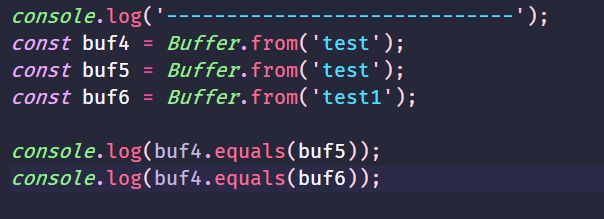
14.buf.equals(otherBuffer)
otherBuffer:
返回布尔值

15.buf.indexOf(value[,byteOffset][,encoding]);
value:要查找的值
byteOffset:buf中开始查找的偏移量 默认值是0
encoding 如果value是字符串 则制定value的字符编码 默认值是utf8
返回 bug中首次出现value的索引 如果buf没包含value则返回-1
16.彩蛋 !!!!
StringDecoder...解决中文乱码问题...
用于以保留编码的多字节 UTF-8 和 UTF-16 字符的方式将 Buffer 对象解码为字符串