Set是Java Collection下的一个子类

可以看到HashSet的继承关系, 而HashSet里有一个Filed是HashMap实例,用来存储HashSet的元素,即将Set里的值作为Key,value设置为null。怎么保证他的唯一性呢:
```
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
其实是通过HashMap的put来实现的, 而HashMap的put:
```
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab =table) ==null || (n = tab.length) ==0)
n = (tab = resize()).length;
if ((p = tab[i = (n -1) & hash]) ==null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key !=null && key.equals(k))))
e = p;
else if (pinstanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount =0; ; ++binCount) {
if ((e = p.next) ==null) {
p.next = newNode(hash, key, value, null);
if (binCount >=TREEIFY_THRESHOLD -1)// -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key !=null && key.equals(k))))
break;
p = e;
}
}
if (e !=null) {// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue ==null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size >threshold)
resize();
afterNodeInsertion(evict);
return null;
}
通过HashMap来保证元素的唯一性。
2. LinkedHashSet
其类图如下:
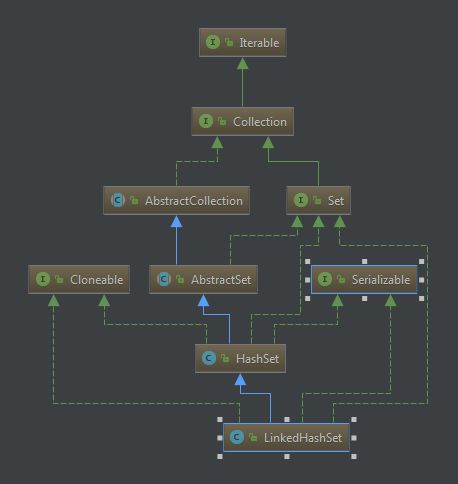
可以看出其继承自HashSet,那如何来维护顺序呢。其实在HashSet里有一个构造函数:
```
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map =new LinkedHashMap<>(initialCapacity, loadFactor);
}
这个构造函数被LinkedHashSet的所有构造函数调用,从而实现用LinkedHashMap来维护其数据,达到插入时数据的顺序。
3.TreeSet
其类图如下:
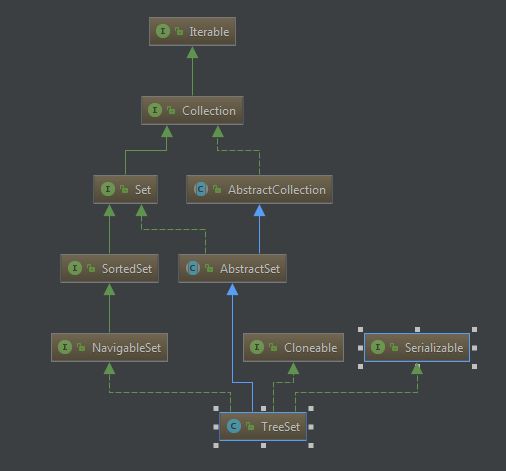
在TreeSet里有一个feild是TreeMap。其add方法如下:
```
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
其中m就是类型为TreeMap的field,其中PRESENT = new Object();
总结:
其实三种Set都是通过底层的Map来实现其值的唯一性,然后不同之处在于各个Set中维护其数据的Map根据不同Set的功能又各不相同。