在研究一个开源项目之前,都需要安装与配置基本的开发环境和源代码的阅读环境。这
一系列内容包括:安装与配置 JDK、安装开发调试 IDE、安装与配置相关辅助工具等。
1.2.1 安装与配置 JDK
在分析 Hadoop 的源代码前,需要做一些准备工作,其中搭建 Java 环境是必不可少的。
Hadoop 的运行环境要求 Java 1.6 以上的版本。打开http://www.oracle.com/technetwork/java/javase/downloads/index.html 页面,可以下载最新的 JDK 安装程序,下载页面如图 1-2 所示。
安装完后,要检查 JDK 是否配置正确。
某些第三方的程序会把自己的 JDK 路径加到系统 PATH 环境变量中,这样,即便安装最
新版本的 JDK,系统还是会使用第三方程序所带的 JDK。在 Windows 环境中,需要正确配
置的 Java 运行时环境变量有 JAVA_HOME、CLASSPATH 和 PATH 等。
方便起见,我们往往为操作系统本身指定一个系统级别的环境变量。例如,Windows 平
台上的系统环境变量可以在“系统属性”的“高级”选项卡中找到,可在其中配置 JAVA_
HOME、PATH 和 CLASSPATH 值。图 1-3 是 Windows XP 操作系统中为系统添加 JAVA_
HOME 环境变量的例子。
安装并配置完成后,可以在命令行窗口中输入“java -version”命令检测当前的 JDK 运
行版本。如果配置完全正确,会显示当前客户端的 JRE 运行版本,如图 1-4 所示。

1.2.2 安装 Eclipse
在 成 功 安 装 和 配 置 JDK 后, 还 需 要 安 装 进 行 Java 开 发 调 试 的 IDE(Integrated
Development Environment,集成开发环境),因为一个好的开发环境和源代码阅读环境可以
使工作效率事半功倍。目前比较常用的 Java 开发 IDE 主要有 Eclipse 和 NetBeans 等,读者
可以任意选择自己习惯的 IDE 作为开发工具。本书以 Eclipse 集成开发环境为例,着重介绍
在 Eclipse 中开发与调试源码的方法。读者也可以举一反三,在其他 IDE 中做相应的尝试。
Eclipse 是一个界面友好的开源 IDE,并支持成千上万种不同的插件,为代码分析和源
码调试提供了极大的便利。可以在 Eclipse 官方网站(http://www.eclipse.org/downloads/)
找到 Eclipse 的各个版本(对 Hadoop 源码进行分析,只需要下载 Eclipse IDE for Java SE
Developers)并下载安装。Eclipse 下载页面如图 1-5 所示。Eclipse 是基于 Java 的绿色软件,
解压下载得到 ZIP 包后就能直接使用。关于 Eclipse 的基本使用已超出了本书的范围,因此
下面仅向读者简要介绍如何使用 Eclipse 进行一些基本的源代码分析工作。
1. 定位某个类、方法和属性
在分析源代码的过程中,有时候需要快速定位光标位置的某个类、方法和属性,在
Eclipse 中可通过按 F3 键,方便地查看类、方法和变量的声明和定义的源代码。
有时候在查看一些在 JDK 库中声明 / 定义的类、方法和变量的源代码时,打开的却是
相应的 CLASS 文件(字节码),为此 Eclipse 提供了一个功能,把字节码和源代码关联起来,
这样,就可以查看(提供源代码)第三方库的实现了。
Eclipse 打开字节码文件时,可以单击“Attach Source”按钮进行字节码和源代码关联,
如图 1-6 所示。
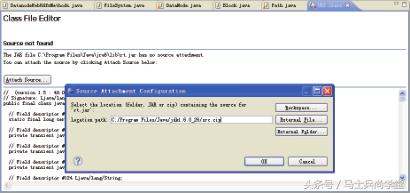
在查看 java.net.URL 时,Eclipse 提示代码关联,将 JDK 中附带的 JDK 源文件压缩包
(在安装目录下可以找到,名字是“src.zip”)绑定到“rt.jar”,以后,只要访问该 JAR 包中
的字节码文件,Eclipse 就会自动显示相应的源代码文件。
其他第三方 Java 插件的源代码文件的载入方法类似。
2. 根据类名查找相应的类
如果知道希望在编辑器中打开的 Java 类的名称,则找到并打开它的最简单的方法是使用快捷键 Ctrl+Shift+T(或者单击 Navigate → Open Type)打开 Open Type 窗口,在该窗口中
输入名称,Eclipse 将显示可以找到的匹配类型列表。图 1-7 显示了 Hadoop 1.0 中名字包含
“HDFS”的所有类。

注意 除了输入完整的类名之外,还可以使用“*”和“?”通配符来分别匹配“任何”或
“单个”字符。
3. 查看类的继承结构
Java 是面向对象的程序设计语言,继承是面向对象的三大特性之一,了解类、接口在继
承关系上的位置,可以更好地了解代码的工作原理。选中某个类并使用 Ctrl + T 快捷键(或
单击 Navigate → Quick Type Hierarchy)可以显示类型层次结构。
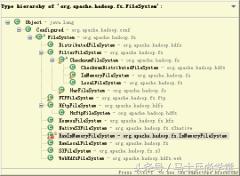
层次结构将显示所选元素的子类型。如图 1-8 所示,该列表显示已知的所有 org.apache.
hadoop.fs.FileSystem 子类。
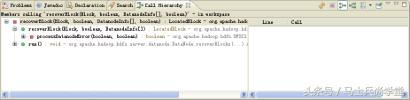
4. 分析 Java 方法的调用关系
在 Eclipse 中可以分析 Java 方法的调用关系,具体做法如下 :在代码区中选择相应的方
法定义,然后用鼠标右键选取 Open Call Hierarchy 项或者使用快捷键 Ctrl+Alt+H,则可以在
Call Hierarchy 视图中看到方法的调用关系,该视图还提供了一层一层的方法调用追溯功能,
对查找方法的相互调用关系非常有用,如图 1-9 所示。
注意 快捷键是日常开发调试中最为便捷的技巧。Eclipse 中的快捷键也可谓是博大精深,这
里不一一列举。读者可以在实际开发中不断摸索并牢记这些快捷键,因为它们也是日常开发
中必不可少的内容。读者也可参照 Eclipse 中的这些快捷键,在其他 IDE 中找到相应的快捷
键设置。
1.2.3 安装辅助工具 Ant
在安装和配置了 JDK 和 Eclipse 后,为了编译 Hadoop,还需要安装辅助工具 Ant。
对 Hadoop 这样复杂的项目进行构建,不是仅仅将 Java 源文件编译并打包这么简单,项
目中使用到的各种资源都需要得到合理的安排,如有些文件需要拷贝到指定位置,有些类需
要放入某个 JAR 归档文件,而另外一些类则需要放入另外一个 JAR 归档文件等,这些工作
如果全部由手工执行,项目的构建部署将会变得非常困难,而且难免出错。Ant 是针对这些
问题推出的构建工具,在 Java 的项目中得到了最广泛的使用。
Ant 跨平台、可扩展,而且运行高效,使用 Ant,开发人员只需要编写一个基于 XML 的
配置文件(文件名一般为 build.xml),定义各种构建任务,如复制文件、编译 Java 源文件、
打包 JAR 归档文件等,以及这些构建任务间的依赖关系,如构建任务“打包 JAR 归档文件”
需要依赖另外一个构建任务“编译 Java 源文件”。Ant 会根据这个文件中的依赖关系和构建
任务,对项目进行构建、打包甚至部署。
和 Hadoop 一 样,Ant 也 是 Apache 基 金 会 支 持 的 项 目, 可 以 在 http://ant.apache.org/
bindownload.cgi 下载,下载页面如图 1-10 所示。
和 Eclipse 类似,Ant 也是绿色软件,不需要安装,解压缩下载的文件后需要做一些配
置,用户需要添加环境变量 ANT_HOME(指向 Ant 的根目录),并修改环境变量 PATH(在
Windows 环境下,添加 %ANT_HOME%in 到 PATH 中)。安装并配置完成后,可以在命令行窗口中输入“ant -version”命令来检测 Ant 是否被正确设置。
Hadoop 的 Ant 还使用了一个工具:Apache Ivy,它是 Ant 的一个子项目,用于管理项目
的外部构建依赖项。外部构建依赖项是指软件开发项目的构建需要依靠来自其他项目的源代
码或 JAR 归档文件,例如,Hadoop 项目就依靠 log4j 作为日志记录工具,这些外部依赖项使
得构建软件变得复杂。对于小项目而言,一种简单可行的方法是将其依赖的全部项目(JAR
文件)放入一个目录(一般是 lib)中,但当项目变得庞大以后,这种方式就会显得很笨拙。
Apache 的另外一个构建工具 Maven 中,引入了 JAR 文件公共存储库的概念,通过外部依赖
项声明和公开的公共存储库(通过 HTTP 协议)访问,自动查找外部依赖项并下载,以满足
构建时的依赖需要。
Ivy 提供了 Ant 环境下最一致、可重复、易于维护的方法,来管理项目的所有构建依赖
项。和 Ant 类似,Ivy 也需要开发人员编写一个 XML 形式的配置文件(一般文件名为 ivy.
xml),列举项目的所有依赖项 ;另外还要编写一个 ivysettings.xml 文件(可以随意为此文件命名),用于配置下载依赖关系的 JAR 文件的存储库。通过 Ant 的两个 Ivy 任ivy:settings
和 ivy:retrieve,就可以自动查找依赖项并下载对应的 JAR 文件。
1.2.4 安装类 UNIX Shell 环境 Cygwin
对于在 Windows 上工作的读者,还需要准备类 UNIX Shell 环境的 Cygwin。
注意 在 Linux 等类 UNIX 系统中进行 Hadoop 代码分析、构建的读者可以略过这一节。
Cygwin 是用于 Windows 的类 UNIX Shell 环境,由两个组件组成 :UNIX API 库(它模拟 UNIX 操作系统提供的许多特性),以及在此基础上的 Bash Shell 改写版本和许多 UNIX
实用程序,它们一起提供了大家熟悉的 UNIX 命令行界面。Cygwin 的安装程序 setup.exe 是一个标准的 Windows 程序,通过它可以安装或重新安装软件,以及添加、修改或升Cygwin 组件。其下载页面为 http://cygwin.com/index.html,如图 1-11 所示。

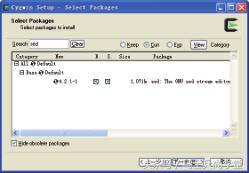
执行安装程序 setup.exe,并在安装程序的步骤 4(Cygwin Setup – Select Package)中选
择 UNIX 的在线编辑器 sed,如图 1-12 所示(可以利用 Search 输入框快速找到 sed)。
在安装 sed 时,setup.exe 会自动安装它依赖的包。在 Cygwin 中,可用的包超过 1000 个,
所以只需选择需要的类别和包,以后随时可以通过再次运行 setup.exe,添加整个类别或单独的包。在 Windows 下构建 Hadoop,只需要文本处理工具 sed。
安装完成后,使用 Start 菜单或双击 Cygwin 图标启动 Cygwin。可以在 Shell 环境中执行
“ant -version | sed "s/version/Version/g"”命令验证 Cygwin 环境,如图 1-13 所示。

成功安装 JDK、Eclipse、Ant 和 Cygwin 之后,就可以开始准备 Hadoop 源代码分析的
Eclipse 环境了。
这是给大家做的一个《Hadoop技术内幕》的分享,这本书是由我们的蔡斌和陈湘萍著作,大家想学Hadoop的可以在网上找这本书。
后续还会给大家上,敬请期待。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop也是后面其他技术的基础,学好了Hadoop才能更好地学好hive,hbase,spark,storm等。
【1】大家想了解Hadoop知识可以,关注我下方评论转发后,私信“资料”。
【2】部分资料有时间限制,抓紧时间吧!
感谢大家的支持!