前言
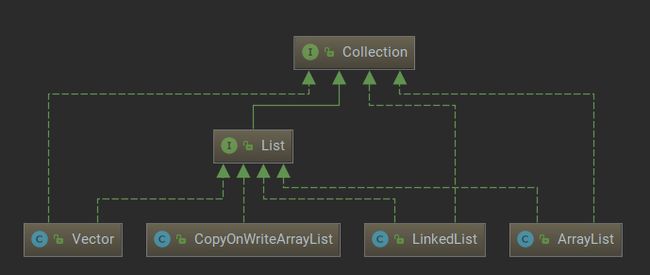
List 集合是线性数据结构的主要实现,集合元素通常存在明确的上一个和下一个元素,也存在明确的第一个和最后一个元素。
List的遍历结果是稳定的。
该体系最常用的是ArrayList和 LinkedList两个集合类。
Content
- 数组
- ArrayList
- 底层数据结构
- RandomAccess接口
- 老调常谈之ArrayList扩容
- 数组较之ArrayList否无用?
- ArrayList 与 Vector 对比
- LinkedList 与 ArrayList 对比
- List 几种遍历方式
- ArrayList 遍历基准测试
- LinkedList 遍历基准测试
- foreach 语法糖
- Arrays
带着问题思考
- 为什么数组是从0开始编号的?
- ArrayList 初始化长度是多少,底层实现和扩容机制?
- 你了解 ArrayList 实现的 RandomAccess 接口吗
- List 有几种遍历方式?有什么区别?
- Arrays.asList() 有什么坑?
- LinkedList 中的 Deque 接口是什么?
- ArrayList 和 Vector的区别?
- ArrayList 和 LinkedList 的区别?
一、数组
数组是一种顺序表。在各种高级语言中,它是组织和处理数据的一种常见方式。我们可以使用索引下标快速定位并获取指定的元素。
数组支持随机访问,根据下标随机访问的时间复杂度是O(1)。
为什么数组编号从0开始
从数组的内存模型来看,“下标”最确切的定义实际上应该是“偏移(offset)”。a[k] 就表示偏移 k 个 type_size 的位置。
从0开始时,计算a(k)的寻址公式:
a[k]_address = base_address + k * type_size
从1开始时,计算a(k)的寻址公式:
a[k]_address = base_address + (k-1)*type_size
可以看到,如果从1开始编号,每次随机访问数组元素都多了一次减法运算,对于CPU来说,就是多了一次减法指令。为了效率的优化,所以选择从0开始。
另外一个原因就是历史原因,最早C语言设计者用0开始计数数组下标,之后的高级语言都模仿了C。
二、ArrayList
ArrayList 是容量可以改变的非线程安全集合。
2.1 底层数据结构
ArrayList 底层使用的Object数组,默认大小 10。

2.2 RandomAccess接口

关于ArrayList 与 LinkedList 的对比当中,有一点就是,
是否支持快速随机访问:这个也是由底层实现决定的,LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于
get(int index)方法)。
而RandomAccess 接口 就是用来 标识该类支持快速随机访问。 查看源码可以发现,这个接口内部没有任何的定义。仅仅是起标识作用。

比如在Collections.binarySearch()方法中,

实现了RandomAccess接口的List使用索引遍历,而未实现RandomAccess接口的List使用迭代器遍历。
2.3 老调常谈 之 ArrayList 扩容机制
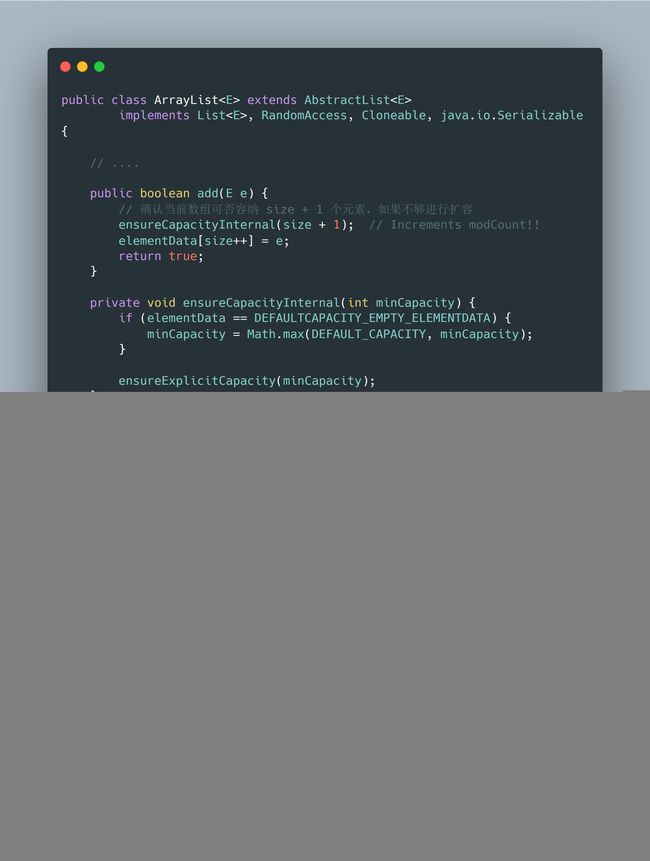
- 从
add()方法开始入手 -
ensureCapacityInternal(size + 1)确认当前数组可否容纳size + 1个元素,如果不够进行扩容 -
grow(minCapacity)这就是具体扩容的逻辑- 新容量的大小为
oldCapacity + (oldCapacity >> 1),也就是旧容量的1.5倍 - 扩容操作 需要 调用
Arrays.copyOf()这个方法,把原数组整个复制到新数组中,这个操作代价很高,所以 很多地方包括阿里开发手册上也会建议 在集合初始化的时候就指定好大概的容量大小,减少扩容的次数。
- 新容量的大小为
2.4 数组是否无用?
- ArrayList优势:1、将很多数组操作的细节封装起来了;2、支持动态扩容,1.5倍大小
- Java 的 ArrayList无法存储基本类型,比如int、long,需要封装为Integer、Long类,而AutoBoxing和Unboxing则有一定的性能消耗,如果极其关注性能,或者希望使用基本类型,可以选用数组。
- 如果数据大小事先已知,并且对数据的操作十分简单,用不到ArrayList的大部分方法,也可以选用数组
- 多维数组表示时,用数组往往会更加直观。比如
Object[][] array;而用容器的话则需要这样定义:ArrayList.array
对于业务开发,直接使用容器就足够了,省时省力,毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。除非是在做一些非常底层的开发。
三、ArrayList 与 Vector 对比
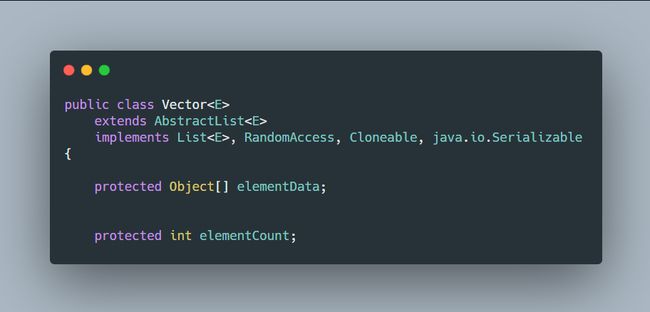
ArrayList 与 Vector 的底层实现都是 Object 数组,所以两者使用和特性上非常类似。
不同的是,
Vector 是线程安全的,内部使用了synchronized 进行同步。这导致了 Vector 性能非常不好。相比较的话,推荐用ArrayList,然后自己控制同步。
-
Vector 每次扩容都是2 倍大小,而不是1.5
 image
image
如果是想要达到线程安全的目的,Vector 有其他的替代方案:
- 使用
Collections.synchronizedList()得到一个线程安全的ArrayList(这类的Collections.synchronized***() 就是一层Wrapper,看源码就知道了) - 也可以使用J.U.C中的 CopyOnWriteArrayList 读写分离
四、LinkedList 与 ArrayList 对比
-
底层数据结构:
-
ArrayList 底层使用的Object数组,默认大小
10。 image
image -
LinkedList 底层使用的是双向链表数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别)。LinkedList 包含了3个重要的成员:
size、first、last。size是双向链表中节点的个数,first和last分别指向第一个和最后一个节点的引用。 image
image
-
-
插入和删除是否受元素位置的影响:
- 由于底层实现的影响,ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。比如:执行
add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。实际就是近似O(n)。 - 而LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)
- 由于底层实现的影响,ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。比如:执行
是否支持快速随机访问:这个也是由底层实现决定的,LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于
get(int index)方法)。内存空间占用:ArrayList的空间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放prev 指针和next 指针以及数据)。
LinkedList 和 ArrayList 的区别,再深一层探究实际上就是数组和链表的特性区别。
扩展阅读 http://note.youdao.com/noteshare?id=b05b5f48fd6c1fe7eb414fb6dcf75d34&sub=2D937C7AD377440090921E390008622F
五、LinkedList 中的 Deque 接口是什么?

与 ArrayList 相对应的,LinkedList 中也有一个值得好好研究的接口,那就是Deque 接口。
Deque - double-ended queue,中文名为双端队列。
我们都知道 Queue 是一个队列,遵循 FIFO 准则,我们也知道 Stack 是一个栈结构,遵循 FILO 准则。 而Deque 这个双端队列就厉害了, 它既可以实现栈的操作,也可以实现队列的操作,换句话说,实现了这个接口的类,既可以作为栈使用也可以作为队列使用。
如何作为队列使用呢? Deque 实现了 Queue,所以 Queue 所有的方法 Deque 都有,下面比较的是Deque区别 Queue 的方法:
| Queue | Deque |
|---|---|
| add(e) | addLast() |
| offer(e) | offerLast() |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
如何作为栈使用呢? 下面我们来看看下双端队列作为栈 Stack使用的时候方法对应关系。
| Stack | Deque |
|---|---|
| push(e) | addFist(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
因为篇幅有限,具体实现源码就不带大家去分析了。
扩展阅读 搞懂 Java LinkedList 源码
六、List 几种遍历方式
JMH(the Java Microbenchmark Harness): Java 的一个微基准测试框架。它能够照看好JVM的预热、代码优化,让你的测试过程变得更加简单。
package org.sample.jmh;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author Richard_yyf
* @version 1.0 2019/8/27
*/
@State(Scope.Benchmark) // 变量共享范围
@OutputTimeUnit(TimeUnit.SECONDS)
@Threads(Threads.MAX)
//@Warmup(iterations = 1, time = 3)
//@Measurement(iterations = 3, time = 3)
public class ArrayListIterationBenchMark {
private static final int SIZE = 10000;
private List list = new ArrayList<>(SIZE);
/*
@BenchmarkMode(Mode.All)
@BenchmarkMode({Mode.Throughput, Mode.SingleShotTime})
Throughput 每段时间执行的次数,一般是秒
AverageTime 平均时间,每次操作的平均耗时
SampleTime 在测试中,随机进行采样执行的时间
SingleShotTime 在每次执行中计算耗时
All 顾名思义,所有模式,这个在内部测试中常用 */
@Setup
public void setUp() {
for (int i = 0; i < SIZE; i++) {
list.add(String.valueOf(i));
}
}
@Benchmark
// @Fork(value = 1, warmups = 2) // 预热2轮,正式计量1轮
@BenchmarkMode(Mode.Throughput)
public void forIndexIterate() {
for (int i = 0; i < list.size(); i++) {
// System.out.print(list.get(i));
list.get(i);
System.out.print("");
}
}
@Benchmark
// @Fork(value = 1, warmups = 2)
@BenchmarkMode(Mode.Throughput)
public void forEachIterate() {
for (String s : list) {
// System.out.print(s);
System.out.print("");
}
}
@Benchmark
@BenchmarkMode(Mode.Throughput)
public void iteratorIterate() {
Iterator iter = list.iterator();
while (iter.hasNext()) {
// System.out.print(iter.next());
iter.next();
System.out.print("");
}
}
@Benchmark
@BenchmarkMode(Mode.Throughput)
public void lamdbdaIterate() {
list.forEach(s -> System.out.print(""));
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(ArrayListIterationBenchMark.class.getSimpleName())
.forks(1)
.warmupIterations(2)
.measurementIterations(2)
.build();
new Runner(opt).run();
}
}
ArrayList 遍历基准测试
Benchmark Mode Cnt Score Error Units
ArrayListIterationBenchMark.forEachIterate thrpt 2 1210.112 ops/s
ArrayListIterationBenchMark.forIndexIterate thrpt 2 1196.951 ops/s
ArrayListIterationBenchMark.iteratorIterate thrpt 2 1146.501 ops/s
ArrayListIterationBenchMark.lamdbdaIterate thrpt 2 1201.270 ops/s
LinkedList 遍历基准测试
Benchmark Mode Cnt Score Error Units
LinkedListIterationBenchMark.forEachIterate thrpt 2 1178.418 ops/s
LinkedListIterationBenchMark.forIndexIterate thrpt 2 210.769 ops/s
LinkedListIterationBenchMark.iteratorIterate thrpt 2 1202.520 ops/s
LinkedListIterationBenchMark.lamdbdaIterate thrpt 2 1155.121 ops/s
foreach 语法糖
原代码
@Benchmark
@BenchmarkMode(Mode.Throughput)
public void forEachIterate() {
for (String s : list) {
System.out.print("");
}
}
javap -c反汇编
public void forEachIterate();
Code:
0: aload_0
1: getfield #5 // Field list:Ljava/util/List;
4: invokeinterface #13, 1 // InterfaceMethod java/util/List.iterator:()Ljava/util/Iterator;
9: astore_1
10: aload_1
11: invokeinterface #14, 1 // InterfaceMethod java/util/Iterator.hasNext:()Z
16: ifeq 40
19: aload_1
20: invokeinterface #15, 1 // InterfaceMethod java/util/Iterator.next:()Ljava/lang/Object;
25: checkcast #16 // class java/lang/String
28: astore_2
29: getstatic #10 // Field java/lang/System.out:Ljava/io/PrintStream;
32: ldc #11 // String
34: invokevirtual #12 // Method java/io/PrintStream.print:(Ljava/lang/String;)V
37: goto 10
40: return
实际运行代码
Iterator iterator = list.iterator();
do
{
if(!iterator.hasNext())
break;
Object obj = iterator.next();
// 业务逻辑 瞎编的
if(canExecute()) {
list.remove(object)
}
} while(true);
七、Arrays / Collections
Arrays 是针对数组对象进行操作的工具类,包括数组的排序、查找、对比、拷贝等操作。尤其是排序,在多个JDK版本中,不断的进化,比如把原来的归并排序改成TimSort,明显的改变了集合的排序性能。另外可以通过这个工具类把数组转成集合。
Arrays.asList()
适配器模式
通过适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
Arrays.asList(T... a)体现的就是适配器模式。
拿生活中的例子作比方:我很早以前用的是3.5mm耳机孔的耳机,后面我换手机了,只能用type-c的耳机,通过type-c转接头我以前的耳机还是能用,这里面就用了适配器模式;在上面的例子中,入参数组就是3. 5mm耳机,Arrays.asList()这整个方法就是起到适配器type-c转接头的作用,List就是支持我type-c口的耳机。
容易踩的坑
数组与集合都是用来存储对象的容器,前者性质单一、简单易用;后者类型安全,功能强大,而两者之间必然有相互转换的方式。
由于两者的特性存在很大的差别,所以在转换过程当中,如果不去详细了解背后的转换方式,很容易产生意料之外的问题。
先来看一段代码:
/**
* Array.asList(T... a) 的坑
*
* @author Richard_yyf
* @version 1.0 2019/7/15
*/
public class ArrayAsListDemo {
public static void main(String[] args) {
String[] stringArray = new String[3];
stringArray[0] = "one";
stringArray[1] = "two";
stringArray[2] = "three";
List stringList = Arrays.asList(stringArray);
// 修改 转换后的集合
stringList.set(0, "oneList");
// 修改成功
System.out.println(stringArray[0]);
// 编译会通过
// add/remove/clear 方法会抛出 UnsupportedOperationException。
stringList.add("four");
stringList.remove(2);
stringList.clear();
}
}
上述代码可以证明可以通过set方法修改元素的值,原有数组相应位置的值同时也会被修改,但是不能进行修改元素个数的任何操作,否则就会抛异常。
// Arrays.asList() 源码
public static List asList(T... a) {
return new ArrayList<>(a);
}
有的人可能就会问了,返回的是ArrayList类,为什么不能对这个集合进行修改呢?
因为这个ArrayList并不是我们平常使用的ArrayList类,这里是个冒牌货,是Arrays工具类中的一个内部类而已。

这个类非常的简单,仅提供了改和查相关方法的实现,让我们来看一下:
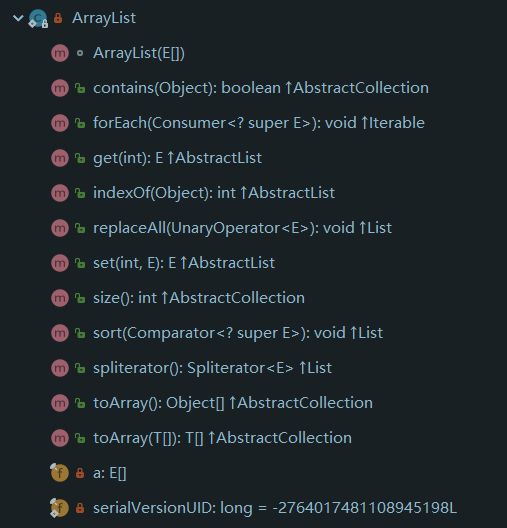
至于增删的操作会抛出会抛出UnsupportedOperationException,是在这个“假”类的父类AbstractList中实现的。
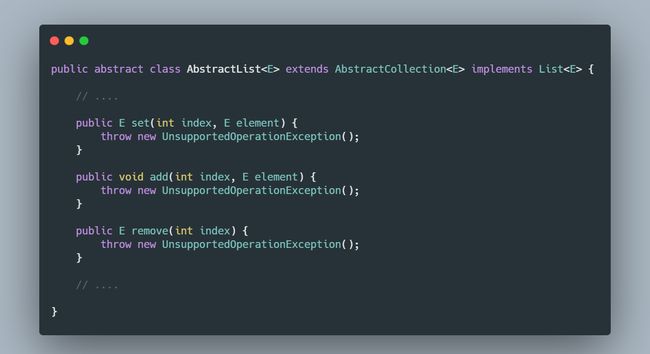
所以当你的业务场景中,数组转成集合之后,如果可能会对集合进行增和删的操作,请使用真ArrayList来创建一个新集合。