爬虫神器pyppeteer,对 js 加密降维打击
pyppeteer 是对无头浏览器 puppeteer 的 Python 封装。无头浏览器广泛用于自动化测试,同时也是一种很好地爬虫思路。
使用 puppeteer(等其他无头浏览器)的最大优势当然是 对 js 加密实行降维打击 ,完全无视 js 加密手段,对于一些需要登录的应用,也可以模拟点击然后保存 cookie。 而很多时候前端的加密是爬虫最难攻克的一部分 。当然puppeteer也有劣势,最大的劣势就是相比面向接口爬虫效率很低,就算是无头的chromium,那也会占用相当一部分内存。另外额外维护一个浏览器的启动、关闭也是一种负担。
在这推荐下小编创建的Python学习交流群835017344,可以获取Python入门基础教程,送给每一位小伙伴,这里是小白聚集地,每天还会直播和大家交流分享经验哦,欢迎初学和进阶中的小伙伴。
这篇文章我们来写一个简单的 demo,爬取拼多多搜索页面的数据,最终的效果如下:
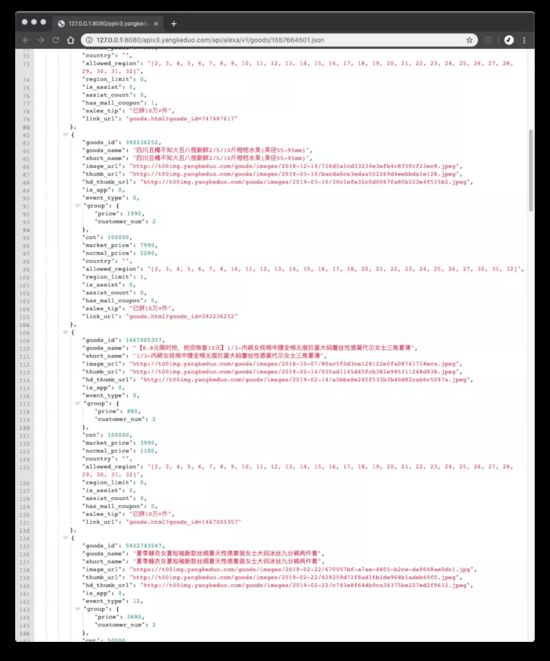
我们把所有 api 请求的原始数据保存下来:
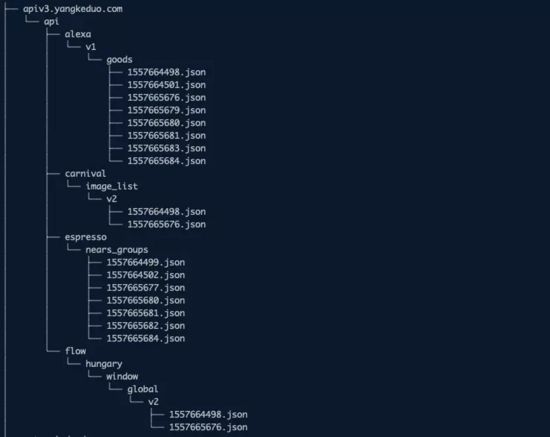
示例 json 文件如下:
开发环境
- python3.6+
最好是 python3.7,因为 asyncio 在 py3.7中加入了很好用的 asyncio.run() 方法。
- 安装pyppeteer
如果安装有问题请去看官方文档。
python3 -m pip install pyppeteer
- 安装 chromium
你懂的,天朝网络环境很复杂,如果要用 pyppeteer 自己绑定的 chromium ,半天都下载不下来,所以我们要手动安装,然后在程序里面指定 executablePath 。
下载地址: www.chromium.org/getting-inv…
hello world
pyppeteer 的 hello world 程序是前往 exmaple.com 截个图:
import asyncio
from pyppeteer import launchasync def main():
browser = await launch({
# Windows 和 Linux 的目录不一样,情换成自己对应的executable文件地址
'executablePath': '你下载的Chromium.app/Contents/MacOS/Chromium',
})
page = await browser.newPage()
await page.goto('http://example.com')
await page.screenshot({'path': 'example.png'})
await browser.close()asyncio.get_event_loop().run_until_complete(main())
pyppeteer 重要接口介绍
pyppeteer.launch
launch 浏览器,可以传入一个字典来配置几个options,比如:
browser = await pyppeteer.launch({
'headless': False, # 关闭无头模式
'devtools': True, # 打开 chromium 的 devtools
'executablePath': '你下载的Chromium.app/Contents/MacOS/Chromiu',
'args': [
'--disable-extensions',
'--hide-scrollbars',
'--disable-bundled-ppapi-flash',
'--mute-audio',
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-gpu',
],
'dumpio': True,
})
其中所有可选的 args 参数在这里: peter.sh/experiments…
dumpio 的作用:把无头浏览器进程的 stderr 核 stdout pip 到主程序,也就是设置为 True 的话,chromium console 的输出就会在主程序中被打印出来。
注入 js 脚本
可以通过 page.evaluate 形式,例如:
await page.evaluate("""
() =>{
Object.defineProperties(navigator,{
webdriver:{
get: () => false
}
})
}
""")
我们会看到这一步非常关键,因为 puppeteer 出于政策考虑(这个词用的不是很好,就是那个意思)会设置 window.navigator.webdriver 为 true ,告诉网站我是一个 webdriver 驱动的浏览器。有些网站比较聪明(反爬措施做得比较好),就会通过这个来判断对方是不是爬虫程序。
这等价于在 devtools 里面输入那一段 js 代码。
还可以加载一个 js 文件:
await page.addScriptTag(path=path_to_your_js_file)
通过注入 js 脚本能完成很多很多有用的操作,比如自动下拉页面等。
截获 request 和 response
await page.setRequestInterception(True)
page.on('request', intercept_request)
page.on('response', intercept_response)
intercept_request 和 intercept_response 相当于是注册的两个回调函数,在浏览器发出请求和获取到请求之前指向这两个函数。
比如可以这样禁止获取图片、多媒体资源和发起 websocket 请求:
async def intercept_request(req):
"""请求过滤"""
if req.resourceType in ['image', 'media', 'eventsource', 'websocket']:
await req.abort()
else:
await req.continue_()
然后每次获取到请求之后将内容打印出来(这里只打印了 fetch 和 xhr 类型response 的内容):
async def intercept_response(res):
resourceType = res.request.resourceType
if resourceType in ['xhr', 'fetch']:
resp = await res.text()
print(resp)
大家在学python的时候肯定会遇到很多难题,以及对于新技术的追求,这里推荐一下我们的Python学习扣qun:784758214,这里是python学习者聚集地
一共有哪些resourceType,pyppeteer文档里面有:

拼多多搜索爬虫
页面自动下拉
拼多多的搜索界面是一个无限下拉的页面,我们希望能够实现无限下拉页面,并且能够控制程序提前退出,不然一直下拉也不好,我们可能并不需要那么多数据。
js 脚本
async () => {
await new Promise((resolve, reject) => {
// 允许下滑的最大高度,防止那种可以无限下拉的页面无法结束
const maxScrollHeight = null;
// 控制下拉次数
const maxScrollTimes = null;
let currentScrollTimes = 0;
// 记录上一次scrollHeight,便于判断此次下拉操作有没有成功,从而提前结束下拉
let scrollHeight = 0;
// maxTries : 有时候无法下拉可能是网速的原因
let maxTries = 5;
let tried = 0;
const timer = setInterval(() => {
// 下拉失败,提前退出
// BUG : 如果网速慢的话,这一步会成立~
// 所以设置一个 maxTried 变量
if (document.body.scrollHeight === scrollHeight) {
tried += 1;
if (tried >= maxTries) {
console.log("reached the end, now finished!");
clearInterval(timer);
resolve();
}
}
scrollHeight = document.body.scrollHeight;
window.scrollTo(0, scrollHeight);
window.scrollBy(0, -10);
// 判断是否设置了maxScrollTimes
if (maxScrollTimes) {
if (currentScrollTimes >= maxScrollTimes) {
clearInterval(timer);
resolve();
}
}
// 判断是否设置了maxScrollHeight
if (maxScrollHeight) {
if (scrollHeight >= maxScrollHeight) {
if (currentScrollTimes >= maxScrollTimes) {
clearInterval(timer);
resolve();
}
}
}
currentScrollTimes += 1;
// 还原 tried
tried = 0;
}, 1000);
});
};
这里面有几个重要的参数:
- interval : 下拉间隔时间,以毫秒为单位
- maxScrollHeight : 运行页面下拉最大高度
- maxScrollTimes : 最多下拉多少次(推荐使用,可以更好控制爬取多少数据)
- maxTries : 下拉不成功时最多重试几次,比如有时候会因为网络原因导致没能在 interval ms 内成功下拉
把这些替换成你需要的。 同时你可以打开 chrome 的开发者工具运行一下这段 js 脚本 。
完整代码
这段代码一共也就只有70多行,比较简陋,情根据自己的实际需求更改。
import os
import time
import json
from urllib.parse import urlsplit
import asyncio
import pyppeteer
from scripts import scriptsBASE_DIR = os.path.dirname(file)
async def intercept_request(req):
"""请求过滤"""
if req.resourceType in ['image', 'media', 'eventsource', 'websocket']:
await req.abort()
else:
await req.continue_()async def intercept_response(res):
resourceType = res.request.resourceType
if resourceType in ['xhr', 'fetch']:
resp = await res.text()url = res.url tokens = urlsplit(url) folder = BASE_DIR + '/' + 'data/' + tokens.netloc + tokens.path + "/" if not os.path.exists(folder): os.makedirs(folder, exist_ok=True) filename = os.path.join(folder, str(int(time.time())) + '.json') with open(filename, 'w', encoding='utf-8') as f: f.write(resp)async def main():
browser = await pyppeteer.launch({
# 'headless': False,
# 'devtools': True
'executablePath': '/Users/changjiang/apps/Chromium.app/Contents/MacOS/Chromium',
'args': [
'--disable-extensions',
'--hide-scrollbars',
'--disable-bundled-ppapi-flash',
'--mute-audio',
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-gpu',
],
'dumpio': True,
})
page = await browser.newPage()await page.setRequestInterception(True) page.on('request', intercept_request) page.on('response', intercept_response) await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299') await page.setViewport({'width': 1080, 'height': 960}) await page.goto('http://yangkeduo.com') await page.evaluate(""" () =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) } """) await page.evaluate("你的那一段页面自动下拉 js 脚本") await browser.close()if name == 'main':
asyncio.run(main())