
使用Node.js制作爬虫教程(续:爬图)
前几天发了《使用Node.js制作爬虫教程》之后,有朋友问如果要爬文件怎么办,正好之前也写过类似的,那就直接拿过来写个续篇吧,有需要的可以借鉴,觉得不好的可以留言交流。
案例回顾
上一篇中,主要利用nodejs发起一个getData请求来得到4星角色的id列表。通过chrome开发者工具来查看页面结构,分析得出角色详细页面的URL规则和详细页面中想要抓取内容的位置。再循环遍历4星角色id列表去发起角色详细页面的请求并解析出想要收集的内容。
具体内容可再参考原文:使用Node.js制作爬虫教程
目标分析
案例回顾中提到的角色详细页面(参考样例),有不少图片内容,本文就以抓取“主动技能”的GIF图片为例,来改造一下前文的代码以完成定向抓取图片的效果。
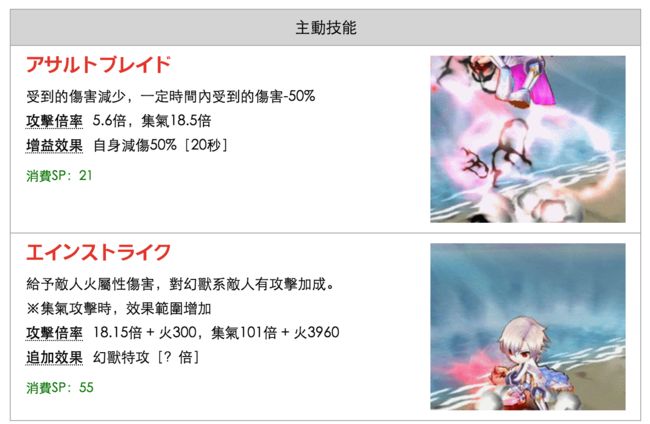
alt=
通过Chrome查看图片对象的URL规则为:/img/as2/角色id.gif
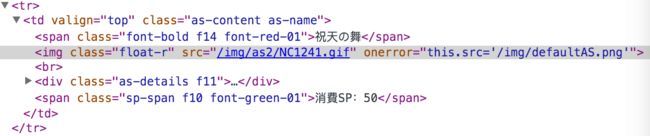
编码过程
构建工程和引入框架
$npm init
$npm install --save superagent
$npm install --save cheerio
$npm install --save async
上篇代码逻辑
- 发起getData.php请求,获得所有4星角色的ID
- 依次循环根据
char/角色id规则访问各个角色的详细页面,并解析其中需要的数据并按我们想要的方式存储起来
本篇代码逻辑:
- 发起getData.php请求,获得所有4星角色的ID
- 依次循环根据
/img/as2/角色id.gif规则下载gif文件到本地
所以,只要修改上篇代码中对每个角色对象的处理逻辑部分的内容为下载文件即可。
具体代码如下:
var superagent = require('superagent');
var cheerio = require('cheerio');
var async = require('async');
var fs = require('fs');
var request = require("request");
console.log('爬虫程序开始运行......');
// 第一步,发起getData请求,获取所有4星角色的列表
superagent
.post('http://wcatproject.com/charSearch/function/getData.php')
.send({
// 请求的表单信息Form data
info: 'isempty',
star : [0,0,0,1,0],
job : [0,0,0,0,0,0,0,0],
type : [0,0,0,0,0,0,0],
phase : [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
cate : [0,0,0,0,0,0,0,0,0,0],
phases : ['初代', '第一期','第二期','第三期','第四期','第五期','第六期', '第七期','第八期','第九期','第十期','第十一期','第十二期','第十三期','第十四期', '第十五期', '第十六期'],
cates : ['活動限定','限定角色','聖誕限定','正月限定','黑貓限定','中川限定','茶熊限定','夏日限定'] })
// Http请求的Header信息
.set('Accept', 'application/json, text/javascript, */*; q=0.01')
.set('Content-Type','application/x-www-form-urlencoded; charset=UTF-8')
.end(function(err, res){
// 请求返回后的处理
// 将response中返回的结果转换成JSON对象
var heroes = JSON.parse(res.text);
// 并发遍历heroes对象
async.mapLimit(heroes, 5,
function (hero, callback) {
// 对每个角色对象的处理逻辑
var heroId = hero[0]; // 获取角色数据第一位的数据,即:角色id
fetchInfo(heroId, callback);
},
function (err, result) {
console.log('抓取的角色数:' + heroes.length);
}
);
});
// 获取角色信息
var concurrencyCount = 0; // 当前并发数记录
var as2Url = 'http://wcatproject.com/img/as2/';
var fetchInfo = function(heroId, callback){
// 下载链接
var url = as2Url + heroId + '.gif';
// 本地保存路径
var filepath = 'img/' + heroId + '.gif';
// 判断文件是否存在
fs.exists(filepath, function(exists) {
if (exists) {
// 文件已经存在不下载
console.log(filepath + ' is exists');
callback(null, 'exists');
} else {
// 文件不存在,开始下载文件
concurrencyCount++;
console.log('并发数:', concurrencyCount, ',正在抓取的是', url);
request.head(url, function(err, res, body){
if (err) {
console.log('err: '+ err);
callback(null, err);
}
request(url)
.pipe(fs.createWriteStream(filepath))
.on('close', function(){
console.log('Done : ', url);
concurrencyCount --;
callback(null, url);
});
});
}
});
};
主要修改内容:
对fs模块和request模块的引用,前者用来读写文件,后者用来通过http请求获取文件。
var fs = require('fs');
var request = require("request");
fetchInfo函数修改成拼接url和本地保存路径,并通过request进行下载。
由于图片下载较慢修改并发数,async.mapLimit(heroes, 5, function (hero, callback)
执行情况如下,根据配置的并发数5,可以看到如下输出
$ node index.js
爬虫程序开始运行......
并发数: 1 ,正在抓取的是 http://wcatproject.com/img/as2/SS0441.gif
并发数: 2 ,正在抓取的是 http://wcatproject.com/img/as2/NS1641.gif
并发数: 3 ,正在抓取的是 http://wcatproject.com/img/as2/SS1141.gif
并发数: 4 ,正在抓取的是 http://wcatproject.com/img/as2/SS1041.gif
并发数: 5 ,正在抓取的是 http://wcatproject.com/img/as2/SS0941.gif
Done : http://wcatproject.com/img/as2/SS1141.gif
并发数: 5 ,正在抓取的是 http://wcatproject.com/img/as2/SS0841.gif
Done : http://wcatproject.com/img/as2/SS0841.gif
并发数: 5 ,正在抓取的是 http://wcatproject.com/img/as2/LS0941.gif
Done : http://wcatproject.com/img/as2/SS1041.gif
并发数: 5 ,正在抓取的是 http://wcatproject.com/img/as2/LS1441.gif
Done : http://wcatproject.com/img/as2/NS1641.gif
并发数: 5 ,正在抓取的是 http://wcatproject.com/img/as2/SS0741.gif
Done : http://wcatproject.com/img/as2/LS0941.gif
并发数: 5 ,正在抓取的是 http://wcatproject.com/img/as2/SS0641.gif
示例到此结束,有需要的去爬爬爬,至于爬什么我就不负责啦,_
代码参考:http://git.oschina.net/didispace/nodejs-learning