数据库三范式:
函数依赖
记 A->B 表示 A 函数决定 B,也可以说 B 函数依赖于 A。
如果 {A1,A2,... ,An} 是关系的一个或多个属性的集合,该集合函数决定了关系的其它所有属性并且是最小的,那么该集合就称为键码。
对于 A->B,如果能找到 A 的真子集 A',使得 A'-> B,那么 A->B 就是部分函数依赖,否则就是完全函数依赖;
对于 A->B,B->C,则 A->C 是一个传递函数依赖。

范式
范式理论是为了解决以上提到四种异常。
高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
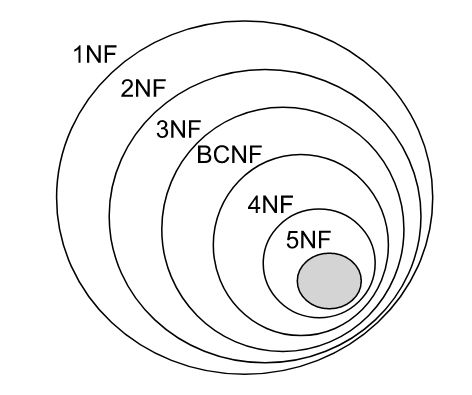
属性不可分;
1. 第一范式 (1NF)
属性不可分;
2. 第二范式 (2NF)
每个非主属性完全函数依赖于键码。
可以通过分解来满足。
分解前
| Sno | Sname | Sdept | Mname | Cname | Grade |
|---|---|---|---|---|---|
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
以上学生课程关系中,{Sno, Cname} 为键码,有如下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
- Sno, Cname-> Grade
Grade 完全函数依赖于键码,它没有任何冗余数据,每个学生的每门课都有特定的成绩。
Sname, Sdept 和 Mname 都部分依赖于键码,当一个学生选修了多门课时,这些数据就会出现多次,造成大量冗余数据。
分解后
关系-1
| Sno | Sname | Sdept | Mname |
|---|---|---|---|
| 1 | 学生-1 | 学院-1 | 院长-1 |
| 2 | 学生-2 | 学院-2 | 院长-2 |
| 3 | 学生-3 | 学院-2 | 院长-2 |
有以下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
关系-2
| Sno | Cname | Grade |
|---|---|---|
| 1 | 课程-1 | 90 |
| 2 | 课程-2 | 80 |
| 2 | 课程-1 | 100 |
| 3 | 课程-2 | 95 |
有以下函数依赖:
- Sno, Cname -> Grade
3. 第三范式 (3NF)
非主属性不传递函数依赖于键码。
上面的 关系-1 中存在以下传递函数依赖:Sno -> Sdept -> Mname,可以进行以下分解:
关系-11
| Sno | Sname | Sdept |
|---|---|---|
| 1 | 学生-1 | 学院-1 |
| 2 | 学生-2 | 学院-2 |
| 3 | 学生-3 | 学院-2 |
关系-12
| Sdept | Mname |
|---|---|
| 学院-1 | 院长-1 |
| 学院-2 | 院长-2 |
ER 图
Entity-Relationship,有三个组成部分:实体、属性、联系。
用来进行关系型数据库系统的概念设计。
实体的三种联系
包含一对一,一对多,多对多三种。
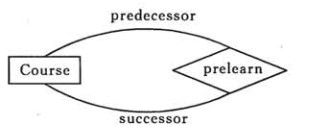
如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B;如果是一对一,画两个带箭头的线段;如果是多对多,画两个不带箭头的线段。下图的 Course 和 Student 是一对多的关系。

表示出现多次的关系
一个实体在联系出现几次,就要用几条线连接。下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。
联系的多向性
虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。

一般只使用二元联系,可以把多元关系转换为二元关系。

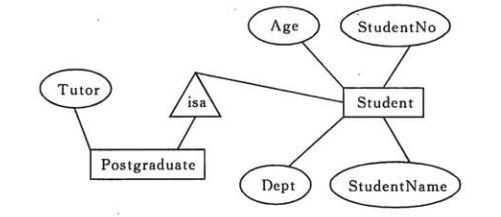
表示子类
用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。
InnoDB和MyISAM存储引擎的区别
- 事务
- InnoDB:支持
- MyISAM:不支持
- 锁粒度
- InnoDB:支持到行级
- MyISAM:只支持表级
- 外键
- InnoDB:支持
- MyISAM:不支持
- 保存总行数
- InnoDB :不保存
- MyISAM:保存
- 数据压缩
- InnoDB:不支持
- MyISAM:支持
- 存储结构
- MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
- InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
- 适用范围:InnoDB适合需要事务完整性,操作较丰富的场景。MyISAM则在查询较多的场景有着更好的性能
索引分类(主键、唯一索引、全文索引、覆盖索引等等),最左前缀原则,哪些条件无法使用索引
索引结构
- B+Tree索引:常用,数据存储在叶子节点
- Hash索引:不支持范围查找,不适合排序,mysql会使用hash索引来对B+Tree进行优化。
索引类型:
- 普通索引:最基本的索引,没有任何限制
- 唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
- 主键索引:它 是一种特殊的唯一索引,不允许有空值。
- 全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
索引优化
- 组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
- 覆盖索引:包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’。即只需扫描索引而无须回表。
聚簇索引与非聚簇索引
主索引的叶子节点data域记录着完整的数据记录,这种索引被称为聚簇索引,因为无法把数据行放到两个不同的地方,所以一个表只能有一个聚簇索引
辅助索引的叶子结点的data域记录着主键的值,因此在使用辅助索引进行查找时,需要先找到主键,然后在到主索引中进行查找
最左前缀匹配
推荐:https://www.jb51.net/article/142840.htm
B树、B+树区别
B Tree 指的是 Balance Tree,也就是平衡树。平衡树时一颗查找树,并且所有叶子节点位于同一层。
B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
进行查找操作时,首先在根节点进行二分查找,找到一个 key 所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出 key 所对应的 data。
插入删除操作记录会破坏平衡树的平衡性,因此在插入删除时,需要对树进行一个分裂、合并、旋转等操作。
与红黑树的比较
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree 作为索引结构,主要有以下两个原因:
(一)更少的检索次数
平衡树检索数据的时间复杂度等于树高 h,而树高大致为 O(h)=O(logdN),其中 d 为每个节点的出度。
红黑树的出度为 2,而 B+ Tree 的出度一般都非常大。红黑树的树高 h 很明显比 B+ Tree 大非常多,因此检索的次数也就更多。
(二)利用计算机预读特性
为了减少磁盘 I/O,磁盘往往不是严格按需读取,而是每次都会预读。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,并且只需要很短的旋转时间,因此速度会非常快。
操作系统一般将内存和磁盘分割成固态大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点,并且可以利用预读特性,相邻的节点也能够被预先载入。
事务的ACID
原子性
事务被视为不可分割的最小单元,事务的所有操作要么全部提交成功,要么全部失败回滚。
回滚可以用日志来实现,日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可。
一致性
数据库在事务执行前后都保持一致性状态。
在一致性状态下,所有事务对一个数据的读取结果都是相同的。
隔离性
一个事务所做的修改在最终提交以前,对其它事务是不可见的。
持久性
一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。
可以通过数据库备份和恢复来实现,在系统发生崩溃时,使用备份的数据库进行数据恢复。
事务隔离级别和各自存在的问题
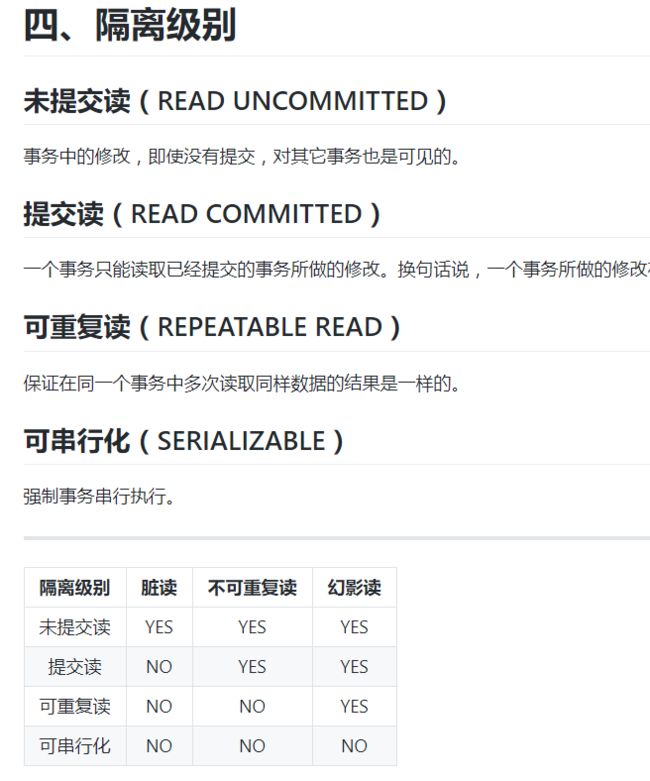
解决方法
MVCC(多版本并发控制)
MVCC是InnoDb存储引擎实现隔离级别的一种具体方式,用来实现提交读和可重复读两种隔离级别。
为提交读总是读取最新的数据行,无需使用MVCC,
可串行化直接对所有行加锁就好了。
-
SELECT
- Innodb检查每行数据,确保他们符合两个标准:
InnoDB只查找版本早于当前事务版本的数据行(也就是数据行的版本必须小于等于事务的版本),这确保当前事务读取的行都是事务之前已经存在的,或者是由当前事务创建或修改的行
行的删除操作的版本一定是未定义的或者大于当前事务的版本号,确定了当前事务开始之前,行没有被删除
- 符合了以上两点则返回查询结果。
INSERT
InnoDB为每个新增行记录当前系统版本号作为创建ID。DELETE
InnoDB为每个删除行的记录当前系统版本号作为行的删除ID。UPDATE
InnoDB复制了一行。这个新行的版本号使用了系统版本号。它也把系统版本号作为了删除行的版本。
说明
insert操作时 “创建时间”=DB_ROW_ID,这时,“删除时间 ”是未定义的;
update时,复制新增行的“创建时间”=DB_ROW_ID,删除时间未定义,旧数据行“创建时间”不变,删除时间=该事务的DB_ROW_ID;
delete操作,相应数据行的“创建时间”不变,删除时间=该事务的DB_ROW_ID;
select操作对两者都不修改,只读相应的数据
推荐:https://www.cnblogs.com/chenpingzhao/p/5065316.html
间隙锁
MVCC无法解决幻读的情况,可以在MVCC基础上使用间隙锁来在可重复读的隔离级别下解决幻读
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
举例来说,假如emp表中只有101条记录,其empid的值分别是 1,2,...,100,101,下面的SQL:
Select * from emp where empid > 100 for update;
是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
- innodb间隙锁就是不仅仅锁住所需要的行(如果锁住的这行不存在)还会锁住一个范围的行,这个范围依据锁住的这行而定。上下刚好是两个相邻索引叶节点的范围。包含下范围,不包含上范围。
两段锁协议
在事务执行的过程只,随时都可以执行锁定,锁只有在执行Commit或者ROLLBACK时才会释放,并且所有的锁都会在同一时刻释放。
乐观锁 被关索 共享锁 排他锁
乐观锁:设想不会发生并发冲突,所以不去上锁,但是一旦发现有冲突,就回滚。
悲观锁:假设总是有并发冲突,所以每次读写都要上锁,共享锁和排他锁都是悲观锁
共享锁:享锁又称为读锁,一个线程给数据加上共享锁后,其他线程只能读数据,不能修改。
排他锁:排他锁又称为写锁,和共享锁的区别在于,其他线程既不能读也不能修改。
手动加锁
- 共享锁:
SELECT ...LOCK IN SHARE MODE - 排他锁:
SElECT... FOR UNDATE
死锁的判定原理和具体场景
死锁是指两个或者多个事务在同一资源上互相作用,并请求锁定对方占用的资源,从而导致恶性循环的现象。当多个事务试图以不同的顺序锁定资源时,就有可能产生死锁。
场景:
事务1:
START TRANSCACTION;
UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 and date = '2018-03-03';
UPDATE StockPrice SET close = 12.45 WHERE stock_id = 3 and date = '2017-03-03';
COMMIT;
事务2:
START TRANSCACTION;
UPDATE StockPrice SET close = 13.35 WHERE stock_id = 3 and date = '2017-03-03';
UPDATE StockPrice SET close = 25.50 WHERE stock_id = 4 and date = '2018-03-03';
COMMIT;
如果事务1,和事务2都执行了第一条UPDATE语句,锁定了对应数据,接着每个事务都尝试去执行第二个语句,就会产生死锁。
- innodb支持死锁监测,如果发现死锁,便将持有最少行级排他锁的事务进行回滚,也就是影响行数最少的事务进行回滚。
查询缓慢和解决方式
- explain
- 慢日志查询
- show profile
drop、truncate、delete区别
drop直接删掉表
truncate删除表中数据,再插入时自增长id又从1开始
delete删除表中数据,可以加where字句。
查询语句不同元素(where、jion、limit、group by、having等等)执行先后顺序
SELECT的语法顺序就是起执行顺序
FROM
WHERE (先过滤单表/视图/结果集,再JOIN)
GROUP BY
HAVING (WHERE过滤的是行,HAVING过滤的是组,所以在GROUP之后)
ORDER BY
LIMIT
mysql优化
- explian 分析
主要字段- select_type:查询类型(简单查询,联合查询,子查询)
- key:使用的索引
- rows:扫描的行数
- 减少请求的数据量
- 最好不要使用SELECT *, 解析起来很麻烦,而且也无法使用覆盖索引
- 只返回必要的行
- 使用缓存缓存重复的数据
- 合理使用索引
- 切分大查询:如果某个查询时间过长,可能会锁住很多数据,占据大量事务日志
- 分解大连接查询
- 分库分表