在安装Hadoop,mysql,hive之前,首先要保证电脑上安装了jdk
一.配置jdk
1. 下载jdk
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2. 配置环境变量
(1)在终端使用 sudo su 命令进入root用户模式;
(2)使用 vim /etc/profile 命令打开profile文件,按下大写“I”进入编辑模式,在文件中添加以下信息:
JAVA_HOME对应的是你的JDK安装路径
JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/Home" CLASS_PATH="$JAVA_HOME/lib" PATH=".;$PATH:$JAVA_HOME/bin" export JAVA_HOME
(3)使用“esc”键推出编辑模式,按下“:”,输入wq并回车,保存且退出。
(4)退出终端并重新打开,输入java -version 命令查看jdk配置情况。

二.配置hadoop
1. 下载Hadoop
Hadoop 2.7.7镜像下载链接:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
2. 将下载后的压缩文件复制到/Users/finup/opt目录下并解压
3. 配置Hadoop
(1).进入/Users/finup/opt/hadoop-2.7.7/etc/hadoop/目录下,修改hadoop-env.sh配置文件
首先要查看JAVA_HOME的安装路径:
输入以下命令:/usr/libexec/java_home
/usr/libexec/java_home 结果:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home
然后修改hadoop-env.sh配置文件
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home" export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
(2).配置hdfs地址和端口
进入/Users/finup/opt/hadoop-2.7.7/etc/hadoop/目录下,修改core-site.xml配置文件
hadoop.tmp.dir file:/Users/finup/opt/hadoop-2.7.7/tmp Abase for other temporary directories. fs.defaultFS hdfs://localhost:9000
hadoop.tmp.dir 表示自己进程产生的一些数据要放入到该目录中
fs.defaultFS用于设置Hadoop的默认文件系统,设置为“hdfs://localhost:9000”。localhost表示namenade,9000表示端口号。 HDFS的守护程序通过该属性项来确定HDFS namenode的主机和端口。
(3).配置HDFS的默认参数副本数
进入/Users/finup/opt/hadoop-2.7.7/etc/hadoop/目录下,修改hdfs-site.xml配置文件
dfs.replication 1 dfs.namenode.name.dir file:/Users/finup/opt/hadoop-2.7.7/tmp/dfs/name dfs.datanode.data.dir file:/Users/finup/opt/hadoop-2.7.7/tmp/dfs/data
dfs.replication 表示复本数,文件会被保存为几分。dfs.replication的value设置为“1”,这样HDFS就不会按默认设置将文件系统块复本设置为3。否则在单独一个datanode上运行时,HDFS无法将块复制到3个datanode上,所以会持续给出块复本不足的警告。
(4).配置mapreduce中jobtracker的地址和端口
进入/Users/finup/opt/hadoop-2.7.7/etc/hadoop/目录下,修改mapred-site.xml.template配置文件
mapred.job.tracker localhost:9001
(5).修改配置文件 yarn-site.xml
进入/Users/finup/opt/hadoop-2.7.7/etc/hadoop/目录下,修改yarn-site.xml配置文件
yarn.nodemanager.aux-services mapreduce_shuffle
(6).文件系统初始化
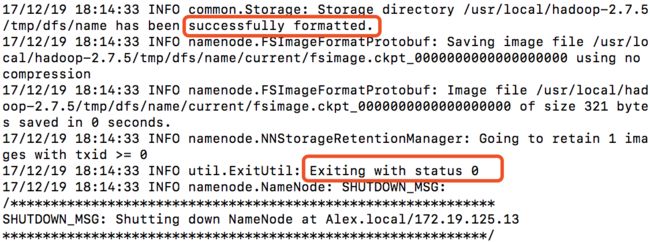
进入到Hadoop安装路径的bin目录下,使用命令 ./hadoop namenode -format 进行初始化,初始化成功会输出以下信息,注意红框标记处。
(7).配置Hadoop环境变量
目的是方便在任意目录下全局开启关闭hadoop相关服务,而不需要到/Users/finup/opt/hadoop-2.7.7/sbin下去执行启动或关闭命令。使用命令 vim ~/.zshrac 进行编辑,添加以下内容:(注意:zshrac是自己创建的,不要纠结自己找不到这个文件)
export HADOOP_HOME=/Users/finup/opt/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
然后使用source ~/.zshrac命令使修改生效,以上关于Hadoop的配置全部结束。
4.启动hadoop
(1).启动/关闭hadoop服务
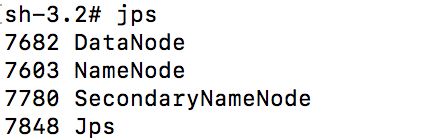
进入sbin目录下,使用./start-dfs.sh命令启动,然后使用jps查看启动结果,启动成功如下图所示:
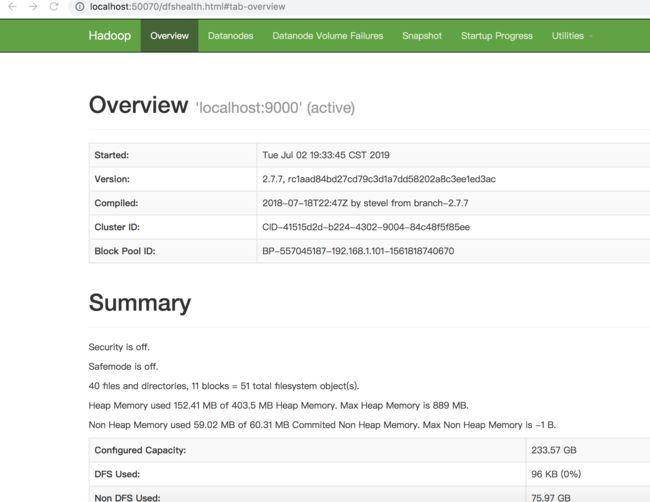
我们在浏览器中输入http://localhost:50070打开以下网页,可以查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
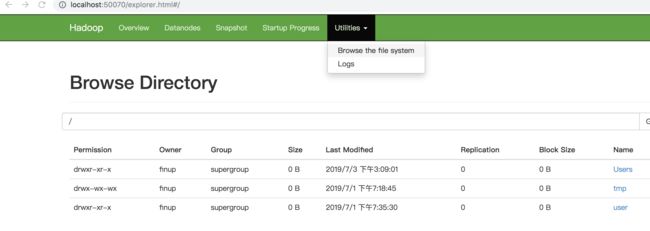
使用./stop-dfs.sh命令关闭hadoop服务
(2).启动/关闭yarn服务
使用./start-yarn.sh命令启动yarn服务,让 yarn来负责资源管理与任务调度。启动成功后,使用jps命令可以输出以下信息:
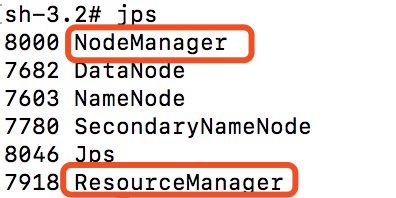
比之前只启动Hadoop服务时多了一个NodeManager和ResourceManager,然后在浏览器中打开http://localhost:8088,可以通过 Web 界面查看任务的运行情况。
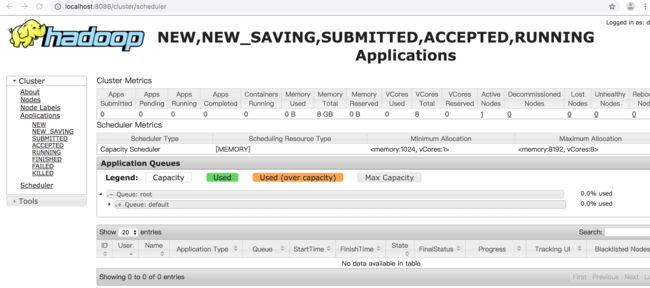
使用./stop-yarn.sh命令来关闭yarn服务。
(3) 快速启动和关闭
进入sbin目录下,直接使用命令 ./start-all.sh和./stop-all.sh命令可以同时启动和关闭hadoop和yarn服务,比依次启动和关闭方便很多。
三.安装mysql
可参考该链接:https://jingyan.baidu.com/article/fa4125ac0e3c2928ac709204.html
四.安装hive
首先要保证hadoop和mysql已经安装好了
1.在mysql数据库创建hive用户
mysql> create user 'hive' identified by 'hive';
2.将mysql的所有权限授权给hive用户
mysql> grant all on *.* to 'hive'@'localhost' identified by 'hive';
3.刷新mysql使1、2步骤生效
mysql> flush privileges;
4.输入sql语句查询hive用户是否存在
mysql> select host,user,authentication_string from mysql.user; +-----------+---------------+-------------------------------------------+ | host | user | authentication_string | +-----------+---------------+-------------------------------------------+ | localhost | root | *D391E96D137871ED52CDB352D867D3549815A718 | | localhost | mysql.session | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | | localhost | mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | | % | hive | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC | | localhost | hive | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC | +-----------+---------------+-------------------------------------------+
5.使用hive用户登录mysql
wudejin:~ oldsix$ mysql -u hive -p Enter password: hive mysql>
6.创建hive数据库
mysql> create database hive;
7.查看是否创建成功
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | hive | | mysql | | performance_schema | | sys | | test | +--------------------+ 6 rows in set (0.00 sec)
至此,前期的准备工作已完成,接下来,我们进入hive的安装过程。
8.下载hive安装包并解压
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/
下载完成后,通过命令行解压:
tar -zxvf apache-hive-3.1.1-bin.tar.gz
解压完成之后,对解压出来的文件夹重命名
mv apache-hive-3.1.1-bin hive3.1.1
9.修改hive配置:
进入hive3.1.1目录下的bin目录下,修改hive-site.xml配置文件
bin目录下不存在hive-site.xml文件,我们需要先复制一份:
cp hive-default.xml.template hive-site.xml
修改hive-site.xml文件:
--修改数据库连接驱动名 (配置文件中需要将该配置去掉)--修改数据库连接URL (配置文件中需要将该配置去掉) javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore --修改数据库连接用户名 (配置文件中需要将该配置去掉) javax.jdo.option.ConnectionURL jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8 JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. --修改数据库连接密码 (配置文件中需要将该配置去掉) javax.jdo.option.ConnectionUserName hive Username to use against metastore database --修改hive数据目录(三处) (配置文件中需要将该配置去掉) javax.jdo.option.ConnectionPassword hive password to use against metastore database hive.querylog.location /Users/finup/opt/hive3.1.1/iotmp Location of Hive run time structured log file hive.exec.local.scratchdir /Users/finup/opt/hive3.1.1/iotmp Local scratch space for Hive jobs --可以将表头显示出来 (配置文件中需要将该配置去掉) hive.downloaded.resources.dir /Users/finup/opt/hive3.1.1/iotmp Temporary local directory for added resources in the remote file system. hive.cli.print.header true Whether to print the names of the columns in query output.
10.配置hive环境变量
cd ~ sudo vi .base_profile
设置HIVE_HOME,并添加到PATH
export HIVE_HOME=/Users/finup/opt/hive3.1.1 export PATH=$PATH:$HIVE_HOME/bin
保存退出,并使环境变量生效
source .base_profile
11.将对应数据库的驱动包放到hive目录下的lib目录下
下载mysql-connector-java-8.0.16.jar,并上传至hive的lib目录下
12.初始化元数据库:schematool -dbType mysql -initSchema
13.进入hadoop安装目录,启动hadoop
/sbin/start-all.sh
14.启动hive
进入hive的bin目录下,执行命令: ./hive
15.退出hive命令
exit
hive (zcfw_sda)> exit;
四.安装sqoop
1. 安装和配置
brew install sqoop sqoop version cd /usr/local/Cellar/sqoop/1.4.6/libexec/conf cp sqoop-env-template.sh sqoop-env.sh vim sqoop-env.sh export HADOOP_HOME="/Users/finup/opt/hadoop-2.7.7" export HBASE_HOME="/usr/local" export HIVE_HOME="/Users/finup/opt/hive3.1.1" export HCAT_HOME="/usr/local" export ZOOCFGDIR="/usr/local/etc/zookeeper" export ZOOKEEPER_HOME="/usr/local/opt/zookeeper"
2. 测试
sqoop list-tables --connect jdbc:mysql://localhost/test --username root --password ***** sqoop eval --connect jdbc:mysql://localhost/test --username root --password ***** --query "select * from test.student"
3. 遇到的问题
问题1
java.lang.Exception: java.lang.RuntimeException:java.lang.ClassNotFoundException: Class example not found
原因和解决方法:hadoop 单机模式下无法找到执行目录,切换到伪分布模式可以解决
问题2
No primary key could be found for table test_table. Please specify one with –split-by or perform a sequential import with ‘-m 1’.
原因和解决方法:sqoop导入时依赖于MySQL原表的主键索引进行切片,没有添加主键索引会报错,给原表加上 primary key 或者 在 命令行末尾 加上 -m 1
4. 导入实例
# 创建mysql表 CREATE TABLE `example` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 # 插入数据 mysql> select * from example; +----+-------+ | id | name | +----+-------+ | 1 | hello | | 2 | world | +----+-------+ 2 rows in set (0.00 sec) # 创建 hive 表 create table example(id int, name string) row format delimited fields terminated by '\t' lines terminated by '\n'; # 将mysql表导入hadoop sqoop import -connect jdbc:mysql://localhost/test --username root --password mima123456 --table example # 将生成的文件导入hive load data inpath 'hdfs://localhost:9000/user/max/example/part-m-00000' into table example # 以上两步可以合并为一步完成 sqoop import --connect jdbc:mysql://localhost/test --username root --password mima123456 --table example --hive-import --hive-overwrite --hive-table example --fields-terminated-by '\t'