1.软件版本
| 软件 | 版本号 |
|---|---|
| jdk | 1.8.x |
| scala | Scala 2.11.12 |
| zookeeper | 3.4.10 |
| kafka | 2.11_0.11.0.1 |
| hadoop | 2.6.5 |
| spark | 2.3 spark-2.3.0-bin-hadoop2.6.tgz |
| storm | 1.2.1 |
2.系统环境
演示安装环境如下:
五台系统centos7 linux机,主机名称和分布为:
192.168.139.136 hadoop001
192.168.139.135 hadoop002
192.168.139.137 hadoop003
192.168.139.138 hadoop004
192.168.139.139 hadoop005
每个机器安装软件内容
hadoop001 jdk scala hadoop spark storm
hadoop002 jdk scala hadoop spark storm
hadoop003 jdk scala zookeeper kafka hadoop spark storm
hadoop004 jdk scala zookeeper kafka hadoop spark storm
hadoop005 jdk scala zookeeper kafka hadoop spark storm
##root 用户下 修改主机名称 vi /etc/hostname 或者
hostnamectl set-hostname Hadoop001
2.1创建用户
安装、运维及监控皆需使用hadoop用户。
root用户下执行如下命令进行添加hadoop用户。
useradd hadoop
passwd hadoop (输入两遍密码)
或者使用一条命令直接给用户添加密码
echo hadoop_password \| passwd --stdin hadoop
开发用户可选用其他新建用户。
echo test\| passwd --stdin test
2.2 hosts映射
Linux系统在向DNS服务器发出域名解析请求之前会查询/etc/hosts文件,如果里面有相应的记录,就会使用hosts里面的记录。/etc
/hosts文件通常里面包含这一条记录。
root用户下进行操作。
修改五台机器的 /etc/hosts文件
#第一列为IP地址,后面每列皆为ip地址的hostname别名
vi /etc/hosts

2.3 关闭防火墙
root用户下操作。
1.关闭防火墙服务
service iptables stop
2.设置防火墙服务器开机不自动启动
chkconfig iptables off
Centos7版本的防火墙服务有iptables还有firewalld
*systemctl stop firewalld \#\#关闭防火墙*
*firewall-cmd --state \#\#查看状态*
*systemctl disabled firewalld*
*如果关闭防火墙的话 这两个服务都得关闭掉*
2.4 配置ssh集群免密
Hadoop用户下:
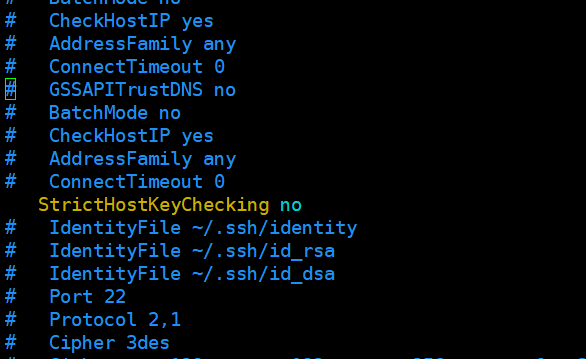
步骤1:root下修改文件:vi /etc/ssh/ssh_config
在文件中添加或修改如下信息: StrictHostKeyChecking no
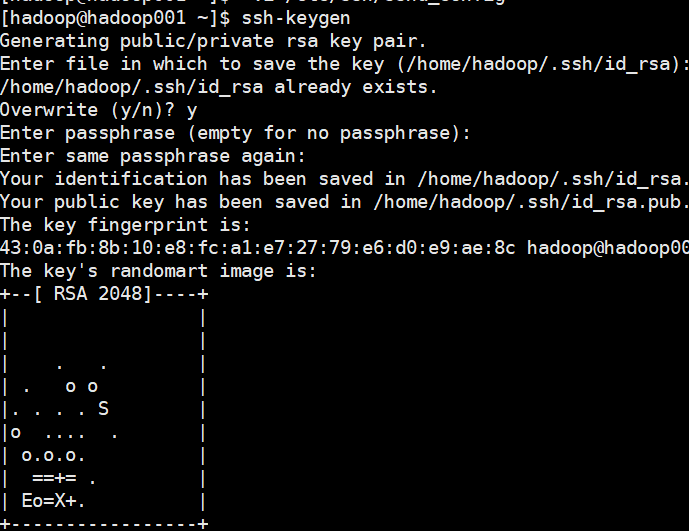
步骤2: 以下操作都在hadoop用户下用 ssh-key-gen 在本地主机上创建公钥和密钥
所有主机分别执行
ssh-keygen
点击三次回车
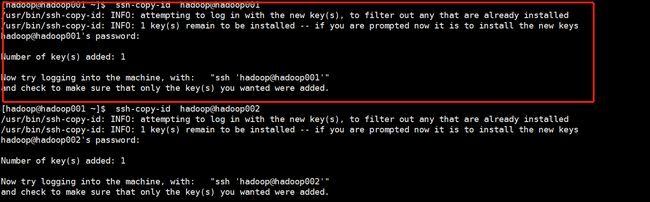
步骤3: 用 ssh-copy-id 把公钥复制到远程主机上
所有主机分别执行
ssh-copy-id hadoop\@hadoop001
ssh-copy-id hadoop\@hadoop002
ssh-copy-id hadoop\@hadoop003
ssh-copy-id hadoop\@hadoop004
ssh-copy-id hadoop\@hadoop005
步骤4: 直接登录远程主机
测试 ssh Hadoop005
[图片上传失败...(image-8e419a-1541662131260)]
3.安装部署
1.创建目录
mkdir -p /opt/wsqt/core -- 软件程序位置
mkdir -p /opt/wsqt/log -- 日志位置
mkdir -p /opt/wsqt/data -- 数据位置
目录树如下:
/opt/wsqt/
|----------conf/
|-----wsqt_env ##(hadoop集群相关环境变量文件)
|----------core/
|-----hadoop ## (hdfs与yarn目录)
|-----hbase ## (hbase目录)
|-----jdk ## (java目录)
|-----spark ## (spark目录)
|-----zookeeper ## (zookeeper目录)
|-----storm ## (storm目录)
|----------data/
|-----journal ##(journalnode服务存放的数据目录,同步主备节点namenode数据)
|-----namenode ##(namenode服务存放的数据目录,其他临时数据的默认目录)
|-----yarn ##(yarn执行job任务时临时数据目录)
|-----storm ##(storm临时数据目录)
|-----zookeeper ##(zookeeper数据目录)
|----------logs/ ##(日志文件目录)
|-----hadoop
|-----yarn
|-----zookeeper
|-----hbase
|-----spark
|-----storm
2.更改权限
chown -R hadoop:hadoop /opt/wsqt
##由于集群内所有的节点上都需要安装,但是配置文件基本都是一样的,所以可以在一台服务器上把配置文件修改完毕,然后压缩打包传至其他服务器,再根据各个服务器的实际情况略作修改。
3.环境变量
##此步必须在所有集群服务器都已存在软件包之后设置,否则环境变量重载的时候会出问题。切记!。
/home/hadoop/.bash_profile ##对应login-bash
/home/hadoop/.bashrc ##对应nologin-bash
vi \~/.bash\_ profile
| # .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi # User specific environment and startup programs PATH=$PATH:$HOME/.local/bin:$HOME/bin export PATH #set JAVA_HOME export JAVA_HOME=/opt/wsqt/core/java export ZOOKEEPER_HOME=/opt/wsqt/core/zookeeper export KAFKA_HOME=/opt/wsqt/core/kafka export REDIS_HOME=/opt/wsqt/core/redis export HADOOP_HOME=/opt/wsqt/core/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SCALA_HOME=/opt/wsqt/core/scala export SPARK_HOME=/opt/wsqt/core/spark export STORM_HOME=/opt/wsqt/core/storm export PATH=$KAFKA_HOME/bin:$STORM_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$SCALA_HOME/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$REDIS_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HO ME/sbin:$PATH |
|---|
~
~
JDK安装
1下载
http://www.oracle.com/technetwork/java/javaee/downloads/index.html
2 查看版本
java -version
如果显示:
openjdk version "1.8.0_102"
OpenJDK Runtime Environment (build 1.8.0_102-b14)
OpenJDK 64-Bit Server VM (build 25.102-b14, mixed mode)
3检测jdk安装包
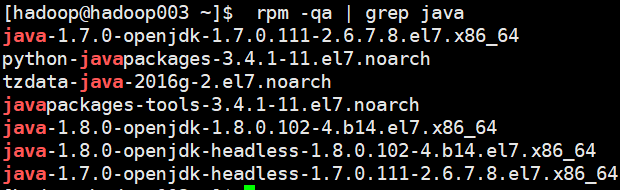
4卸载 对应OpenJDK版本
rpm -e --nodeps tzdata-java-2016g-2.el7.noarch
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
5安装
mkdir -p /opt/wsqt/core/java
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /opt/wsqt/core/java
6 设置环境变量
参考 3.环境变量配置
7 执行profile文件
source /etc/profile
8 检查新装jdk
Scala安装
1 下载
地址https://www.scala-lang.org/download/2.11.12.html
2 安装
mkdir -p /opt/wsqt/core/scala
tar -zxvf
scala-2.11.12.tgz
-C /opt/wsqt/core/scala
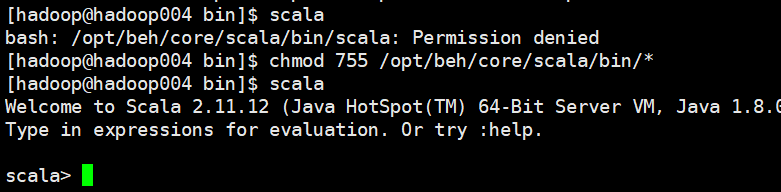
3 给执行文件授权
如出现

chmod 755 /opt/wsqt/core/scala/bin/\*
4 检查
zookeeper安装
1下载
地址https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
2 解压
mkdir -p /opt/wsqt/core/zookeeper
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/wsqt/core/zookeeper
3 修改配置文件
cd zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
添加内容如下:
| tickTime=4000 initLimit=20 syncLimit=10 ##这个目录存放zookeeper的数据,以及myid配置文件。此目录若没有则必须手动创建。 dataDir=/opt/wsqt/data/zookeeper clientPort=2181 server.1=hadoop003:2888:3888 server.2=hadoop004:2888:3888 server.3=hadoop005:2888:3888 |
|---|
4 创建文件夹并添加myid文件
mkdir -p /opt/wsqt/data/zookeeper
mkdir -p /opt/wsqt/log/zookeeper
5 在data文件夹下新建myid文件,myid的文件内容为:
Hadoop003机器上
echo '1' \> /opt/wsqt/data/zookeeper/myid
添加内容:
| 1 |
|---|
6 将集群下发到其他机器上
scp -r /opt/wsqt/core/zookeeper hadoop\@hadoop004: /opt/wsqt/core/
scp -r /opt/wsqt/core/zookeeper hadoop\@hadoop005: /opt/wsqt/core/
修改其他机器的配置文件
到hadoop004上:修改myid为:2
到hadoop005上:修改myid为:3
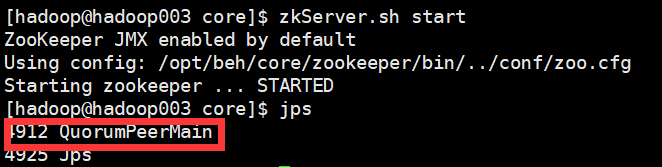
7 启动(每台机器)
zkServer.sh start
8 查看集群状态
jps(查看进程)zkServer.sh status(查看集群状态,主从信息)

部署为三篇:
- 软件版本、系统环境、jdk、scala、zookeeper
https://www.jianshu.com/p/8a1f1b40073f - hadoop安装
https://www.jianshu.com/p/c88c208ba68c - Kafka Spark Flume安装
https://www.jianshu.com/p/ea8c2a4e0bf8