| 2020春W班 (福州大学) | |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2020SpringW/homework/10281 |
| 这个作业的目标 | 学习Git,Gitdesktop使用、完成疫情统计系统、学会单元测试 |
| 作业正文 | https://www.cnblogs.com/lxbxyz/p/12329123.html |
| 其他参考文献 | Java 教程 | 菜鸟教程、《码出高效_阿里巴巴Java开发手册》、单元测试和回归测试、Git使用教程 |
一、GitHub仓库地址
https://github.com/cybin007/InfectStatistic-main
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 25 |
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 720 | 500 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 100 |
| Design Spec | 生成设计文档 | 30 | 25 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| Design | 具体设计 | 120 | 100 |
| Coding | 具体编码 | 480 | 550 |
| Code Review | 代码复审 | 60 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 20 |
| Reporting | 报告 | 30 | 20 |
| Test Report | 测试报告 | 30 | 20 |
| Size Measurement | 计算工作量 | 30 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1800 | 1525 |
三、解题思路
程序主要包含3块内容:读取文件,处理文件,输出文件
日志文件的数据存储在一个省份类Province的数组中,省份类中有数据成员包括省份名,感染人数,疑似人数,治愈人数,死亡人数,是否在日志文件中出现,-province参数中是否包含该省份。每个省份类的对象对应一个省份。
读取函数读取日志文件每一行交给日志处理函数来处理,日志处理函数将日志文件中的信息转化为对象中的信息。输出函数将对象中的信息转换为文件
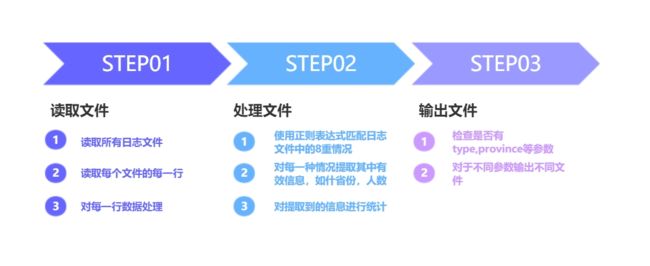
1.读取文件
读取文件主要是对读取给定目录下的所有日志文件,日志文件中的每一行进行处理,然后使用日志统计函数进行处理。读取文件功能就是负责取出日志文件的每一行,然后交给日志统计函数统计。
2.统计日志
将读取的日志按行处理。使用正则表达式来匹配日志文件中出现的以下八种情况: 1、<省> 新增 感染患者 n人 2、<省> 新增 疑似患者 n人 3、<省1> 感染患者 流入 <省2> n人 4、<省1> 疑似患者 流入 <省2> n人 5、<省> 死亡 n人 6、<省> 治愈 n人 7、<省> 疑似患者 确诊感染 n人 8、<省> 排除 疑似患者 n人
使用split函数将每一行分为若干部分。人数使用Interger.parseInt()函数转化为数字。将日志文件中的提取到的数据存到各个省份类的对象中。
3.输出文件
取出将对象中的信息,根据传入参数-out,-province,-type等输出用户所需要的文件。
四、设计实现过程
1.设计一个省份类Province用于存储感染人数,疑似人数,治愈人数,死亡人数等。设置构造函数。
class Province {
String name; //省份名称
int ip; //感染人数
int sp; //疑似人数人数
int cure; //治愈人数
int dead; //死亡人数
boolean status; //省份是否在日志文件出现过
boolean showstatus; //-province参数中是否包含该省份
Province(String name) {
this.name=name;
this.ip=0;
this.sp=0;
this.cure=0;
this.dead=0;
this.status=false;
this.showstatus=false;
}
}
省份类数组存储各个省份的疫情信息
static Province[] provincelist=new Province[provinces.length];
2.设计一个命令读取函数public static void readCommand(String[] args)实现对命令的读取以及解析。解析命令行输入的参数的实现不需要正则表达式。因为读取进来的命令格式较为固定,必须在开始有list,如果没有list则报错。读取log(日志目录)参数只需在字符数组中寻找-log字符,下一个字符串即是日志存储的地址。其它参数也是通过类似的方法来读取。
3.设计一个读取文件的函数public static void readFile(String path),读取给定path目录下的所有日志文件,日志文件中的每一行进行处理,然后交给日志统计函数进行处理。
4.设计一个省份初始化函数static void provinceInit()对省份类数组的各个对象进行初始化
static void provinceInit() {
for(int i=0;i provincelist[i]=new Province(provinces[i]);
}
}
5.设计一个省份序号查找static int findProvince(String provincename),来查询某名字的省份所对应的省份类数组的下标。
6.设计一个数据处理统计函数static void statistic(String line),对日志文件中的每一行进行处理。函数主要使用正则表达式来匹配字符串。
String p="\\\\";
String p1=".*新增 感染患者.*";
String p2=".*新增 疑似患者.*";
String p3=".*感染患者 流入.*";
String p4=".*疑似患者 流入.*";
String p5=".*死亡.*";
String p6=".*治愈.*";
String p7=".*疑似患者 确诊感染.*";
String p8=".*排除 疑似患者.*";
对于匹配的字符串,使用split函数将其变为字符串数组。然后在数组中提取省份,人数等信息,将其存储在省份类数组中的对象上。
7.设计一个输出函数static void outputFile(String out,StringBuffer stype,StringBuffer sprovince)对疫情信息进行输出。out,stype,sprovince之前均由readCommand函数处理得出。对于out参数可以直接使用。stype参数要使用split函数变成字符串数组,判断包含sp,ip,cure,dead中的那几个字符串,决定输出。对于sprovince也是类似。
五、代码说明
1.声明省份类
class Province {
String name; //省份名称
int ip; //感染人数
int sp; //疑似人数人数
int cure; //治愈人数
int dead; //死亡人数
boolean status; //省份是否在日志文件出现过
boolean showstatus; //-province参数中是否包含该省份
Province(String name) {
this.name=name;
this.ip=0;
this.sp=0;
this.cure=0;
this.dead=0;
this.status=false;
this.showstatus=false;
}
}
2.读取转化命令行参数
static void readCommand(String[] args) {
if(!args[0].equals("list")) {
System.out.println("缺少list指令");
System.exit(0);
}
for(int i=0;i if(args[i].equals("-log")) {
log=args[++i];
}
if(args[i].equals("-out")) {
out=args[++i];
}
if(args[i].equals("-date")) {
date=args[++i];
}
if(args[i].equals("-type")) {
type.append(args[++i]);
for(int j=i+1;j if(args[j].equals("ip")||args[j].equals("sp")||
args[j].equals("cure")||args[j].equals("dead")) {
type.append(" "+args[j]);
}
}
}
if(args[i].equals("-province")) {
province.append(args[++i]);
for(int j=i;j if(!(args[i].equals("-log")||args[i].equals("-out")
||args[i].equals("-date")||args[i].equals("-type"))) {
i++;
province.append(" "+args[i]);
}
}
}
}
}
3.读取日志文件中的每一行
public static void readFile(String path) throws IOException {
File file=new File(path);
if (file.exists()) {
File[] files=file.listFiles();
if (null!=files) {
for (File file2:files) {
if (!file2.isDirectory()) {
FileReader fr=new FileReader(file2);
BufferedReader br=new BufferedReader(fr);
String line="";
String filedate=file2.getName();
filedate=filedate.substring(0, 10);
// System.out.println(filedate);
SimpleDateFormat format=new SimpleDateFormat("yyyy-MM-dd");
Date logdate=null;
Date cmddate=null;
try {
logdate = format.parse(filedate);
cmddate = format.parse(date);
} catch (ParseException e) {
e.printStackTrace();
}
// System.out.println(logdate.toString());
if(logdate.compareTo(cmddate)<=0) {
while((line=br.readLine())!=null) {
// System.out.println(line);
statistic(line);
}
}
}
}
}
} else {
System.out.println("文件不存在!");
System.exit(0);
}
}
4.查找省份名对于的数组下标
static int findProvince(String provincename) {
for(int i=0;i if(provincelist[i].name.equals(provincename)) {
return i;
}
}
return 0;
}
5.数据统计,将日志文件数据转化为省份类对象的数据
static void statistic(String line) {
String p="\\\\";
String p1=".*新增 感染患者.*";
String p2=".*新增 疑似患者.*";
String p3=".*感染患者 流入.*";
String p4=".*疑似患者 流入.*";
String p5=".*死亡.*";
String p6=".*治愈.*";
String p7=".*疑似患者 确诊感染.*";
String p8=".*排除 疑似患者.*";
Pattern r=Pattern.compile(p);
Pattern r1=Pattern.compile(p1);
Pattern r2=Pattern.compile(p2);
Pattern r3=Pattern.compile(p3);
Pattern r4=Pattern.compile(p4);
Pattern r5=Pattern.compile(p5);
Pattern r6=Pattern.compile(p6);
Pattern r7=Pattern.compile(p7);
Pattern r8=Pattern.compile(p8);
Matcher m=r.matcher(line);
Matcher m1=r1.matcher(line);
Matcher m2=r2.matcher(line);
Matcher m3=r3.matcher(line);
Matcher m4=r4.matcher(line);
Matcher m5=r5.matcher(line);
Matcher m6=r6.matcher(line);
Matcher m7=r7.matcher(line);
Matcher m8=r8.matcher(line);
if(m.find()) return;
else if(m1.find()) {
String[] str=line.split(" ");
int index=findProvince(str[0]);
provincelist[0].ip+=Integer.parseInt(str[3].substring(0, str[3].length()-1));
provincelist[index].ip+=Integer.parseInt(str[3].substring(0, str[3].length()-1));
provincelist[index].status=true;
// System.out.println(provincelist[index].ip);
}
else if(m2.find()) {
String[] str=line.split(" ");
int index=findProvince(str[0]);
provincelist[0].sp+=Integer.parseInt(str[3].substring(0, str[3].length()-1));
provincelist[index].sp+=Integer.parseInt(str[3].substring(0, str[3].length()-1));
provincelist[index].status=true;
// System.out.println(provincelist[index].sp);
}
else if(m3.find()) {
String[] str=line.split(" ");
int index1=findProvince(str[0]);
int index2=findProvince(str[3]);
provincelist[index1].ip-=Integer.parseInt(str[4].substring(0, str[4].length()-1));
provincelist[index2].ip+=Integer.parseInt(str[4].substring(0, str[4].length()-1));
provincelist[index1].status=true;
provincelist[index2].status=true;
// System.out.println(provincelist[index2].ip);
}
else if(m4.find()) {
String[] str=line.split(" ");
int index1=findProvince(str[0]);
int index2=findProvince(str[3]);
provincelist[index1].sp-=Integer.parseInt(str[4].substring(0, str[4].length()-1));
provincelist[index2].sp+=Integer.parseInt(str[4].substring(0, str[4].length()-1));
provincelist[index1].status=true;
provincelist[index2].status=true;
// System.out.println(provincelist[index2].sp);
}