1. DJANGO使用指南
Django简介:
Django官网地址
Django发布于2005年7月,是当前Python世界里最有名且成熟的网络框架。 最初是被开发用于管理劳伦斯出版集团旗下的以新闻内容为主的网站的,即CMS(内容管理系统)软件。
Django是一个用Python编写的开放源代码的Web应用框架,代码是开源的。此系统采用了MVC的框架模式, 也可以称为MTV模式
什么是MVC模式
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。 通俗的来讲就是,强制性的使应用程序的输入,处理和输出分开。
核心思想:解耦
优点:减低各个模块之间的耦合性,方便变更,更容易重构代码,最大程度的实现了代码的重用
MVC(Model, View, Controller)
Model: 即数据存取层。用于封装于应用程序的业务逻辑相关的数据,以及对数据的处理。说白了就是模型对象负责在数据库中存取数据
View: 即表现层。负责数据的显示和呈现。渲染的html页面给用户,或者返回数据给用户。
Controller: 即业务逻辑层。负责从用户端收集用户的输入,进行业务逻辑处理,包括向模型中发送数据,进行CRUD操作。
图解:
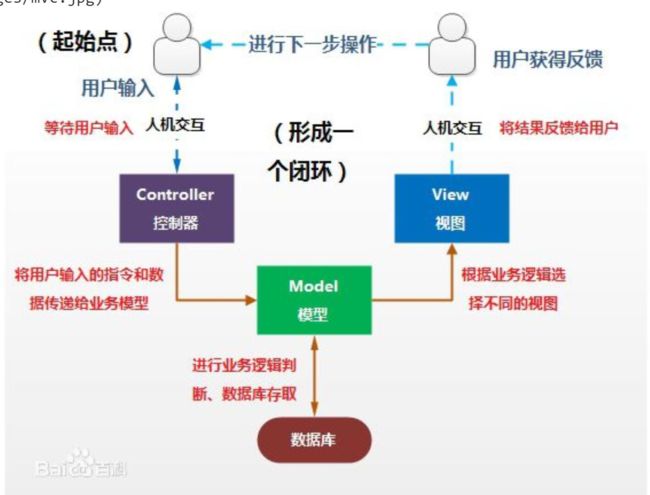
浏览器中MVC的表现形式图解:

Django的模式简介
MVT模式
严格来说,Django的模式应该是MVT模式,本质上和MVC没什么区别,也是各组件之间为了保持松耦合关系,只是定义上有些许不同。
Model: 负责业务与数据库(ORM)的对象
View: 负责业务逻辑并适当调用Model和Template
Template: 负责把页面渲染展示给用户
注意: Django中还有一个url分发器,也叫作路由。主要用于将url请求发送给不同的View处理,View在进行相关的业务逻辑处理。
2. VIRTUALENV虚拟环境创建指南
前言
本教程中使用到的python版本均为python3.x版本,由于本人安装的是python3.6.3版本,所以一下的课程均是在此基础上进行的。
-
virtualenv使用场景:当开发成员负责多个项目的时候,每个项目安装的库又是有很多差距的时候,会使用虚拟环境将每个项目的环境给隔离开来。
比如,在有一个老项目已经开发维护了3年了,里面很多库都是比较老的版本了。例如python使用的是2.7版本的。但是新项目使用的python版本是3.6的。为了解决这种项目执行环境的冲突,所以引入了虚拟环境virtualenv。
当然除了virtualenv可以起到隔离环境的作用,还有其他技术方案来实现,而且上线流程简单,大大减轻运维人员的出错率,比如每一个项目使用一个docker镜像,在镜像中去安装项目所需的环境,库版本等等
python环境的配置
- 在cmd中能通过python去启动,如果不行直接跳到第三步

-
在cmd中能通过pip3启动安装软件,如果不行直接跳到第三步
 image.png
image.png
3.配置python环境和pip环境
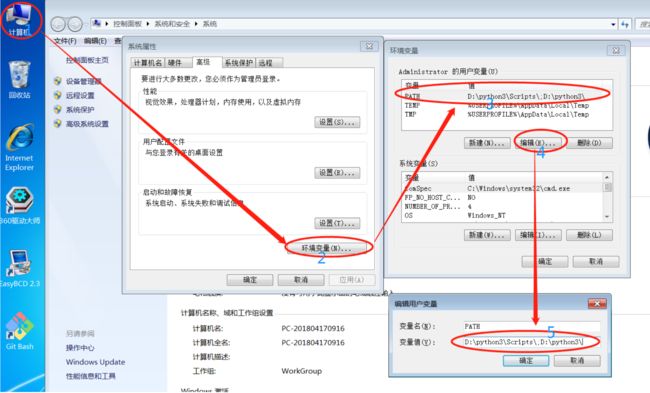
确认pip安装成功,如果Scritp文件夹下没有pip可执行文件,则执行第五步。
由于python3.6安装以后,在Scripts文件中没有pip的可执行软件,需要输入一下命令进行安装
python -m ensurepip
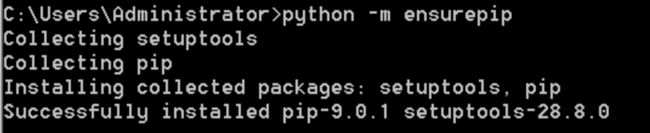
注:现在在python的安装文件夹Scripts下就有pip.exe以及easy_install.exe等可执行文件了,就可以使用pip安装啦~
windows中安装使用
- 安装virtualenv
pip install virtualenv

- 创建虚拟环境
先查看一下安装虚拟环境有那些参数,是必须填写的
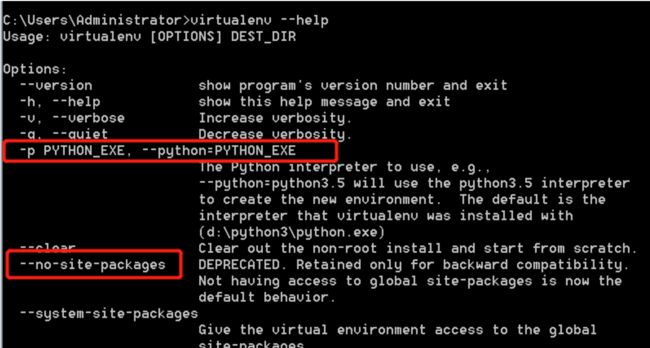
注意两个参数:
--no-site-packages和-p参数
virtualenv --no-site-package venv
以下是指定安装虚拟环境中的python版本的安装方式:

- 进入/退出env
进入 cd env/Scripts/文件夹 在activate命令
退出 deactivate
ubuntu中安装使用
- 安装virtualenv
apt-get install python-virtualenv
- 创建包含python3版本的虚拟环境
virtualenv -p /usr/bin/python3 env
env代表创建的虚拟环境的名称
- 进入/退出env
进入 source env/bin/activate
退出 deactivate
-
pip使用
查看虚拟环境下安装的所有的包
pip list查看虚拟环境重通过pip安装的包
pip freeze
3. DJANGO使用指南
创建Django项目
1. 首先创建一个运行Django项目的虚拟环境(virtualenv)
虚拟环境的创建在基础课程中讲解,地址
该虚拟环境中有django库,python3,pymysql等等需要的库
大致在罗列下安装了那些库:
pip install Django==1.11
pip install PyMySQL
2. 创建一个Django项目
2.1 创建项目
django-admin startproject halloWorld
该命令是创建一个名为halloWorld的工程
项目目录介绍
下面展示创建以后的文件,具体有哪些文件:
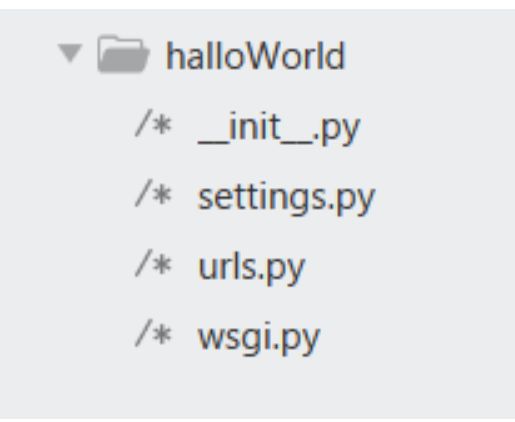
manage.py: 是Django用于管理本项目的管理集工具,之后站点运行,数据库自动生成,数据表的修改等都是通过该文件完成。
init.py: 指明该目录结构是一个python包,暂无内容,在后期会初始化一些工具会使用到。
seetings.py: Django项目的配置文件,其中定义了本项目的引用组件,项目名,数据库,静态资源,调试模式,域名限制等
urls.py:项目的URL路由映射,实现客户端请求url由哪个模块进行响应。
wsgi.py:定义WSGI接口信息,通常本文件生成后无需改动
2.2 运行Django项目
python manage.py runserver 端口
该命令是运行项目,端口可以不用写,启动的时候会默认随机创建一个可以使用的端口
2.2 创建app
python manage.py startapp hallo_app
该命令是在blog工程下创建一个名为hallo_app的app
3. settings.py配置文件详细解读
a) 设置语言:
LANGUAGE_CODE = 'zh-hans' 表示中文
LANGUAGE_CODE = 'en-us' 表示英文
设置时区: TIME_ZONE = 'Asia/Shanghai'
b) 时区解释: (需要详细回顾思考时区问题)
UTC:世界标准时间,也就是平常说的零时区。
北京时间表示东八区时间,即UTC+8
模型使用指南--admin
前言
Djang自身集成了管理后台,在管理后台中可以对我们自定义model进行CRUD操作,也能进行列表展示解析,分页等等
使用admin管理后台
0. 准备工作,在model中定义Student的模型
```
class Students(models.Model):
name = models.CharField(max_length=10)
sex = models.BooleanField()
class Meta:
db_table = 'student'
```
1. admin管理后台的url
在工程目录下可以看到路由配置中有一个admin的url地址
```
url(r'^admin/', admin.site.urls),
```
2. 创建admin后台的用户密码
```
python manage.py createsuperuser
```
[图片上传失败...(image-4a4434-1536808795504)]
3. 在登录后的管理后台中对自定义的模型进行CRUD操作
在管理后台中操作模型对象。需要在app的admin.py中写如下代码
```
admin.site.register(模型名)
```
4. 继承admin.ModelAdmin,编写自定义的admin
```
class StudentAdmin(admin.ModelAdmin):
def set_sex(self):
if self.sex:
return '男'
else:
return '女'
set_sex.short_description = '性别'
list_display = ['id', 'name', set_sex]
list_filter = ['sex']
search_fields = ['name']
list_per_page = 1
admin.site.register(模型名, StudentAdmin)
```
其中:
list_display: 显示字段
list_filter: 过滤字段
search_fields: 搜索字段
list_per_page: 分页条数
5. 使用装饰器去实现注册
```
@admin.register(模型名)
class StudentAdmin(admin.ModelAdmin):
def set_sex(self):
if self.sex:
return '男'
else:
return '女'
set_sex.short_description = '性别'
list_display = ['id', 'name', set_sex]
list_filter = ['sex']
search_fields = ['name']
list_per_page = 1
```
模型使用指南--models
前言
Django对数据库提供了很好的支持,对不同的数据库,django提供了统一调用的API,我们可以根据不同的业务需求使用不同是数据库。Django中引入了ORM(Objects Relational Mapping)对象关系映射,是一种程序技术。在下面会详细的讲解。
修改mysql配置
1. 在settings.py中配置数据库连接信息
'ENGINE':'django.db.backends.mysql',
'NAME':'', #数据库名
'USER':'', #账号
'PASSWORD':'', #密码
'HOST':'127.0.0.1', #IP(本地地址也可以是localhost)
'PORT':'3306', #端口
2. mysql数据库中创建定义的数据库
a) 进入mysql
mysql -u root -p
b) 创建数据库
create database xxx charset=utf-8;
3. 配置数据库链接
a) 安装pymysql
pip install pymysql
b) 在工程目录下的init.py文件中输入,完成数据库的驱动加载
import pymysql
pymysql.install_as_MySQLdb()
4. 定义模型
重要概念:模型,表,属性,字段
一个模型类在数据库中对应一张表,在模型类中定义的属性,对应模型对照表中的一个字段
定义属性见定义属性文件地址
创建学生模型类
class Student(models.Model):
s_name = models.CharField(max_length=10)
s_age = models.IntegerField()
s_gender = models.BooleanField()
class Meta:
db_table = 'cd_student'
ordering =[]
对象的默认排序字段,获取对象列表时使用,升序ordering['id'],降序ordering['-id']
5.迁移数据库
a) 生成迁移文件
python manage.py makemigrations
注意:如果执行后并没有生成迁移文件,一直提示No changes detected这个结果的话,就要手动的去处理了。有两点处理方式:
1) 先删除掉pycache文件夹
2) 直接强制的去执行迁移命令,python manage.py makemigrations xxx (xxx就是app的名称)
3) 查看自动生成的数据库,查看表django_migrations,删掉app字段为xxx的数据(xxx就是app的名称)
b) 执行迁移生成数据库
python manage.py migrate
注意: 生成迁移文件的时候,并没有在数据库中生成对应的表,而是执行migrate命令之后才会在数据库中生成表
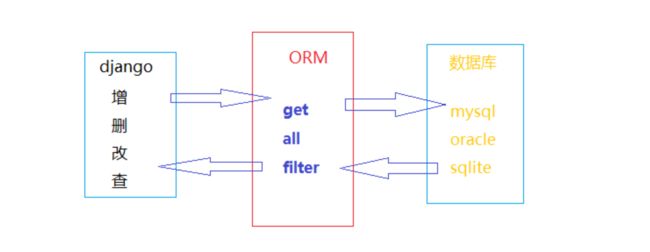
6. ORM
ORM(Objects Relational Mapping)对象关系映射,是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。可以简单理解为翻译机。
7.模型查询
a) 模型成员objects
Django默认通过模型的objects对象实现模型数据查询
b) 过滤器
查询集表示从数据库获取的对象集合
查询集可以有多个过滤器
过滤器就是一个函数,基于所给的参数限制查询的结果
从SQL角度来说,查询集合和select语句等价,过滤器就像where条件
Django有两种过滤器用于筛选记录
filter : 返回符合筛选条件的数据集
exclude : 返回不符合筛选条件的数据集
多个filter和exclude可以连接在一起查询
当然还有如下这些过滤器:
all() 返回所有数据
filter() 返回符合条件的数据
exclude() 过滤掉符合条件的数据
order_by() 排序
values() 一条数据就是一个字典,返回一个列表
c) 查询单个数据
get():返回一个满足条件的对象。如果没有返回符合条件的对象,会应该模型类DoesNotExist异常,如果找到多个,会引发模型类MultiObjectsReturned异常
first():返回查询集中的第一个对象
last():返回查询集中的最后一个对象
count():返回当前查询集中的对象个数
exists():判断查询集中是否有数据,如果有数据返回True,没有返回False
d) 限制查询集
限制查询集,可以使用下表的方法进行限制,等同于sql中的limit
模型名.objects.all()[0:5] 小标不能为负数
e) 字段查询
对sql中的where实现,作为方法,filter(),exclude(),get()的参数
语法:属性名称__比较运算符 = 值
外键:属性名_id
注意:like语句中使用%表示通配符。比如sql语句查询 where name like '%xxx%',等同于filter(name_contains='xxx')
f) 比较运算符
contains:是否包含,大小写敏感
startswith,endswith:以values开头或者结尾,大小写敏感
以上的运算符前加上i(ignore)就不区分大小写了
isnull,isnotnull:是否为空。filter(name__isnull=True)
in:是否包含在范围内。filter(id__in=[1,2,3])
gt,gte,lt,lte:大于,大于等于,小于,小于等于。filter(age__gt=10)
pk:代表主键,也就是id。filter(pk=1)
g) 聚合函数
agregate()函数返回聚合函数的值
Avg:平均值
Count:数量
Max:最大
Min:最小
Sum:求和
例如: Student.objects.aggregate(Max('age'))
h) F对象/Q对象
F对象:可以使用模型的A属性与B属性进行比较
背景:在模型中有两个字段,分别表示学生成绩A与成绩B,要对成绩AB进行比较计算,就需要使用到F对象。
例如有如下例子1:
班级中有女生个数字段以及男生个数字段,统计女生数大于男生数的班级可以如下操作:
grades = Grade.objects.filter(girlnum__gt=F('boynum'))
F对象支持算数运算
grades = Grade.objects.filter(girlnum__gt=F('boynum') + 10)
例子2:
查询python班下语文成绩超过数学成绩10分的学生
grade = Grade.objects.filter(g_name='python').first()
students = grade.student_set.all()
stu = students.filter(s_yuwen__gt= F('s_shuxue') + 10)
Q对象:
Q()对象就是为了将过滤条件组合起来
当我们在查询的条件中需要组合条件时(例如两个条件“且”或者“或”)时。我们可以使用Q()查询对象
使用符号&或者|将多个Q()对象组合起来传递给filter(),exclude(),get()等函数
Q()对象的前面使用字符“~”来代表意义“非”
例子1:
查询学生中不是12岁的或者姓名叫张三的学生
student = Student.objects.filter(~Q(age=12) | Q(name='张三'))
例子2:
查询python班语文小于80并且数学小于等于80的学生
grade = Grade.objects.filter(g_name='python').first()
students = grade.student_set.all()
stu = students.filter(~Q(s_yuwen__gte=80) & Q(s_shuxue__lte=80))
例子3:
查询python班语文大于等于80或者数学小于等于80的学生
grade = Grade.objects.filter(g_name='python').first()
students = grade.student_set.all()
stu = students.filter(Q(s_yuwen__gte=80) | Q(s_shuxue__lte=80))
8.模型字段定义属性
定义属性
概述
·django根据属性的类型确定以下信息
·当前选择的数据库支持字段的类型
·渲染管理表单时使用的默认html控件
·在管理站点最低限度的验证
·django会为表增加自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后,则django不会再生成默认的主键列
·属性命名限制
·遵循标识符规则(不使用python预定义的标识符号,内置函数名,异常等。避免使用下划线等)
·由于django的查询方式,不允许使用连续的下划线
库
·定义属性时,需要字段类型,字段类型被定义在django.db.models.fields目录下,为了方便使用,被导入到django.db.models中
·使用方式
·导入from django.db import models
·通过models.Field创建字段类型的对象,赋值给属性
逻辑删除
·对于重要数据都做逻辑删除,不做物理删除,实现方法是定义isDelete属性,类型为BooleanField,默认值为False
字段类型
·AutoField
·一个根据实际ID自动增长的IntegerField,通常不指定如果不指定,一个主键字段将自动添加到模型中
·CharField(max_length=字符长度)
·字符串,默认的表单样式是 TextInput
·TextField
·大文本字段,一般超过4000使用,默认的表单控件是Textarea
·IntegerField
·整数
·DecimalField(max_digits=None, decimal_places=None)
·使用python的Decimal实例表示的十进制浮点数
·参数说明
·DecimalField.max_digits
·位数总数
·DecimalField.decimal_places
·小数点后的数字位数
·FloatField
·用Python的float实例来表示的浮点数
·BooleanField
·true/false 字段,此字段的默认表单控制是CheckboxInput
·NullBooleanField
·支持null、true、false三种值
·DateField([auto_now=False, auto_now_add=False])
·使用Python的datetime.date实例表示的日期
·参数说明
·DateField.auto_now
·每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false
·DateField.auto_now_add
·当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false
·说明
·该字段默认对应的表单控件是一个TextInput. 在管理员站点添加了一个JavaScript写的日历控件,和一个“Today"的快捷按钮,包含了一个额外的invalid_date错误消息键
·注意
·auto_now_add, auto_now, and default 这些设置是相互排斥的,他们之间的任何组合将会发生错误的结果
·TimeField
·使用Python的datetime.time实例表示的时间,参数同DateField
·DateTimeField
·使用Python的datetime.datetime实例表示的日期和时间,参数同DateField
·FileField
·一个上传文件的字段
·ImageField
·继承了FileField的所有属性和方法,但对上传的对象进行校验,确保它是个有效的image
字段选项
·概述
·通过字段选项,可以实现对字段的约束
·在字段对象时通过关键字参数指定
·null
·如果为True,则该字段在数据库中是空数据,默认值是 False
·blank
·如果为True,则该字段允许为空白,默认值是 False
·注意
·null是数据库范畴的概念,blank是表单验证证范畴的
·db_column
·字段的名称,如果未指定,则使用属性的名称
·db_index
·若值为 True, 则在表中会为此字段创建索引
·default
·默认值
·primary_key
·若为 True, 则该字段会成为模型的主键字段
·unique
·如果为 True, 这个字段在表中必须有唯一值
模型练习指南
前言
通过讲mysql的系统,翻译一遍,在django中通过创建model去和数据库中的表进行一一映射,并且通过ORM封装
的处理方式去练习这一到习题,并写出如下的解题答案
1.数据库准备
在model中定义数据库,其中的性别,男的存1,女的存0。
```
class Student(models.Model):
stuname = models.CharField(max_length=20)
studex = models.BooleanField()
stubirth = models.DateField()
stutel = models.CharField(max_length=255)
class Meta:
db_table = 'student'
```
2.数据库迁移
python manage.py makemigrations
python manage.py migrate
3. 数据插入
3.1 使用表单form提交post请求数据
3.2 获取post请求,获取请求数据,并且创建数据
stu = Student()
stu.stuname = stuname
stu.stusex = sex
stu.stubirth = birth
stu.stutel = tel
stu.save()
方法2:
Student.objects.create(stuname=stuname, stusex=sex, stubirth=birth, stutel=tel)
4. 查询所有的学生信息
使用all()方法获取所有的数据
Student.objects.all()
4. 查询所有女学生的姓名和出生日期
Student.objects.filter(stusex=0)
或者
Student.objects.exclude(stusex=1)
其中:
filter():返回符合条件的数据
exclude():过滤掉符合条件的数据
5.查询所有的学生,按照id从大到小排序
Student.objects.all().order_by('-id')
其中:
order_by('id'):表示按照id升序的排列
order_by('-id'):表示按照id降序的排列
6. 查询单个数据,就不做演示了,可以使用一下的方法去获取
get():返回一个满足条件的对象。如果没有返回符合条件的对象,会应该模型类DoesNotExist异常,如果找到多个,会引发模型类MultiObjectsReturned异常
first():返回查询集中的第一个对象
last():返回查询集中的最后一个对象
count():返回当前查询集中的对象个数
exists():判断查询集中是否有数据,如果有数据返回True,没有返回False
7.查询所有80后学生的姓名、性别和出生日期(筛选)
Student.objects.filter(stubirth__gte='1980-01-01', stubirth__lte='1990-01-01')
8.查询名字中有王字的学生的姓名(模糊)
Student.objects.filter(stuname__contains='王')
9.查询姓王的学生姓名和性别(模糊)
Student.objects.filter(stuname__startswith='王')
思考:以什么结束应该怎么写----》 使用endswith
模型加餐使用指南
前言
该文档中主要介绍模型的对应关系,一对一,一对多,以及多对多的关系。并且举例说明
模型对应关系描述如下:
1:1 一对一 OneToOneField
1:N 一对多 ForeignKey
M:N 多对多 ManyToManyField
常见的几种数据关系,django都提供了很好的支持
1. 一对一
1.1 模型
创建学生的模型:
class Student(models.Model):
stu_name = models.CharField(max_length=6, unique=True)
stu_sex = models.BooleanField(default=0)
stu_birth = models.DateField()
stu_delete = models.BooleanField(default=0)
stu_create_time = models.DateField(auto_now_add=True)
stu_operate_time = models.DateField(auto_now=True)
stu_tel = models.CharField(max_length=11)
stu_yuwen = models.DecimalField(max_digits=3, decimal_places=1, default=0)
stu_shuxue = models.DecimalField(max_digits=3, decimal_places=1, default=0)
class Meta:
db_table = 'stu'
创建学生拓展的模型:
class StuInfo(models.Model):
stu_addr = models.CharField(max_length=30)
stu_age = models.IntegerField()
stu = models.OneToOneField(Student)
class Meta:
db_table = 'stu_info'
使用models.OneToOneField()进行关联
class StuInfo(models.Model):下是通过班级获取学生信
stu = models.OneToOneField(Student)
注意:在数据中关联字段名称叫stu_id
1.2 通过学生拓展表去获取学生信息
```
stuinfo = StuInfo.objects.all().first()
student = stuinfo.stu
```
注意:通过拓展表去获取学生的信息的话,语法如下;
学生拓展表的单条对象.关联字段,即可获取到学生表的数据
1.3 通过学生获取人信息1
```
stu = Student.objects.all().first()
stuInfo = stu.stuinfo
```
注意:通过学生获取关联表的数据的话,语法如下:
学生对象.关联的表名,即可获取到关联表的数据
1.3.1 通过学生获取人信息2
在关联字段OneToOneField中加入参数related_name='xxx'
```
在
stu = Student.objects.all().first()
stuInfo = stu.xxx
```
注意:通过学生获取关联表的数据的话,语法如下:
学生对象.关联的字段中定义的related_name参数,即可获取到关联表的数据
1.4 设置对应关系的字段为保护模式 :
models.CASCADE 默认值
models.PROTECT 保护模式
models.SET_NULL 置空模式
models.SET_DETAULT 置默认值
models.SET() 删除的时候吃重新动态指向一个实体访问对象元素
on_delete = models.PROTECT
```
修改on_delete参数
models.OneToOneField('Student', on_delete=models.SET_NULL, null=True)
```
在删除student对象的时候,stuinfo的关联字段会设置为空null=True,如下命令去删除student的数据:
```
Student.objects.filter(id=1).delete()
```
1.5 定义on_delete=models.PROTECT
p = Student.objects.all().first()
p.delete()
注意:这个时候去执行该业务逻辑的方法的时候会报错
2. 一对多
2.1 模型
```
定义一个班级类还有学生类,实现一对多的关系:
先定义班级类
Class Grade(models.Model):
g_name = models.CharField(max_length=16)
定义student
class Student:
s_name = models.CharField(max_length=10)
s_age = models.IntegerField(default=1)
s_grade = models.ForeignKey(Grade, on_delete=PROTECT)
```
注意:使用models.ForeignKey关联
获取对象元素 grade.student_set
2.2 获取数据
语法:通过一获取多的数据
公式: 一的对象.多的模型名小写_set
然后在获取数据all(), get(), filter() 等等
如下先通过学生去获取班级信息:
stu = Student.objects.first()
stu.s_grade
如下是通过班级获取学生信息:
g = Grade.objects.all().first()
g.stugrade.all() ---> 其中stugrade是定义的related_name参数
重点:
定义了related_name字段以后,只能通过related_name去反向获取数据,在也不能通过_set方法去获取数据了
2.3 数据查询,正查/反查
# 查询id=4的学生的班级名称
stu = Student.objects.get(id=4)
grade = stu.s_grade
# 查询id=1的班级的所有学生
grade = Grade.objects.filter(id=1).first()
stus = grade.student_set.all()
2.4 练习题
2.6 获取python班下的所有学生的信息
gs = Grade.objects.filter(g_name='python')[0]
allstu = gs.student_set.all()
2.7 获取python班下语文成绩大于80分的女学生
gs = Grade.objects.filter(g_name='python')[0]
allstu = gs.student_set.filter(stu_yuwen__gte=80)
2.8 获取python班下语文成绩超过数学成绩10分的男学生
gs = Grade.objects.filter(g_name='python')[0]
allstu = gs.student_set.filter(stu_yuwen__gte=F('stu_shuxue') + 10)
2.9 获取出生在80后的男学生,查看他们的班级
gs = Grade.objects.filter(g_name='python')[0]
allstu = gs.student_set.filter(stu_birth__gte='1980-01-01', stu_birth__lte='1990-01-01')
3. 多对多
3.1 M:N 模型
定义购物车,用户的例子实现多对多:
```
1. 创建用户模型:
class GoodsUser(models.Model):
u_name = models.CharField(max_length=32)
2. 创建商品模型:
class Goods(models.Model):
g_name = models.CharField(max_length=32)
g_user = models.ManyToManyField(User)
```
3.2 多对多表结构
多对多关系:
1. 生成表的时候会多生成一张表(实际会有三张表)
2. 生成的表是专门用来维护关系的
3. 生成的表是使用两个外键来维护多对多的关系
4. 两个一对多的关系来实现多对多的实现
5. 删除一个表的数据的话,中间关联表也要删除相关的信息
3.3 中间表数据的增(add)删(remove)
# id=4的用户添加两个商品(id=1,2)
g_user = GoodsUser.objects.get(id=4)
c1 = Goods.objects.get(id=1)
c2 = Goods.objects.get(id=2)
g_user.goods_set.add(c1)
g_user.goods_set.add(c2)
# 删除id=4的用户的商品中id=1的商品
g_user.goods_set.remove(c1)
3.4 练习题
3.4.1 获取第一个用户购买了那些商品
```
gu = GoodsUser.objects.all().first()
allstu = gu.goods_set.all()
```
3.4.2 获取指定商品的购买用户信息
```
g = Goods.objects.filter(id=1)[0]
g.g_user.all()
```
模板使用指南
前言
在Django框架中,模板是可以帮助开发者快速生成呈现给用户页面的工具
模板的设计方式实现了我们MVT重VT的解耦,VT有着N:M的关系,一个V可以调用任意T,一个T可以供任意V使用
模板处理分为两个过程
加载
渲染
1. 加载静态配置文件
在settings.py中最底下有一个叫做static的文件夹,主要用来加载一些模板中用到的资源,提供给全局使用
这个静态文件主要用来配置css,html,图片,文字文件等
STATIC_URL = ‘/static/’
STATICFILES_DIRS = [
os.path.join(BASE_DIR, ‘static’)
]
只后在模板中,首先加载静态文件,之后调用静态,就不用写绝对全路径了
2. 使用静态配置文件
a) 加载渲染静态配置文件
模板中声明
{% load static %} 或者 {% load staticfiles %}
在引用资源的时候使用
{% static ‘xxx’ %} xxx就是相当于staticfiles_dirs的一个位置
b) 直接定义静态配置

其中: 展示static文件夹下有一个images文件夹,下面有一个mvc.png的图片
3. 模板摘要
3.1 模板主要有两个部分
HTML静态代码
动态插入的代码段(挖坑,填坑)也就是block
3.2 动态填充
模板中的动态代码断除了做基本的静态填充,还可以实现一些基本的运算,转换和逻辑
如下:

模板中的变量:
视图传递给模板的数据
标准标识符规则
语法 {{ var }}
如果变量不存在,则插入空字符串
3.3 模板重的点语法
对象.属性或者方法
索引 (student.0.name)

3.4模板中的小弊端
调用对象的方法,不能传递参数
3.5 模板的标签
语法 {% tag %}
作用 a)加载外部传入的变量
b)在输出中创建文本
c)控制循环或逻辑
4. if表达式
格式1:
{% if 表达式 %}
{% endif %}
格式2:
{% if表达式 %}
{% else %}
{% endif %}
格式3:
{% if表达式 %}
{% elif 表达式 %}
{% endif %}

5. for表达式
格式1:
{% for 变量 in 列表 %}
{% empty %}
{% endfor %}
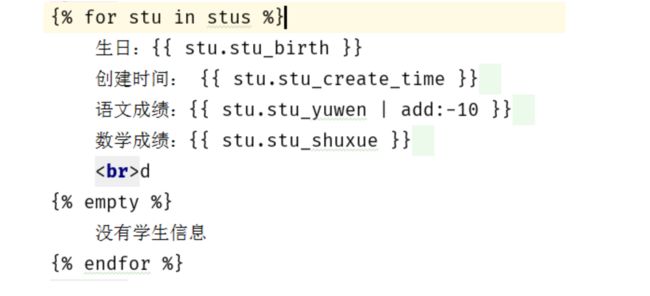
注意:当列表为空或者不存在时,执行empty之后的语句
注意一下用法:
{{ forloop.counter }} 表示当前是第几次循环,从1开始
{{ forloop.counter0 }} 表示当前从第几次循环,从0开始
{{forloop.revcounter}}表示当前是第几次循环,倒着数数,到1停
{{forloop.revcounter0}}表示当前是第几次循环,倒着数数,到0停
{{forloop.first}}是否是第一个 布尔值
{{forloop.last}}是否是最后一个 布尔值
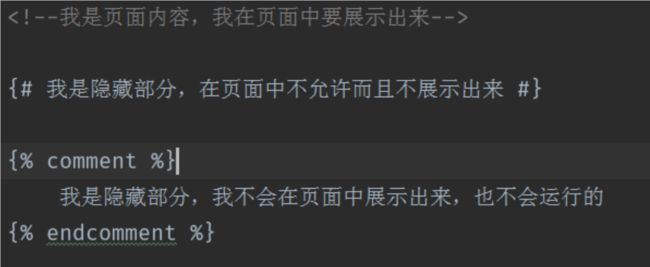
6. 注释
6.1 注释可见,可运行
6.1 单行注释注释不可见,不可运行
单行注释(页面源码中不会显示注释内容)
{# 被注释掉的内容 #}
6.2 多行注释注释不可见,不可运行
{% comment %}
{% endcomment %}
7. 过滤器
引入过滤器定义:{{var|过滤器}}, 作用:在变量显示前修改
过滤器有很多,比如add / lower / upper
7.1 加法
{{ p.page | add:5 }}
没有减法的过滤器,但是加法里面可以加负数
{{ p.page | add: -5 }}
7.2 修改大小写
lower / upper : {{ p.pname | lower }} 变为小写或者大写
7.3 传参数
过滤器可以传递参数,参数需要使用引号引起来。比如join: {{ student | join ‘=’ }}
如果值为空则设置默认值:
默认值:default,格式{{ var | default value }}
如果变量没有被提供或者为False,空,会使用默认值
7.4 定制日期格式
根据制定格式转换日期为字符串,处理时间的就是针对date进行的转换
{{ dateVal | date: ‘y-m-d h:m:s’ }}
如果过滤器,定义为小写的y,则返回的数据为两位的年。如果写的是大写的Y,则返回的是四位的年
定义小写的m,则返回数字的月份,如果定义大写的M,则返回英文
定义小写的h,则返回12小时制度的时,如果定义的是大写的H,则返回24小时制度的时
7.5 是否转义
HTML转义:
将接收到的数据当成普通字符串处理还是当成HTML代码来渲染的一个问题
渲染成html: {{ code | safe }}
还可以使用autoscape渲染:
{{ autoscape off }}
{{ endautoscape }}
不渲染的话:
{{ autoscape on }}
{{ endautoscape }}
7.6 案例
{{ 'Python'|upper }}
{{ 'PYTHON'|lower }}
{{ 3|add:'4' }}
{{ 'python'|capfirst }}
{{ 'study python is very happy'|cut:' ' }}
{{ ''|default:'nothing' }}
{{ 'python'|first }}
{{ 'python'|last }}
{{ 'python'|length }}
{{ 'python'|random }}
7.7 django内建过滤器大全
1、add :将value的值增加2。使用形式为:{{ value | add: "2"}}。
2、addslashes:在value中的引号前增加反斜线。使用形式为:{{ value | addslashes }}。
3、capfirst:value的第一个字符转化成大写形式。使用形式为:{{ value | capfirst }}。
4、cut:从给定value中删除所有arg的值。使用形式为:{{ value | cut:arg}}。
5、date: 格式化时间格式。使用形式为:{{ value | date:"Y-m-d H:M:S" }}
6、default:如果value是False,那么输出使用缺省值。使用形式:{{ value | default: "nothing" }}。例如,如果value是“”,那么输出将是nothing
7、default_if_none:如果value是None,那么输出将使用缺省值。使用形式:{{ value | default_if_none:"nothing" }},例如,如果value是None,那么输出将是nothing
8、dictsort:如果value的值是一个字典,那么返回值是按照关键字排序的结果
使用形式:{{ value | dictsort:"name"}},例如,
如果value是:
[{'name': 'python'},{'name': 'java'},{'name': 'c++'},]
那么,输出是:
[{'name': 'c++'},{'name': 'java'},{'name': 'python'}, ]
9、dictsortreversed:如果value的值是一个字典,那么返回值是按照关键字排序的结果的反序。使用形式:与dictsort过滤器相同。
10、divisibleby:如果value能够被arg整除,那么返回值将是True。使用形式:{{ value | divisibleby:arg}},如果value是9,arg是3,那么输出将是True
11、escape:替换value中的某些字符,以适应HTML格式。使用形式:{{ value | escape}}。例如,< 转化为 <> 转化为 >' 转化为 '" 转化为 "
13、filesizeformat:格式化value,使其成为易读的文件大小。使用形式:{{ value | filesizeformat }}。例如:13KB,4.1MB等。
14、first:返回列表/字符串中的第一个元素。使用形式:{{ value | first }}
16、iriencode:如果value中有非ASCII字符,那么将其进行转化成URL中适合的编码,如果value已经进行过URLENCODE,改操作就不会再起作用。使用形式:{{value | iriencode}}
17、join:使用指定的字符串连接一个list,作用如同python的str.join(list)。使用形式:{{ value | join:"arg"}},如果value是['a','b','c'],arg是'//'那么输出是a//b//c
18、last:返回列表/字符串中的最后一个元素。使用形式:{{ value | last }}
19、length:返回value的长度。使用形式:{{ value | length }}
20、length_is:如果value的长度等于arg的时候返回True。使用形式:{{ value | length_is:"arg"}}。例如:如果value是['a','b','c'],arg是3,那么返回True
21、linebreaks:value中的"\n"将被
替代,并且整个value使用包围起来。使用形式:{{value|linebreaks}}
22、linebreaksbr:value中的"\n"将被
替代。使用形式:{{value |linebreaksbr}}
23、linenumbers:显示的文本,带有行数。使用形式:{{value | linenumbers}}
24、ljust:在一个给定宽度的字段中,左对齐显示value。使用形式:{{value | ljust}}
25、center:在一个给定宽度的字段中,中心对齐显示value。使用形式:{{value | center}}
26、rjust::在一个给定宽度的字段中,右对齐显示value。使用形式:{{value | rjust}}
27、lower:将一个字符串转换成小写形式。使用形式:{{value | lower}}
30、random:从给定的list中返回一个任意的Item。使用形式:{{value | random}}
31、removetags:删除value中tag1,tag2....的标签。使用形式:{{value | removetags:"tag1 tag2 tag3..."}}
32、safe:当系统设置autoescaping打开的时候,该过滤器使得输出不进行escape转换。使用形式:{{value | safe}}
33、safeseq:与safe基本相同,但有一点不同的就是:safe是针对字符串,而safeseq是针对多个字符串组成的sequence
34、slice:与python语法中的slice相同。使用形式:{{some_list | slice:"2"}}
37、striptags:删除value中的所有HTML标签.使用形式:{{value | striptags}}
38、time:格式化时间输出。使用形式:{{value | time:"H:i"}}或者{{value | time}}
39、title:转换一个字符串成为title格式。
40、truncatewords:将value切成truncatewords指定的单词数目。使用形式:{{value | truncatewords:2}}。例如,如果value是Joel is a slug 那么输出将是:Joel is ...
42、upper:转换一个字符串为大写形式
43、urlencode:将一个字符串进行URLEncode
46、wordcount:返回字符串中单词的数目
8. 运算
8.1 乘
{% widthratio 数 分母 分子 %}
如下例子: 求数学成绩的10倍的结果
{% widthratio 10 1 stu.stu_shuxue %}
8.2 整除
{{ num|divisibleby:2 }}
注意:该语句的意思是,判断num值是否能被2整除,如果能的话返回True,不能的话返回False
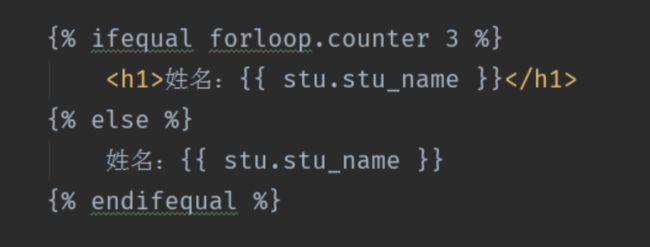
8.3 ifeuqal判断相等
{% ifequal value1 value2 %}
{% endifqueal %}
9. 反向解析
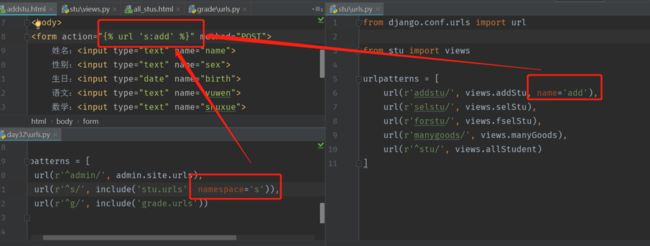
Url 反向解析
{% url ‘namespace:name’ p1 p2 %}
10. 跨站请求CSRF(Cross Site Request Forgery)
csrf攻击说明
1.用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
2.在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
3.用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
4.网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
5.浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
csrf的攻击之所以会成功是因为服务器端身份验证机制可以通过Cookie保证一个请求是来自于某个用户的浏览器,但无法保证该请求是用户允许的。因此,预防csrf攻击简单可行的方法就是在客户端网页上添加随机数,在服务器端进行随机数验证,以确保该请求是用户允许的。Django也是通过这个方法来防御csrf攻击的。
理解如下图:

Django中防止跨站请求伪造使用CSRF, 即:客户端访问服务器端,在服务器端正常返回给客户端数据的时候,而外返回给客户端一段字符串,等到客户端下次访问服务器
端时,服务器端会到客户端查找先前返回的字符串,如果找到则继续,找不到就拒绝。
Django中配置:
- 在表单中添加
{% csrf_token %} - 在settings中的中间件MIDDLEWARE中配置打开
‘django.middleware.csrf.CsrfViewMiddleware’
11. 模板继承
11.1 block挖坑不用看了
关键字 block挖坑
{% block xxx %}
{% endblock %}
11.2 extends
extends 继承,写在开头位置
{% extends ‘父模板路径’%}
11.3 include
include 加载模型进行渲染
{% include ‘模板文件’%}
12. 模板继承实战
12.1 定义基础模板base.html
{% block title %}
{% endblock %}
{% block extCSS %}
{% endblock %}
{% block extJS %}
{% endblock %}
{% block indexbody %}
{% endblock %}
{% block content %}
{% endblock %}
{% block footer %}
{% endblock %}
12.2 定义继承base.html的base_main.html模板
该base_main.html模板主要用于加载一些公共的js或者css,其余模板继承该模板后,可以直接加载定义好的公共的js或者css
{% extends 'base.html' %}
{% block extJS %}
{% endblock %}
12.3 定义首页index.html
在首页index.html中,我们在{% block extJS %}中使用{{ block.super }}去加载之前在base_main.html中定义好了的js文件,将它继承过来,那么在index.html中就会加载两个js文件了。实现了将公共的js文件或者css文件单独提炼出去,不需要再每个页面中重复的去写加载js的重复代码了。
{% extends 'base_main.html' %}
{% block title %}
首页{{ user.username }}
{% endblock %}
{% block extCSS %}
{% endblock %}
{% block extJS %}
{{ block.super }}
{% endblock %}
{% block indexbody %}
{% endblock %}