本文是“我和MongoDB的故事”征文比赛的二等奖得主李鹏冲的文章。下面我们一起来欣赏下。
问题
近期线上一个三分片集群从 3.2 版本升级到 4.0 版本以后,集群节点的 CPU 的负载升高了很多(10% -> 40%), 除了版本的升级,项目逻辑和操作量均无变化。关闭 Balancer 以后 CPU 负载回归正常,稳定在 10% 以下。为此,只能经常关闭当前正在写入表的 balancer , 每周二打开 balancer 开启均衡,在此期间节点的 CPU 负载持续稳定在 40% 。集群有 3 个分片,除了 MongoDB 版本的变化,项目本身的逻辑无任何变化。那么升级以后 CPU 负载较大变化的背后是什么原因呢?
监控与日志
首先可以明确,升级以后 CPU 负载升高和 balancer 迁移数据有关。观察升级以后 4.0 版本,周二打开 balancer 期间的负载情况和 mongostat 结果:
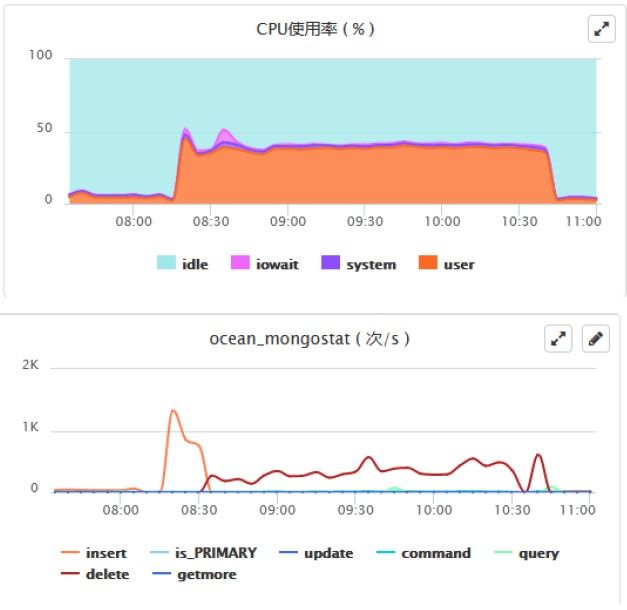
可以发现,CPU 负载升高和 delete 数据的情况很吻合。而迁移数据数据之后源节点需要删除迁移走的数据,所以肯定有大量的 delete 。迁移数据之后的删除也会有如下的日志:
53094:2019-10-08T10:09:24.035199+08:00 I SHARDING [Collection Range Deleter] No documents remain to delete in dt2log.tbl_log_item_20191001 range [{ _id: -3074457345618258602 }, { _ id: -3033667061349287050 })
53095:2019-10-08T10:09:24.035222+08:00 I SHARDING [Collection Range Deleter] Waiting for m ajority replication of local deletions in dt2log.tbl_log_item_20191001 range [{ _id: -3074 457345618258602 }, { _id: -3033667061349287050 })
53096:2019-10-08T10:09:24.035274+08:00 I SHARDING [Collection Range Deleter] Finished dele ting documents in dt2log.tbl_log_item_20191001 range [{ _id: -3074457345618258602 }, { _id
-3033667061349287050 })
所以从监控和日志判断, CPU 负载较高主要是因为迁移数据之后的删除导致。而且集群的表都是 {_id : hashed} 分片类型的表,数据量较大,但是每条数据较小,平均每个 chunk 10w+ 的文档数,删除数据速度约 200-300/s ,所以移动一个 chunk 导致的删除就会持续 10 分钟左右。
统计最近2个周期,开启 balancer 以后 moveChunk 的情况:
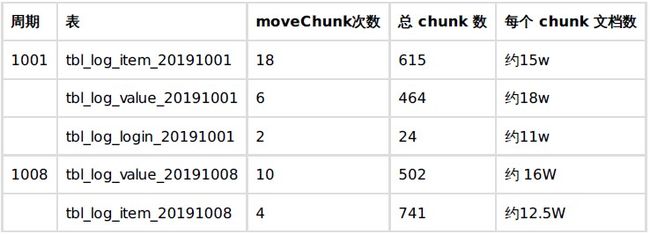
从上表可知此场景下, {_id : hashed} 分片类型集合数据基本已经均匀了,不必重启开启 balancer 。因为 每个chunk 文档数较多,删除会比较耗资源。
关闭表的 balancer 可以解决升级之后负载升高的问题,但是竟然是为何升级到 4.0 之后 CPU 负载较高, 而 3.2 版本稳定在低位呢?这只有可能是一个原因:4.0 版本更频繁的发生 moveChunk, 持续的删除数据导致 CPU 负载一直较高;3.2 版本较少的发生 moveChunk,不用删除数据所以负载很低。
所以本次问题的根本是: 4.0 版本和 3.2 版本的 balancer 与 moveChunk 的逻辑是否有差别?同样的操作,为什么 4.0版本的集群会有较多的 moveChunk ?
撸代码:splitChunk、balancer与moveChunk
当通过 mongos 发生插入和更新删除操作时,mongos 会估算对应 chunks 的数据量的大小,满足条件会触发splitChunk 的操作,splitChunk 之后可能会导致集群的 chunk 分布不均匀。balancer 检测数据的分布情况,当数据分配不均匀时,发起 moveChunk 任务,将数据从 chunks 较多的分片迁移到 chunks 较少的分片,迁移之后源节点会异步删除迁移走的 chunk 数据。
3.2 版本和 4.0 版本,此部分逻辑最大的区别就是, 3.2 版本 balancer 在 mongos,4.0 版本在 config(3.4版本开始),moveChunk 过程和删除数据的逻辑基本没有差异。
splitChunk
split chunks 一般是在插入、更新、删除数据时,由 mongos 发出到分片的 splitVector 命令,此时分片才会判断是否需要 split 。但是 mongos 并不知道每个 chunk 真正的数据量,是利用一个简单的估算算法判断的。
启动时,mongos 默认每个 chunk 的原始大小为 0-1/5 maxChunkSize 范围取个随机值 ;
之后 chunk 内数据,每次 update/insert 操作时,chunkSize = chunkSize + docSize;
当 chunkSize > maxChunkSize/5 时,触发一次可能 split chunk 的操作; 到 分片mongod 执行 splitVector命令 ,splitVector 命令返回 chunk 的分割点,如果返回为空那么不需要 split ,否则 继续 splitChunk。
也就是说,splitChunk 操作有滞后性,即使数据分布均衡,也有可能 splitChunk 执行时间的差异导致 chunks 分布存在中间的不均匀状态,导致大量的 moveChunk 。
balancer
无论 3.2 还是 4.0 的 balancer ,默认的检测周期为 10s , 如果发生了 moveChunk ,检测周期为 1s 。balancer 基本过程也大致相同:
config.shards 读取分片信息 ;
config.collections 读取所有集合信息,并且随机排序保存到一个数组中;
对每个集合从 config.chunks 读取 chunks 的信息;
含有最多 chunks 数量 (maxChunksNum)的分片为源分片,含有最少 chunks 数量(minChunksNum)的分片为目的分片; 如果 maxChunksNum – minChunksNum 大于迁移的阈值 (threshold), 那么就是不均衡状态,需要迁移,源分片的 chunks 第一个 chunk 为待迁移的 chunk ,构造一个迁移任务(源分片,目的分片,chunk)。
每次 balancer 会检测所有集合的情况,每个集合最多一个迁移任务 ; 而且构造迁移任务时,如果某个集合含有最多数量的分片或者最少数量 chunks 的分片,已经属于某一个迁移任务,那么此集合本轮 balancer 不会发生迁移。最后,本次检测出的迁移任务完成以后才开始下次 balancer 过程。
balancer 过程中,会对集合做一次随机排序,当有多个集合的数据需要均衡时,迁移时也是随机的,并不是迁移完一个集合开始下一个集合。
重点关注上述的迁移阈值,就是这个迁移的阈值 threshold 在 3.2 和 4.0 版本有所不同。
3.2 版本, chunks 数量小于 20 的时候为 2, 小于 80 的时候为 4, 大于 80 的时候为 8 。也就是说假设两分片集群,某个表有 100 个chunk , 每个分片分别有 47 和 53 个chunk 。那么此时 balance 认为是均衡的,不会发生迁移。
int threshold = 8;
if (balancedLastTime || distribution.totalChunks() < 20) threshold = 2;
else if (distribution.totalChunks() < 80) threshold = 4;
4.0 版本,chunks 数量差距大于 2 的时候就会发生迁移。同样的上述例子中,每个分片分别有 47 和 53 个 chunk时, balance 认为是不均衡的,会发生迁移。
const size_t kDefaultImbalanceThreshold = 2; const size_t kAggressiveImbalanceThreshold = 1;
const size_t imbalanceThreshold = (shouldAggressivelyBalance || distribution.totalChunks()
< 20)
? kAggressiveImbalanceThreshold: kDefaultImbalanceThreshold;
// 这里虽然有个 1 ,但是实际差距为 1 的时候不会发生迁移,因为判断迁移时,还有一个指标:平均每个分片的最大 ch
unks 数量,只有当 chunks 数量大于这个值的时候才会发生迁移。
const size_t idealNumberOfChunksPerShardForTag = (totalNumberOfChunksWithTag / totalNumberOfShardsWithTag) + (totalNumberOfChunksWithTag % totalNumberOfShardsWithTag ? 1 : 0);
关于此阈值,官方文档也有介绍:
To minimize the impact of balancing on the cluster, the balancer only begins balancing after the distribution of chunks for a sharded collection has reached certain thresholds. The thresholds apply to the difference in number of chunks between the shard with the most chunks for the collection and the shard with the fewest chunks for that collection. The balancer has the following thresholds:
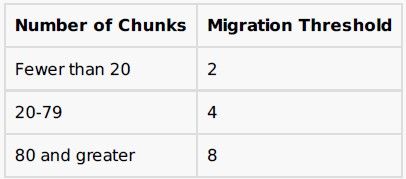
The balancer stops running on the target collection when the difference between the number of chunks on any two shards for that collection is less than two, or a chunk migration fails.
但是从代码上,从3.4 版本开始,此阈值的逻辑就已经变化了,但是文档并没有更新。
moveChunk
moveChunk 是一个比较复杂的动作, 大致过程如下:
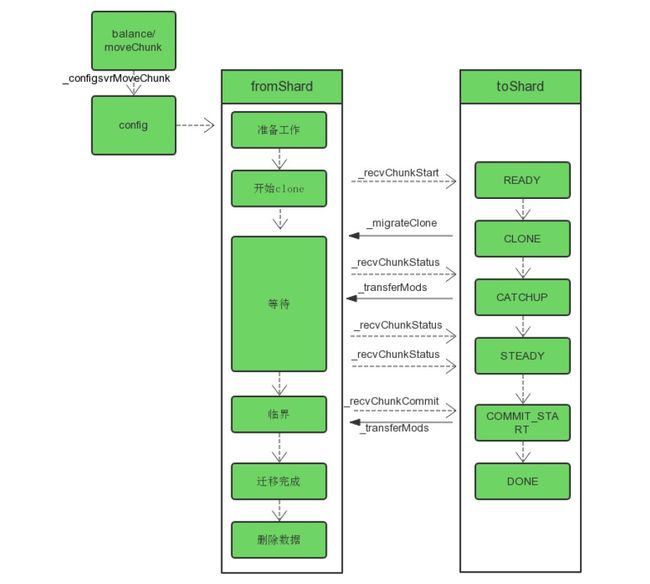
目的分片,首先要删除要移动的 chunk 的数据。所以会有一个删除任务。
可以在 config.settings 设置 _secondaryThrottle 和 waitForDelete 设置 moveChunk 过程中 插入数据和删除数据的 write concern
_secondaryThrottle: true 表示 balancer 插入数据时,至少等待一个 secondary 节点回复;false 表示不等待写到 secondary 节点; 也可以直接设置为 write concern ,则迁移时使用这个 write concern . 3.2 版本默认 true, 3.4 开始版本默认 false;
waitForDelete: 迁移一个 chunk 数据以后,是否同步等待数据删除完毕;默认为 false , 由一个单独的线程异步删除孤儿数据。
设置方式如下:
use config db.settings.update(
{ "_id" : "balancer" },
{ $set : { "_secondaryThrottle" : { "w": "majority" } ,"_waitForDelete" : true } },
{ upsert : true }
)
3.2 版本 _secondaryThrottle 默认 true, 3.4 开始版本默认 false,所以 3 .2 版本和4.0 版本 moveChunk 迁移数据时,4.0版本会更快完成,迁移中 目的分片的每秒 insert 量级也会更多,对 CPU 负载也会有些许的影响。
另外,3.4.18/3.6.10/4.0.5 及之后版本,还有以下参数 (Parameter) 调整插入数据的速度:
migrateCloneInsertionBatchDelayMS: 迁移数据时,每次插入的间隔,默认 0 不等待。
migrateCloneInsertionBatchSize: 迁移数据时,每次插入的数量,默认为 0 无限制。
设置方式如下:
db.adminCommand({setParameter:1,migrateCloneInsertionBatchDelayMS:0})
db.adminCommand({setParameter:1,migrateCloneInsertionBatchSize:0})
异步删除数据线程
3.2 和 4.0 版本的异步删除线程具体实现略有不同,但是,根本过程还是一致的,用一个队列保存需要删除的 range, 循环的取队列的数据删除数据。所以异步删除数据线程是按照 chunk 进入队列的顺序,逐个删除。总入口:
3.2 版本 db/range_deleter.cpp 线程入口 RangeDeleter::doWork()
4.0 版本 db/s/metadata_manager.cpp scheduleCleanup 时会有一个唯一的线程执行清理任务
4.0 版本在删除数据时,按批删除数据,每次删除数量计算方式如下:
maxToDelete = rangeDeleterBatchSize.load();
if (maxToDelete <= 0) {
maxToDelete = std::max(int(internalQueryExecYieldIterations.load()), 1); // 128
}
有较多的参数可以灵活的控制删除速度,默认情况下,900s 以后开始清理 chunks 的数据,每次清理 128 个文档,每隔 20ms 删除一次。具体通过以下参数设置:
rangeDeleterBatchDelayMS: 删除每个 chunk 数据的时候分批次删除,每批之间间隔的时间,单位 ms,默认 20ms;
internalQueryExecYieldIterations: 默认为 128;
rangeDeleterBatchSize:每次删除数据的数量,默认即为0;为0时 ,则每次删除的数量为max(internalQueryExecYieldIterations,1),
orphanCleanupDelaySecs: moveChunk 以后延迟删除数据的时间,单位 s ,默认 900 s
总结
moveChunk 可能对系统的负载产生影响,主要是删除数据阶段的影响,一般迁移中的插入数据影响较小;
3.4 及之后的版本存在 balancer 迁移阈值较低的问题,可能会更频繁的产生 moveChunk;
文档数据多而小的表,而且是 hashed 分片,本应预分配一定的 chunk 以后永久关闭表的 balancer。开启balancer 时,3.2 版本因为均衡阈值较大,较少发生 moveChunk 迁移数据,所以负载较低; 4.0 版本均衡阈值很小,更容易发生迁移,频繁的迁移之后删除数据导致负载较高。
作者:李鹏冲
网易游戏高级运维工程师,MongoDB和MySQL数据库爱好者,目前专注于SAAS平台的开发与运维工作。
感谢MongoDB官方,锦木信息和Tapdata对活动的大力支持!
进入MongoDB技术交流群/投稿/合作 请添加社区助理小英微信 (ID:mongoingcom),添加请备注mongo