在学习jemalloc之前可以了解一下glibc malloc,jemalloc没有'unlinking' 和 'frontlinking'的概念,jemalloc最早使用是在freeBSD系统中,随后firefox浏览器也开始使用jemalloc作为内存分配器,jemalloc是开源的(源码)。glibc是LInux系统默认的mallocer,二者虽然来自不同系统,但并不是完全不同,还是有很多相似之处,两个mallocer支持多线程。
jemalloc同时分配的items也会同时使用,jemalloc支持SMP系统和并发多线程,多线程的支持是依赖于多个‘arenas’,并且一个线程第一次调用内存mallocer,与其相关联的是一个特殊的arena。
线程分配arena只有三种可能的算法:
1、TLS启用的情况下就是线程ID的哈希值
2、TLS不可用并定义MALLOC_BALANCE的情况下通过内置线性同余随机数生成器
3、使用传统的循环算法
对于后两种情况,线程的整个生命周期中线程和arena的关联不会一直保持不变。
jemalloc将内存分成多个chunk,所有的chunk的大小都是一样的,所有的数据都存储在chunks中。Chunks进一步被分为多个run,run负责请求/分配相应大小的内存。一个run记录free和使用的regions的大小。
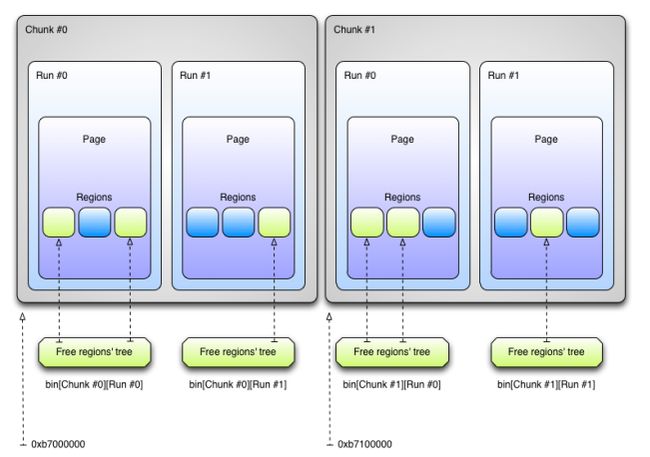
1.arena。jemalloc的核心分配管理区域,对于多核系统,会默认分配4*cores的Arena,线程采取轮询的方式来选择相应的arena来进行内存分配。
2.chunk。具体进行内存分配的区域,目前的默认大小是4M。chunk以page(默认为4K)为单位进行管理,每个chunk的前几个page(默认是6个)用于存储后面所有page的状态,比如是否待分配还是已经分配;而后面的所有page则用于进行实际的分配。
3.bin。用来管理各个不同大小单元的分配,比如最小的Bin管理的是8字节的分配,每个Bin管理的大小都不一样,依次递增。jemalloc的bin和ptmalloc的bin的作用类似。
4.run。每个bin在实际上是通过对它对应的正在运行的Run进行操作来进行分配的,一个run实际上就是chunk里的一块区域,大小是page的整数倍,具体由实际的bin来决定,比如8字节的bin对应的run就只有1个page,可以从里面选取一个8字节的块进行分配。在run的最开头会存储着这个run的信息,比如还有多少个块可供分配。
5.tcache。线程对应的私有缓存空间,默认是使用的。因此在分配内存时首先从tcache中找,miss的情况下才会进入一般的分配流程。
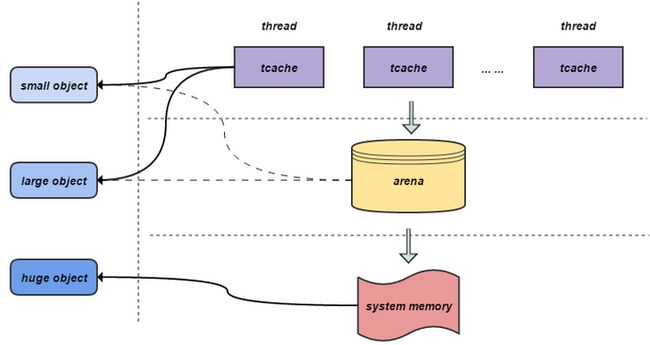
Jemalloc 把内存分配分为了三个部分,
Small objects的size以8字节,16字节,32字节等分隔开的,小于页大小。
Large objects的size以分页为单位,等差间隔排列,小于chunk的大小。
Huge objects的大小是chunk大小的整数倍。
small objects和large objects由arena来管理, huge objects由线程间公用的红黑树管理。
默认64位系统的划分方式如下:
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840] (1-57344分为44档)
Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB] (58345-4MB)
Huge: [4 MiB, 8 MiB, 12 MiB, …] (4MB的整数倍)
接下来介绍它们之间的关系。每个arena有一个bin数组,根据机器配置不同它的具体结构也不同,由相应的size_class.h中的宏定义决定,而每个bin会通过它对应的正在运行的run进行操作来进行分配的。每个tcahe有一个对应的arena,它本身也有一个bin数组(称为tbin),前面的部分与arena的bin数组是对应的,但它长度更大一些,因为它会缓存一些更大的块;而且它也没有对应的run的概念,因为它只做缓存,rnny它只有一个avail数组来存储被缓存的空间的地址。像笔者机器上的tcahe在arena最大的3584字节的bin的基础上,后面还有8个bin,分别对应4K,8K,12K一直到32K。
这里想重点介绍一下chunk与run的关系。之前提到chunk默认是4M,而run是在chunk中进行实际分配的操作对象,每次有新的分配请求时一旦tcache无法满足要求,就要通过run进行操作,如果没有对应的run存在就要新建一个,哪怕只分配一个块,比如只申请一个8字节的块,也会生成一个大小为一个page(默认4K)的run;再申请一个16字节的块,又会生成一个大小为4096字节的run。run的具体大小由它对应的bin决定,但一定是page的整数倍。因此实际上每个chunk就被分成了一个个的run。
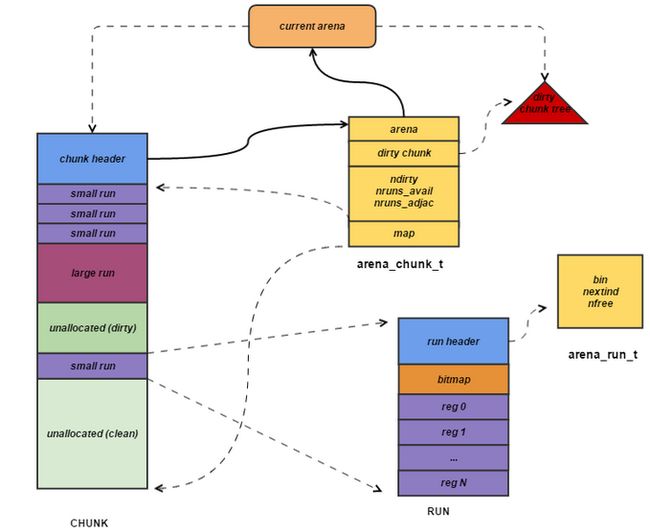
arena:
struct arena_s {
/* This arena's index within the arenas array. */
unsigned ind;
/*
* Number of threads currently assigned to this arena. This field is
* protected by arenas_lock.
*/
unsigned nthreads;
/*
* There are three classes of arena operations from a locking
* perspective:
* 1) Thread assignment (modifies nthreads) is protected by arenas_lock.
* 2) Bin-related operations are protected by bin locks.
* 3) Chunk- and run-related operations are protected by this mutex.
*/
malloc_mutex_t lock;
arena_stats_t stats;
/*
* List of tcaches for extant threads associated with this arena.
* Stats from these are merged incrementally, and at exit if
* opt_stats_print is enabled.
*/
ql_head(tcache_t) tcache_ql;
uint64_t prof_accumbytes;
/*
* PRNG state for cache index randomization of large allocation base
* pointers.
*/
uint64_t offset_state;
dss_prec_t dss_prec;
/*
* In order to avoid rapid chunk allocation/deallocation when an arena
* oscillates right on the cusp of needing a new chunk, cache the most
* recently freed chunk. The spare is left in the arena's chunk trees
* until it is deleted.
*
* There is one spare chunk per arena, rather than one spare total, in
* order to avoid interactions between multiple threads that could make
* a single spare inadequate.
*/
arena_chunk_t *spare;
/* Minimum ratio (log base 2) of nactive:ndirty. */
ssize_t lg_dirty_mult;
/* Number of pages in active runs and huge regions. */
size_t nactive;
/*
* Current count of pages within unused runs that are potentially
* dirty, and for which madvise(... MADV_DONTNEED) has not been called.
* By tracking this, we can institute a limit on how much dirty unused
* memory is mapped for each arena.
*/
size_t ndirty;
/*
* Size/address-ordered tree of this arena's available runs. The tree
* is used for first-best-fit run allocation.
*/
arena_avail_tree_t runs_avail;
/*
* Unused dirty memory this arena manages. Dirty memory is conceptually
* tracked as an arbitrarily interleaved LRU of dirty runs and cached
* chunks, but the list linkage is actually semi-duplicated in order to
* avoid extra arena_chunk_map_misc_t space overhead.
*
* LRU-----------------------------------------------------------MRU
*
* /-- arena ---\
* | |
* | |
* |------------| /- chunk -\
* ...->|chunks_cache|<--------------------------->| /----\ |<--...
* |------------| | |node| |
* | | | | | |
* | | /- run -\ /- run -\ | | | |
* | | | | | | | | | |
* | | | | | | | | | |
* |------------| |-------| |-------| | |----| |
* ...->|runs_dirty |<-->|rd |<-->|rd |<---->|rd |<----...
* |------------| |-------| |-------| | |----| |
* | | | | | | | | | |
* | | | | | | | \----/ |
* | | \-------/ \-------/ | |
* | | | |
* | | | |
* \------------/ \---------/
*/
arena_runs_dirty_link_t runs_dirty;
extent_node_t chunks_cache;
/* Extant huge allocations. */
ql_head(extent_node_t) huge;
/* Synchronizes all huge allocation/update/deallocation. */
malloc_mutex_t huge_mtx;
/*
* Trees of chunks that were previously allocated (trees differ only in
* node ordering). These are used when allocating chunks, in an attempt
* to re-use address space. Depending on function, different tree
* orderings are needed, which is why there are two trees with the same
* contents.
*/
extent_tree_t chunks_szad_cache;
extent_tree_t chunks_ad_cache;
extent_tree_t chunks_szad_mmap;
extent_tree_t chunks_ad_mmap;
extent_tree_t chunks_szad_dss;
extent_tree_t chunks_ad_dss;
malloc_mutex_t chunks_mtx;
/* Cache of nodes that were allocated via base_alloc(). */
ql_head(extent_node_t) node_cache;
malloc_mutex_t node_cache_mtx;
/*
* User-configurable chunk allocation/deallocation/purge functions.
*/
chunk_alloc_t *chunk_alloc;
chunk_dalloc_t *chunk_dalloc;
chunk_purge_t *chunk_purge;
/* bins is used to store trees of free regions. */
arena_bin_t bins[NBINS];
};
arena内bin
struct arena_bin_s {
/*
* All operations on runcur, runs, and stats require that lock be
* locked. Run allocation/deallocation are protected by the arena lock,
* which may be acquired while holding one or more bin locks, but not
* vise versa.
*/
malloc_mutex_t lock;
/*
* Current run being used to service allocations of this bin's size
* class.
*/
arena_run_t *runcur;
/*
* Tree of non-full runs. This tree is used when looking for an
* existing run when runcur is no longer usable. We choose the
* non-full run that is lowest in memory; this policy tends to keep
* objects packed well, and it can also help reduce the number of
* almost-empty chunks.
*/
arena_run_tree_t runs;
/* Bin statistics. */
malloc_bin_stats_t stats;
};
tcache
struct tcache_s {
ql_elm(tcache_t) link; /* Used for aggregating stats. */
uint64_t prof_accumbytes;/* Cleared after arena_prof_accum(). */
unsigned ev_cnt; /* Event count since incremental GC. */
index_t next_gc_bin; /* Next bin to GC. */
tcache_bin_t tbins[1]; /* Dynamically sized. */
/*
* The pointer stacks associated with tbins follow as a contiguous
* array. During tcache initialization, the avail pointer in each
* element of tbins is initialized to point to the proper offset within
* this array.
*/
};
tcache内bin
struct tcache_bin_s {
tcache_bin_stats_t tstats;
int low_water; /* Min # cached since last GC. */
unsigned lg_fill_div; /* Fill (ncached_max >> lg_fill_div). */
unsigned ncached; /* # of cached objects. */
/*
* To make use of adjacent cacheline prefetch, the items in the avail
* stack goes to higher address for newer allocations. avail points
* just above the available space, which means that
* avail[-ncached, ... -1] are available items and the lowest item will
* be allocated first.
*/
void **avail; /* Stack of available objects. */
};
run
struct arena_run_s {
/* Index of bin this run is associated with. */
index_t binind;
/* Number of free regions in run. */
unsigned nfree;
/* Per region allocated/deallocated bitmap. */
bitmap_t bitmap[BITMAP_GROUPS_MAX];
};
chunk
struct arena_chunk_s {
/*
* A pointer to the arena that owns the chunk is stored within the node.
* This field as a whole is used by chunks_rtree to support both
* ivsalloc() and core-based debugging.
*/
extent_node_t node;
/*
* Map of pages within chunk that keeps track of free/large/small. The
* first map_bias entries are omitted, since the chunk header does not
* need to be tracked in the map. This omission saves a header page
* for common chunk sizes (e.g. 4 MiB).
*/
arena_chunk_map_bits_t map_bits[1]; /* Dynamically sized. */
};
内存分配
jemalloc 的内存分配,可分成四类:
1、small:如果请求size不大于arena的最小的bin,那么就通过线程对应的tcache来进行分配。首先确定size的大小属于哪一个tbin,比如2字节的size就属于最小的8字节的tbin,然后查找tbin中有没有缓存的空间,如果有就进行分配,没有则为这个tbin对应的arena的bin分配一个run,然后把这个run里面的部分块的地址依次赋给tcache的对应的bin的avail数组,相当于缓存了一部分的8字节的块,最后从这个availl数组中选取一个地址进行分配;
2、large: 如果请求size大于arena的最小的bin,同时不大于tcache能缓存的最大块,也会通过线程对应的tcache来进行分配,但方式不同。首先看tcache对应的tbin里有没有缓存块,如果有就分配,没有就从chunk里直接找一块相应的page整数倍大小的空间进行分配(当这块空间后续释放时,这会进入相应的tcache对应的tbin里);
3、large: 如果请求size大于tcache能缓存的最大块,同时不大于chunk大小(默认是4M),具体分配和第2类请求相同,区别只是没有使用tcache;
4、huge(size> chunk ):如果请求大于chunk大小,直接通过mmap进行分配。
函数调用关系je_malloc(jemalloc.c)->imalloc_body(jemalloc.c)->imalloc(jemalloc_internal.h)->iallocztm(jemalloc_internal.h)->arena_malloc(arena.h)
定义在arena.h文件中
JEMALLOC_ALWAYS_INLINE void *
arena_malloc(tsd_t *tsd, arena_t *arena, size_t size, bool zero,
tcache_t *tcache)
{
assert(size != 0);
arena = arena_choose(tsd, arena);
if (unlikely(arena == NULL))
return (NULL);
if (likely(size <= SMALL_MAXCLASS)) {
if (likely(tcache != NULL)) {
return (tcache_alloc_small(tsd, arena, tcache, size,
zero));
} else
return (arena_malloc_small(arena, size, zero));
} else if (likely(size <= arena_maxclass)) {
/*
* Initialize tcache after checking size in order to avoid
* infinite recursion during tcache initialization.
*/
if (likely(tcache != NULL) && size <= tcache_maxclass) {
return (tcache_alloc_large(tsd, arena, tcache, size,
zero));
} else
return (arena_malloc_large(arena, size, zero));
} else
return (huge_malloc(tsd, arena, size, zero, tcache));
}
如果要分配的内存大小属于small object,且线程tcache不为空
JEMALLOC_ALWAYS_INLINE void *
tcache_alloc_easy(tcache_bin_t *tbin)
{
void *ret;
if (unlikely(tbin->ncached == 0)) {
tbin->low_water = -1;
return (NULL);
}
tbin->ncached--;
if (unlikely((int)tbin->ncached < tbin->low_water))
tbin->low_water = tbin->ncached;
ret = tbin->avail[tbin->ncached];
return (ret);
}
JEMALLOC_ALWAYS_INLINE void *
tcache_alloc_small(tsd_t *tsd, arena_t *arena, tcache_t *tcache, size_t size,
bool zero)
{
void *ret;
index_t binind;
size_t usize;
tcache_bin_t *tbin;
binind = size2index(size);
assert(binind < NBINS);
tbin = &tcache->tbins[binind];
usize = index2size(binind);
ret = tcache_alloc_easy(tbin);
if (unlikely(ret == NULL)) {
ret = tcache_alloc_small_hard(tsd, arena, tcache, tbin, binind);
if (ret == NULL)
return (NULL);
}
.........( chunk > size > tcache )
return (ret);
}
void *
tcache_alloc_small_hard(tsd_t *tsd, arena_t *arena, tcache_t *tcache,
tcache_bin_t *tbin, index_t binind)
{
void *ret;
arena_tcache_fill_small(arena, tbin, binind, config_prof ?
tcache->prof_accumbytes : 0);
if (config_prof)
tcache->prof_accumbytes = 0;
ret = tcache_alloc_easy(tbin);
return (ret);
}
void
arena_tcache_fill_small(arena_t *arena, tcache_bin_t *tbin, index_t binind,
uint64_t prof_accumbytes)
{
unsigned i, nfill;
arena_bin_t *bin;
arena_run_t *run;
void *ptr;
assert(tbin->ncached == 0);
if (config_prof && arena_prof_accum(arena, prof_accumbytes))
prof_idump();
bin = &arena->bins[binind];
malloc_mutex_lock(&bin->lock);
for (i = 0, nfill = (tcache_bin_info[binind].ncached_max >>
tbin->lg_fill_div); i < nfill; i++) {
if ((run = bin->runcur) != NULL && run->nfree > 0)
ptr = arena_run_reg_alloc(run, &arena_bin_info[binind]);
else
ptr = arena_bin_malloc_hard(arena, bin);
if (ptr == NULL) {
/*
* OOM. tbin->avail isn't yet filled down to its first
* element, so the successful allocations (if any) must
* be moved to the base of tbin->avail before bailing
* out.
*/
if (i > 0) {
memmove(tbin->avail, &tbin->avail[nfill - i],
i * sizeof(void *));
}
break;
}
if (config_fill && unlikely(opt_junk_alloc)) {
arena_alloc_junk_small(ptr, &arena_bin_info[binind],
true);
}
/* Insert such that low regions get used first. */
tbin->avail[nfill - 1 - i] = ptr;
}
if (config_stats) {
bin->stats.nmalloc += i;
bin->stats.nrequests += tbin->tstats.nrequests;
bin->stats.curregs += i;
bin->stats.nfills++;
tbin->tstats.nrequests = 0;
}
malloc_mutex_unlock(&bin->lock);
tbin->ncached = i;
}
通过函数tcache_alloc_easy分配tcache中的内存,如果失败则调用tcache_alloc_small_hard函数在arena对应的run中分配。同时保存在tcache的avail数组中,相当于缓存到tcache中。
/* Re-fill bin->runcur, then call arena_run_reg_alloc(). */
static void *
arena_bin_malloc_hard(arena_t *arena, arena_bin_t *bin)
{
void *ret;
index_t binind;
arena_bin_info_t *bin_info;
arena_run_t *run;
binind = arena_bin_index(arena, bin);
bin_info = &arena_bin_info[binind];
bin->runcur = NULL;
run = arena_bin_nonfull_run_get(arena, bin);
if (bin->runcur != NULL && bin->runcur->nfree > 0) {
/*
* Another thread updated runcur while this one ran without the
* bin lock in arena_bin_nonfull_run_get().
*/
assert(bin->runcur->nfree > 0);
ret = arena_run_reg_alloc(bin->runcur, bin_info);
if (run != NULL) {
arena_chunk_t *chunk;
/*
* arena_run_alloc_small() may have allocated run, or
* it may have pulled run from the bin's run tree.
* Therefore it is unsafe to make any assumptions about
* how run has previously been used, and
* arena_bin_lower_run() must be called, as if a region
* were just deallocated from the run.
*/
chunk = (arena_chunk_t *)CHUNK_ADDR2BASE(run);
if (run->nfree == bin_info->nregs)
arena_dalloc_bin_run(arena, chunk, run, bin);
else
arena_bin_lower_run(arena, chunk, run, bin);
}
return (ret);
}
if (run == NULL)
return (NULL);
bin->runcur = run;
assert(bin->runcur->nfree > 0);
return (arena_run_reg_alloc(bin->runcur, bin_info));
}
JEMALLOC_INLINE_C void *
arena_run_reg_alloc(arena_run_t *run, arena_bin_info_t *bin_info)
{
void *ret;
unsigned regind;
arena_chunk_map_misc_t *miscelm;
void *rpages;
assert(run->nfree > 0);
assert(!bitmap_full(run->bitmap, &bin_info->bitmap_info));
regind = bitmap_sfu(run->bitmap, &bin_info->bitmap_info);
miscelm = arena_run_to_miscelm(run);
rpages = arena_miscelm_to_rpages(miscelm);
ret = (void *)((uintptr_t)rpages + (uintptr_t)bin_info->reg0_offset +
(uintptr_t)(bin_info->reg_interval * regind));
run->nfree--;
return (ret);
}
arena_tcache_fill_small函数会判断arena数组中的bin对应的run是否为空,如果为空就调用arena_bin_malloc_hard函数新建run再调用arena_run_reg_alloc分配内存。注意:run中采用bitmap记录分配区域的状态, 相比采用空闲列表的方式, 采用bitmap具有以下优点:bitmap能够快速计算出第一块空闲区域,且能很好的保证已分配区域的紧凑型。分配数据与应用数据是隔离的,能够减少应用数据对分配数据的干扰。对很小的分配区域的支持更好。
回到arena_malloc_small函数,逻辑与arena_tcache_fill_small相似,就不再赘述。
下面看一下当申请的内存属于large object的情况
当申请内存小于tcache最大的object且支持tcache,调用tcache_alloc_large
JEMALLOC_ALWAYS_INLINE void *
tcache_alloc_large(tsd_t *tsd, arena_t *arena, tcache_t *tcache, size_t size,
bool zero)
{
void *ret;
index_t binind;
size_t usize;
tcache_bin_t *tbin;
binind = size2index(size);
usize = index2size(binind);
assert(usize <= tcache_maxclass);
assert(binind < nhbins);
tbin = &tcache->tbins[binind];
ret = tcache_alloc_easy(tbin);
if (unlikely(ret == NULL)) {
/*
* Only allocate one large object at a time, because it's quite
* expensive to create one and not use it.
*/
ret = arena_malloc_large(arena, usize, zero);
if (ret == NULL)
return (NULL);
} else {
if (config_prof && usize == LARGE_MINCLASS) {
arena_chunk_t *chunk =
(arena_chunk_t *)CHUNK_ADDR2BASE(ret);
size_t pageind = (((uintptr_t)ret - (uintptr_t)chunk) >>
LG_PAGE);
arena_mapbits_large_binind_set(chunk, pageind,
BININD_INVALID);
}
if (likely(!zero)) {
if (config_fill) {
if (unlikely(opt_junk_alloc))
memset(ret, 0xa5, usize);
else if (unlikely(opt_zero))
memset(ret, 0, usize);
}
} else
memset(ret, 0, usize);
if (config_stats)
tbin->tstats.nrequests++;
if (config_prof)
tcache->prof_accumbytes += usize;
}
tcache_event(tsd, tcache);
return (ret);
}
可以看到程序首先还是会从tcache分配内存,如果tcache有空闲内存则分配给程序否则将调用arena_malloc_large函数直接从arena分配
void *
arena_malloc_large(arena_t *arena, size_t size, bool zero)
{
void *ret;
size_t usize;
uint64_t r;
uintptr_t random_offset;
arena_run_t *run;
arena_chunk_map_misc_t *miscelm;
UNUSED bool idump;
/* Large allocation. */
usize = s2u(size);
malloc_mutex_lock(&arena->lock);
if (config_cache_oblivious) {
/*
* Compute a uniformly distributed offset within the first page
* that is a multiple of the cacheline size, e.g. [0 .. 63) * 64
* for 4 KiB pages and 64-byte cachelines.
*/
prng64(r, LG_PAGE - LG_CACHELINE, arena->offset_state,
UINT64_C(6364136223846793009), UINT64_C(1442695040888963409));
random_offset = ((uintptr_t)r) << LG_CACHELINE;
} else
random_offset = 0;
run = arena_run_alloc_large(arena, usize + large_pad, zero);
if (run == NULL) {
malloc_mutex_unlock(&arena->lock);
return (NULL);
}
miscelm = arena_run_to_miscelm(run);
ret = (void *)((uintptr_t)arena_miscelm_to_rpages(miscelm) +
random_offset);
if (config_stats) {
index_t index = size2index(usize) - NBINS;
arena->stats.nmalloc_large++;
arena->stats.nrequests_large++;
arena->stats.allocated_large += usize;
arena->stats.lstats[index].nmalloc++;
arena->stats.lstats[index].nrequests++;
arena->stats.lstats[index].curruns++;
}
if (config_prof)
idump = arena_prof_accum_locked(arena, usize);
malloc_mutex_unlock(&arena->lock);
if (config_prof && idump)
prof_idump();
if (!zero) {
if (config_fill) {
if (unlikely(opt_junk_alloc))
memset(ret, 0xa5, usize);
else if (unlikely(opt_zero))
memset(ret, 0, usize);
}
}
return (ret);
}
static arena_run_t *
arena_run_first_best_fit(arena_t *arena, size_t size)
{
size_t search_size = run_quantize_first(size);
arena_chunk_map_misc_t *key = (arena_chunk_map_misc_t *)
(search_size | CHUNK_MAP_KEY);
arena_chunk_map_misc_t *miscelm =
arena_avail_tree_nsearch(&arena->runs_avail, key);
if (miscelm == NULL)
return (NULL);
return (&miscelm->run);
}
static arena_run_t *
arena_run_alloc_large_helper(arena_t *arena, size_t size, bool zero)
{
arena_run_t *run = arena_run_first_best_fit(arena, s2u(size));
if (run != NULL)
arena_run_split_large(arena, run, size, zero);
return (run);
}
static arena_run_t *
arena_run_alloc_large(arena_t *arena, size_t size, bool zero)
{
arena_chunk_t *chunk;
arena_run_t *run;
assert(size <= arena_maxrun);
assert(size == PAGE_CEILING(size));
/* Search the arena's chunks for the lowest best fit. */
run = arena_run_alloc_large_helper(arena, size, zero);
if (run != NULL)
return (run);
/*
* No usable runs. Create a new chunk from which to allocate the run.
*/
chunk = arena_chunk_alloc(arena);
if (chunk != NULL) {
run = &arena_miscelm_get(chunk, map_bias)->run;
arena_run_split_large(arena, run, size, zero);
return (run);
}
/*
* arena_chunk_alloc() failed, but another thread may have made
* sufficient memory available while this one dropped arena->lock in
* arena_chunk_alloc(), so search one more time.
*/
return (arena_run_alloc_large_helper(arena, size, zero));
}
arena_malloc_large中首先会计算一个随机偏移,随后调用arena_run_alloc_large分配新的run。在arena_run_alloc_large中,我们可以看到arena_run_first_best_fit中通过树(Size/address-ordered tree)查找到可用的run,如果没有可用的run就通过arena_chunk_alloc函数创建新的chunk,在新建的chunk中分配run。
在arena_chunk_alloc中,程序首先会判断arena结构体中的spare是否为空,这个spare是arena缓存的最近释放的chunk,也就是说如果最近释放的chunk存在则调用arena_chunk_init_spare否则调用arena_chunk_init_hard。arena_chunk_init_spare很简单直接将spare重新分配;
static arena_chunk_t *
arena_chunk_alloc(arena_t *arena)
{
arena_chunk_t *chunk;
if (arena->spare != NULL)
chunk = arena_chunk_init_spare(arena);
else {
chunk = arena_chunk_init_hard(arena);
if (chunk == NULL)
return (NULL);
}
/* Insert the run into the runs_avail tree. */
arena_avail_insert(arena, chunk, map_bias, chunk_npages-map_bias);
return (chunk);
}
arena_chunk_init_hard函数会调用arena_chunk_alloc_internal函数
static arena_chunk_t *
arena_chunk_alloc_internal(arena_t *arena, bool *zero)
{
arena_chunk_t *chunk;
if (likely(arena->chunk_alloc == chunk_alloc_default)) {
chunk = chunk_alloc_cache(arena, NULL, chunksize, chunksize,
zero, true);
if (chunk != NULL && arena_chunk_register(arena, chunk,
*zero)) {
chunk_dalloc_cache(arena, chunk, chunksize);
return (NULL);
}
} else
chunk = NULL;
if (chunk == NULL)
chunk = arena_chunk_alloc_internal_hard(arena, zero);
if (config_stats && chunk != NULL) {
arena->stats.mapped += chunksize;
arena->stats.metadata_mapped += (map_bias << LG_PAGE);
}
return (chunk);
}
首先会调用chunk_alloc_cache来分配chunk,在chunk_alloc_cache实际是通过查找arena中extent_tree来分配chunk,这个extent_tree也是一个红黑树,这个红黑树保存着之前分配并使用过的chunk。随后调用arena_chunk_register进行初始化和注册等工作。如果分配失败程序则调用arena_chunk_alloc_internal_hard函数分配新的chunk
static arena_chunk_t *
arena_chunk_alloc_internal_hard(arena_t *arena, bool *zero)
{
arena_chunk_t *chunk;
chunk_alloc_t *chunk_alloc = arena->chunk_alloc;
chunk_dalloc_t *chunk_dalloc = arena->chunk_dalloc;
malloc_mutex_unlock(&arena->lock);
chunk = (arena_chunk_t *)chunk_alloc_wrapper(arena, chunk_alloc, NULL,
chunksize, chunksize, zero);
if (chunk != NULL && arena_chunk_register(arena, chunk, *zero)) {
chunk_dalloc_wrapper(arena, chunk_dalloc, (void *)chunk,
chunksize);
chunk = NULL;
}
malloc_mutex_lock(&arena->lock);
return (chunk);
}
void *
chunk_alloc_wrapper(arena_t *arena, chunk_alloc_t *chunk_alloc, void *new_addr,
size_t size, size_t alignment, bool *zero)
{
void *ret;
ret = chunk_alloc(new_addr, size, alignment, zero, arena->ind);
if (ret == NULL)
return (NULL);
if (config_valgrind && chunk_alloc != chunk_alloc_default)
JEMALLOC_VALGRIND_MAKE_MEM_UNDEFINED(ret, chunksize);
return (ret);
}
最终是通过chunk_alloc函数从系统内存中分配新的chunk,同样进行初始化和注册等操作。至此large的分配结束。
下面看一下huge的情况:
void *
huge_malloc(tsd_t *tsd, arena_t *arena, size_t size, bool zero,
tcache_t *tcache)
{
size_t usize;
usize = s2u(size);
if (usize == 0) {
/* size_t overflow. */
return (NULL);
}
return (huge_palloc(tsd, arena, usize, chunksize, zero, tcache));
}
void *
huge_palloc(tsd_t *tsd, arena_t *arena, size_t usize, size_t alignment,
bool zero, tcache_t *tcache)
{
void *ret;
extent_node_t *node;
bool is_zeroed;
/* Allocate one or more contiguous chunks for this request. */
/* Allocate an extent node with which to track the chunk. */
node = ipallocztm(tsd, CACHELINE_CEILING(sizeof(extent_node_t)),
CACHELINE, false, tcache, true, arena);
if (node == NULL)
return (NULL);
/*
* Copy zero into is_zeroed and pass the copy to chunk_alloc(), so that
* it is possible to make correct junk/zero fill decisions below.
*/
is_zeroed = zero;
/* ANDROID change */
#if !defined(__LP64__)
/* On 32 bit systems, using a per arena cache can exhaust
* virtual address space. Force all huge allocations to
* always take place in the first arena.
*/
arena = a0get();
#else
arena = arena_choose(tsd, arena);
#endif
/* End ANDROID change */
if (unlikely(arena == NULL) || (ret = arena_chunk_alloc_huge(arena,
usize, alignment, &is_zeroed)) == NULL) {
idalloctm(tsd, node, tcache, true);
return (NULL);
}
extent_node_init(node, arena, ret, usize, is_zeroed);
if (huge_node_set(ret, node)) {
arena_chunk_dalloc_huge(arena, ret, usize);
idalloctm(tsd, node, tcache, true);
return (NULL);
}
/* Insert node into huge. */
malloc_mutex_lock(&arena->huge_mtx);
ql_elm_new(node, ql_link);
ql_tail_insert(&arena->huge, node, ql_link);
malloc_mutex_unlock(&arena->huge_mtx);
if (zero || (config_fill && unlikely(opt_zero))) {
if (!is_zeroed)
memset(ret, 0, usize);
} else if (config_fill && unlikely(opt_junk_alloc))
memset(ret, 0xa5, usize);
return (ret);
}
void *
arena_chunk_alloc_huge(arena_t *arena, size_t usize, size_t alignment,
bool *zero)
{
void *ret;
chunk_alloc_t *chunk_alloc;
size_t csize = CHUNK_CEILING(usize);
malloc_mutex_lock(&arena->lock);
/* Optimistically update stats. */
if (config_stats) {
arena_huge_malloc_stats_update(arena, usize);
arena->stats.mapped += usize;
}
arena->nactive += (usize >> LG_PAGE);
chunk_alloc = arena->chunk_alloc;
if (likely(chunk_alloc == chunk_alloc_default)) {
ret = chunk_alloc_cache(arena, NULL, csize, alignment, zero,
true);
} else
ret = NULL;
malloc_mutex_unlock(&arena->lock);
if (ret == NULL) {
ret = arena_chunk_alloc_huge_hard(arena, chunk_alloc, usize,
alignment, zero, csize);
}
if (config_stats && ret != NULL)
stats_cactive_add(usize);
return (ret);
}
static void *
arena_chunk_alloc_huge_hard(arena_t *arena, chunk_alloc_t *chunk_alloc,
size_t usize, size_t alignment, bool *zero, size_t csize)
{
void *ret;
ret = chunk_alloc_wrapper(arena, chunk_alloc, NULL, csize, alignment,
zero);
if (ret == NULL) {
/* Revert optimistic stats updates. */
malloc_mutex_lock(&arena->lock);
if (config_stats) {
arena_huge_malloc_stats_update_undo(arena, usize);
arena->stats.mapped -= usize;
}
arena->nactive -= (usize >> LG_PAGE);
malloc_mutex_unlock(&arena->lock);
}
return (ret);
}
当申请的内存为huge的情况下,huge_palloc中首先分配一个extent_node的chunk,注释中也注明这个chunk是用来“跟踪”新分配的chunk,随后就是申请一个独立的arena,随后调用arena_chunk_alloc_huge进行实际的分配;
同样是调用chunk_alloc_cache函数分配新的chunk,这个函数之前使用过。如果分配失败则调用arena_chunk_alloc_huge_hard来分配,又看见了熟悉的函数。
简而言之,就是:
小内存(small class): 线程缓存bin -> 分配区bin(bin加锁) -> 问系统要
中型内存(large class):分配区bin(bin加锁) -> 问系统要
大内存(huge class): 直接mmap组织成N个chunk+全局huge红黑树维护(带缓存)
内存释放
回收流程大体和分配流程类似,有tcache机制的会将回收的块进行缓存,没有tcache机制的直接回收(不大于chunk的将对应的page状态进行修改,回收对应的run;大于chunk的直接munmap)。需要关注的是jemalloc何时会将内存还给操作系统,因为ptmalloc中存在因为使用top_chunk机制(详见华庭的文章)而使得内存无法还给操作系统的问题。目前看来,除了大内存直接munmap,jemalloc还有两种机制可以释放内存:
- 当释放时发现某个chunk的所有内存都已经为脏(即分配后又回收)就把整个chunk释放;
- 当arena中的page分配情况满足一个阈值时对dirty page进行purge(通过调用madvise来进行)。这个阈值的具体含义是该arena中的dirty page大小已经达到一个chunk的大小且占到了active page的1/opt_lg_dirty_mult(默认为1/32)。active page的意思是已经正在使用中的run的page,而dirty page就是其中已经分配后又回收的page。
内存释放时的函数调用关系:
je_malloc->ifree->iqalloc->idalloctm->arena_dalloc
JEMALLOC_ALWAYS_INLINE void
arena_dalloc(tsd_t *tsd, void *ptr, tcache_t *tcache)
{
arena_chunk_t *chunk;
size_t pageind, mapbits;
assert(ptr != NULL);
chunk = (arena_chunk_t *)CHUNK_ADDR2BASE(ptr);
if (likely(chunk != ptr)) {
pageind = ((uintptr_t)ptr - (uintptr_t)chunk) >> LG_PAGE;
if defined(ANDROID)
/* Verify the ptr is actually in the chunk. */
if (unlikely(pageind < map_bias || pageind >= chunk_npages)) {
__libc_fatal_no_abort("Invalid address %p passed to free: invalid page index", ptr);
return;
}
endif
mapbits = arena_mapbits_get(chunk, pageind);
assert(arena_mapbits_allocated_get(chunk, pageind) != 0);
if defined(ANDROID)
/* Verify the ptr has been allocated. */
if (unlikely((mapbits & CHUNK_MAP_ALLOCATED) == 0)) {
__libc_fatal("Invalid address %p passed to free: value not allocated", ptr);
}
endif
if (likely((mapbits & CHUNK_MAP_LARGE) == 0)) {
/* Small allocation. */
if (likely(tcache != NULL)) {
index_t binind = arena_ptr_small_binind_get(ptr,
mapbits);
tcache_dalloc_small(tsd, tcache, ptr, binind);
} else {
arena_dalloc_small(extent_node_arena_get(
&chunk->node), chunk, ptr, pageind);
}
} else {
size_t size = arena_mapbits_large_size_get(chunk,
pageind);
assert(config_cache_oblivious || ((uintptr_t)ptr &
PAGE_MASK) == 0);
if (likely(tcache != NULL) && size - large_pad <=
tcache_maxclass) {
tcache_dalloc_large(tsd, tcache, ptr, size -
large_pad);
} else {
arena_dalloc_large(extent_node_arena_get(
&chunk->node), chunk, ptr);
}
}
} else
huge_dalloc(tsd, ptr, tcache);
}
本文参考:
内存分配器jemalloc学习笔记
jemalloc原理分析
ptmalloc,tcmalloc和jemalloc内存分配策略研究
几种malloc实现原理 ptmalloc(glibc) && tcmalloc(google) && jemalloc(facebook)