小概
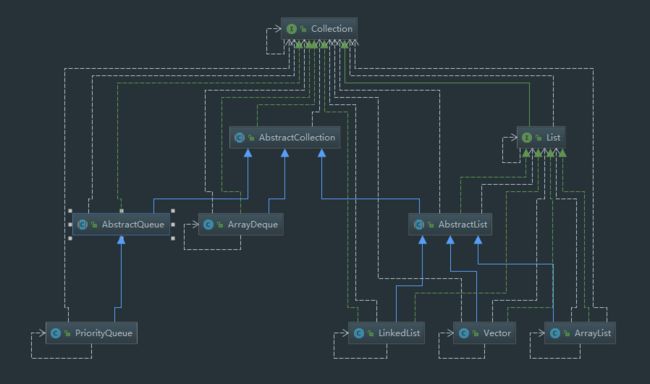
本文将着重介绍 List 与 Queue 中几种常用容器的实现原理,相关 UML 图如上
Collection 作为容器最顶层接口,规范了容器应该具备 增删查、容器 转数组 等能力
- add、remove
- iterate
- contains
- empty
- toArray
- clear
List 继承自 Collection,主要具备对容器元素的 索引、排序 和 截取 功能
- get(index), add(index, item),set(index, item)...
- sort
- subList
Queue 作为队列,具备 出队,入队 的能力
- offer
- poll
- peek
Deque 扩展 Queue,作为双端队列,能够 双向出队与入队,由于这一特性,同时又兼具 栈 的能力,而且容器框架虽然实现了 Stack 类,但官方并不推荐使用,Deque 完全可以取而代之
- offerFirst
- offerLast
- peekFirst
- peekLast
- pollFirst
- pollLast
- pop
- push
泛型
Java 支持泛型,但这只是一块很甜的语法糖,在 JVM 中泛型的实现却是假的,我们在这里假设泛型类型为 E,虚拟机只是在编译检查的时候,去检查类型对不对,但编译结束后,会把所有关于 E 类型的元素用 Object 代替,也就是说,内存中不会保留任何关于 E 的信息,这也就是 泛型擦除,如下面两种实现其实是完全一样的
abstract class DemoCollection {
E[] items;
abstract void add(E item);
}
abstract class DemoCollection {
Object[] items;
abstract void add(Object item);
}
但这两种写法在设计上却有很大区别,我们应该用泛型来定义一种规范,然后大家都按照规范来编程,解除对象类型之间的耦合,容器框架更是如此
List Sort
在 List 接口中,定义了 sort 默认实现
default void sort(Comparator c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
先拿到一份 List 的数组快照,然后将该快照进行排序,最后将有序快照依次赋值给 List
- 如何 toArray 将交给子类来实现,这里只需要知道我具有这个功能,至于如何实现并不重要
- Arrays 作为数组的一个工具类,其中的 sort 方法我们将在其他文章中讨论,它采用的是 快速排序 [1] 和优化的 归并排序 [2]
ArrayList
ArrayList,使用频率最高的 List,是一种自扩容数组,内部维护了一个 数组,容器所有的操作将针对这个数组进行相应改动
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
{
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
// ...
}
我们使用数组的时候,数组的大小限定往往最令人头疼,然而 Jdk 给出的 ArrayList 便能让我们方便的对数组进行业务操作,同时又不用考虑数组大小的限定
现在我们作出如下假设
- 内部数组为 array
- 数组大小为 arrayCapacity
- 元素大小为 itemCapacity
- 扩容因子为 growFactor
- 数组最大大小 maxCapacity
- 数组最小大小 minCapacity
则每次扩容后新的数组大小为
那么我们按一下方式对数组进行扩容
if (itemCapacity > arrayCapacity) {
newCapacity = getNewCapacity();
array = growArray(array, newCapacity);
}
ArrayList 中 growFactor = 0.5, minCapacity = 10 ,maxCapacity = 0x7fffffff - 8,也就是说,初始容量为 10,每次扩容 1.5 倍,最大容量 0x7fffffff - 8
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// ...
}
SubList
ArrayList 中维护了一个私有类 SubList
private class SubList extends AbstractList implements RandomAccess {
private final AbstractList parent;
private final int parentOffset;
private final int offset;
// ...
}
SubList 也作为一种 List,它能够截取自身 ArrayList 的一段数组,在这里,它生成的不是快照,而只是复制的一份 引用
也就是说,你对截取的 SubList 做的任何操作将会直接反映到 ArrayList 堆内存中,这是一个应该值得注意的地方
LinkedList
LinkedList 作为一种 双端链表,采用 链表 链接的方式实现容器,内部维护了一个私有类 Node,也就是说,如果要让 LinkedList 支持索引功能,那将会花费更大的开销
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
{
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node last;
private static class Node {
E item;
Node next;
Node prev;
// ...
}
}
多角色
LinkedList 如果只是当一个 List 用的话,恐怕是太浪费了,如果我们仔细观察下文章开始给的 List 框架设计图,会发现 LinkedList 拥有很多数据结构的功能
LinkedList 作为 索引列表 的同时,既能作为 先进先出队列,又能作为 双端队列,还具备 栈 的能力
也就是说,LinkedList 能够转换成多种角色,这将都归功于面向接口编程的思想
Vector
Vector 是一种 线程安全的自扩容性的数组,内部实现和
ArrayList 差不多一模一样,一个细节的差别在于,Vector 每次扩容是当前容量的 2 倍,而 ArrayList 是 1.5 倍,扩容是一项损耗效率的操作,在并发条件下由为明显,这可能就是两者扩容因子不同设计的初衷
并发
Vector 被设计为线程安全的容器,内部采用最传统的方式,对大部分访问的方法都加全局锁
也就是说,高并发竞争条件下,大家在访问上锁的方法时,都需要排队获取
Vector 在高并发的条件下,效率是非常低下的,因此及其 不推荐使用 该类,如果需要线程共享时,我们甚至可以采取其他措施来实现,或者考虑 CopyOnWriteArrayList
ArrayDeque
ArrayDeque 使用 数组实现双端队列,内部维护两个索引 head 与 tail,分别指向队头和队尾,当对队列进行对结构有变动的操作时,会立即 同步 到这两个索引
public class ArrayDeque extends AbstractCollection
implements Deque, Cloneable, Serializable
{
/**
* The array in which the elements of the deque are stored.
* The capacity of the deque is the length of this array, which is
* always a power of two. The array is never allowed to become
* full, except transiently within an addX method where it is
* resized (see doubleCapacity) immediately upon becoming full,
* thus avoiding head and tail wrapping around to equal each
* other. We also guarantee that all array cells not holding
* deque elements are always null.
*/
transient Object[] elements; // non-private to simplify nested class access
/**
* The index of the element at the head of the deque (which is the
* element that would be removed by remove() or pop()); or an
* arbitrary number equal to tail if the deque is empty.
*/
transient int head;
/**
* The index at which the next element would be added to the tail
* of the deque (via addLast(E), add(E), or push(E)).
*/
transient int tail;
}
一开始 head 是在 tail 左边的,即入队时是 tail++,随着我们对容器的操作,head 与 tail 会随着同步一直增长,当索引超出数组范围时,将直接置零,出栈和入栈的操作大致相同,就不细谈了
下面代码中是 poll 的例子,在 ArrayDeque 里,数组容量为 2 的指数倍,elements.length - 1 正好构成 低位掩码
head = (h + 1) & (elements.length - 1);
在入队时,在队列不为空的情况下,发现 head 和 tail 相等,就代表数组已满,此时需对数组进行扩容,ArrayDeque 默认容量为 8,每次扩容 2 倍
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
现在看来,如果我们不需要索引元素,只需要队列功能的话,基于数组的 ArrayDeque 应该是最好的选择,因为占用内存往往要少于基于链表的 LinkedList
PriorityQueue
PriorityQueue 作为一种 优先队列,内部依靠维护一个 堆化数组,来保持出队的优先级,优先级由 Comparator 决定,若未指定比较器,默认采用队列元素 Conparable 升序排列
public class PriorityQueue extends AbstractQueue
implements java.io.Serializable {
/**
* Priority queue represented as a balanced binary heap: the two
* children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The
* priority queue is ordered by comparator, or by the elements'
* natural ordering, if comparator is null: For each node n in the
* heap and each descendant d of n, n <= d. The element with the
* lowest value is in queue[0], assuming the queue is nonempty.
*/
transient Object[] queue; // non-private to simplify nested class access
/**
* The comparator, or null if priority queue uses elements'
* natural ordering.
*/
private final Comparator comparator;
// ...
}
内部数组扩容时,在数组较小时,扩容 2 倍,数组较大时,扩容 1.5 倍,阈值取值为 64,之所以采取如此策略,可能是因为减少容量大时扩容对堆维护损带来的性能损耗
/**
* Increases the capacity of the array.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
// ...
}
出入队时,将当前元素与相关上下层进行元素交换来维护堆的性质,构建最大堆或最小堆,可以说和排序算法 - 堆排 [3] 完全一样
/**
* Establishes the heap invariant (described above) in the entire tree,
* assuming nothing about the order of the elements prior to the call.
*/
private void heapify() {...}
/**
* Inserts item x at position k, maintaining heap invariant by
* promoting x up the tree until it is greater than or equal to
* its parent, or is the root.
*
* To simplify and speed up coercions and comparisons. the
* Comparable and Comparator versions are separated into different
* methods that are otherwise identical. (Similarly for siftDown.)
*
* @param k the position to fill
* @param x the item to insert
*/
private void siftUp(int k, E x) {...}
/**
* Inserts item x at position k, maintaining heap invariant by
* demoting x down the tree repeatedly until it is less than or
* equal to its children or is a leaf.
*
* @param k the position to fill
* @param x the item to insert
*/
private void siftDown(int k, E x) {...}
参考
1. Jdk 源码 1.8
2. Jdk 官方文档
-
详解快速排序及其优化 ↩
-
归并排序及其优化 ↩
-
堆排序详解 ↩