文章也同时在个人博客 http://kimihe.com/更新
引言
本文主要针对iOS内存管理进行总结,相信看过之后一定会让你有所收获。对于内存管理,网上有很多这方面的文章,但论质量可谓良莠不齐。其中的很多总结已经过时,甚至有些内容是似懂非懂的误读。因此,本文立足严谨的治学态度,希望能够尽可能全面地让大家理解内存管理的要点。
本文涵盖的知识点比较多,大家可以根据需要择章节阅读(部分章节待更),下面是目录:
- 基础知识
- 引用计数
- ARC
- delloc方法
- 循环引用
- 自动释放池@autoreleasepool
- 关于retainCount
基础知识
在理解内存管理之前,你需要理解内存的到底如何被我们的操作系统使用的,需要有一个清晰的内存模型。
对于内存的使用模型,大家应该不陌生堆栈这次词。但具体的内部原理其实还是比较复杂的。大家谷歌或者百度一下,可以搜到如下这张内存堆栈图:
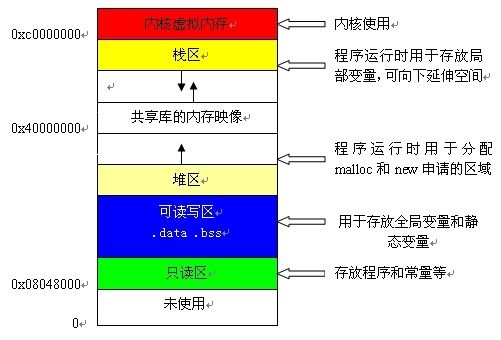
这张图的信息量还是比较大的,请大家耐心阅读笔者的讲解。
首先常说的堆栈一词包含了“堆”和“栈”两个概念。它们是有区别的,而且和数据结构中的堆栈是不同的。“堆”和“栈”分别代表了两种数据管理方式,前者有程序员自己控制,后者由操作系统(由编译器在编译时确定套路)控制。这句话是网上很多文章常说的,但可能并没有说明白其中的本质。如果你想更加清楚地了解堆栈在内存中的底层细节,可以参考一下笔者的这篇文章《内存中的堆和栈到底是什么》。
在明白了上述细节后,大家请看如下代码:
NSString *someString = @"Some String";
NSString *anotherString = someString;
对于上述代码,我们表明上看起来似乎创建了两个NSString对象,其实它们二者是复用的关系。要理解这一点,你可能需要明白什么是指针。可以看笔者的这篇文章《快速入门Linux下GDB和汇编开发工具》中介绍指针原理的部分。
如果你清楚指针的含义,请继续往后看。实际上,上述代码只创建了一个NSString对象,它分配在堆中,需要进行内存管理。注意,我们并不是说这个字符串常量在堆上,而是创建一个OC对象需要的内存开销是在堆上,普通的字符串常量存在数据段的.rodata区。笔者强烈建议先阅读一下介绍内存堆栈的那篇文章。
而someString和anotherString是两个指针(请注意它们C语言风格的*号),它们存在于栈中,跟随栈的管理由系统控制,我们人工无需也最好不要去控制。具体看来,我们在当前代码区域的栈中分配了两个内存,但这两个内存只是用来存放指针,与堆中用来存储字符串实例是完全不同的。这两个内存的大小刚好能够分别存下一个指针(在32位CPU上是4字节,在64位上是8字节),而且两个内存中的值是一样的,即两个指针的值是一样的,于是两个指针指向同一个堆内存区域,从而导致someString和anotherString这两个指针指向的是相同的字符串实例。如下图:
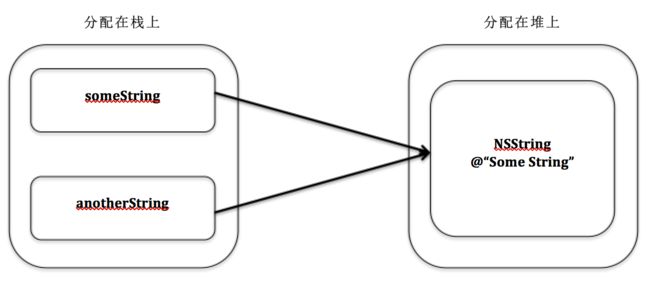
总结一下: someString和 anotherString分配在栈上,无需我们控制。 NSString: @"Some String"分配在堆上,需要我们进行内存管理。而这里的内存管理你需要理解引用计数,请看下一小节。
除此之外,OC虽然是一门面向对象语言,但本质上它是一个C的超级。很多理念和C是通用的,如果你熟悉C,学习OC将很快。注意到上述指针的*号,OC中的对象都是以指针来引用的,因此对象类型的实例的名字前都会带有一个*号。
对于普通的非对象类型的变量,比如CGRect结构,它们也会使用栈空间,而非对象类型所用的堆空间。因此,相比于创建结构体创建对象需要分配和释放内存等额外开销,所以若需要存储int,float,double,char,bool等非对象类型,建议直接使用结构体。
建议花一点时间学习一下C,这将有助于OC的学习。
其余章节待更~
自动释放池@autoreleasepool
OC对象的生命周期取决于引用计数,我们有两种方式可以释放对象:一种是直接调用release释放;另一种是调用autorelease将对象加入自动释放池中。自动释放池用于存放那些需要在稍后某个时刻释放的对象。
自动释放池的创建
如果没有自动释放池而给对象发送autorelease消息,将会收到控制台报错。但一般我们无需担心自动释放池的创建问题。
我们的Mac以及iOS系统会自动创建一些线程,例如主线程和GCD中的线程,都默认拥有自动释放池。每次执行 “事件循环”(event loop)时,就会将其清空,这一点非常重要,请务必牢记! 关于事件循环,其涉及到runloop,可以看这篇文章:深入理解RunLoop。
因此我们一般不需要手动创建自动释放池,通常只有一个地方需要它,那就是在main()函数里,如下:
int main(int argc, char * argv[]) {
@autoreleasepool {
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
这个main()函数里面的池并非必需。因为块的末尾是应用程序的终止处,即便没有这个自动释放池,也会由操作系统来释放。但是这些由UIApplicationMain函数所自动释放的对象就没有池可以容纳了,系统会发出警告。因此,这里的池可以理解成最外围捕捉全部自动释放对象所用的池。
@autoreleasepool的作用
大家可以先看一下下面的iOS笔试题的第5题(修改代码的错误),如下图:

这段代码问题在哪里呢?题目的解答请继续阅读。笔者先给一个提示:与内存的释放有关。
现考虑如下代码:
for (int i = 0; i < 10000; i++) {
[self doSthWith:object];
}
这段代码和笔试题关键部分大同小异。如果"doSthWith:"方法要创建一个临时对象,那么这个对象很可能会放在自动释放池里。笔试题中最后stringByAppendingString方法很有可能属于上述的方法。因此如果涉及到了自动释放池,那么问题也应该就出在上面。
注意:即便临时对象在调用完方法后就不再使用了,它们也依然处于存活状态,因为目前它们都在自动释放池里,等待系统稍后进行回收。但自动释放池却要等到该线程执行下一次事件循环时才会清空,这就意味着在执行for循环时,会有持续不断的新的临时对象被创建出来,并加入自动释放池。要等到结束for循环才会释放。在for循环中内存用量会持续上涨,而等到结束循环后,内存用量又会突然下降。
而如果把循环内的代码包裹在“自动释放池”中,那么在循环中自动释放的对象就会放在这个池,而不是在线程的主池里面。如下:
for (int i = 0; i < 1000000; i++) {
@autoreleasepool {
NSString *str = @"abc";
str = [str lowercaseString];
str = [str stringByAppendingString:@"xyz"];
}
}
新增的自动释放池可以减少内存用量,因为系统会在块的末尾把这些对象回收掉。而上述这些临时对象,正在回收之列。
自动释放池的机制就像“栈”。系统创建好池之后,将其压入栈中,而清空自动释放池相当于将池从栈中弹出。在对象上执行自动释放操作,就等于将其放入位于栈顶的那个池。
实验验证
我们可以通过实验进行验证。新建工程加入上述代码,并关闭ARC(不然是看不到区别的)。
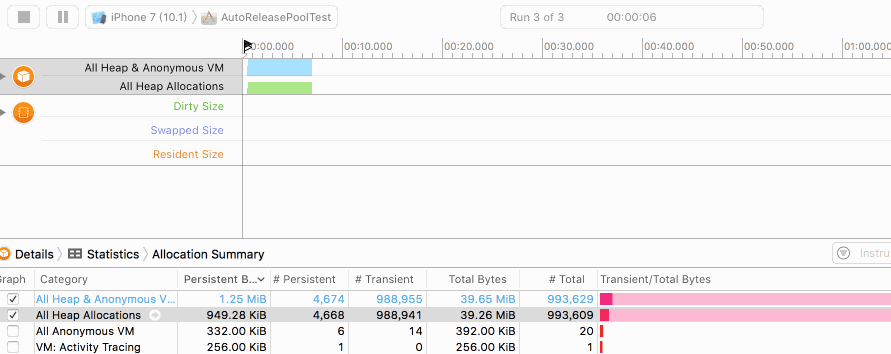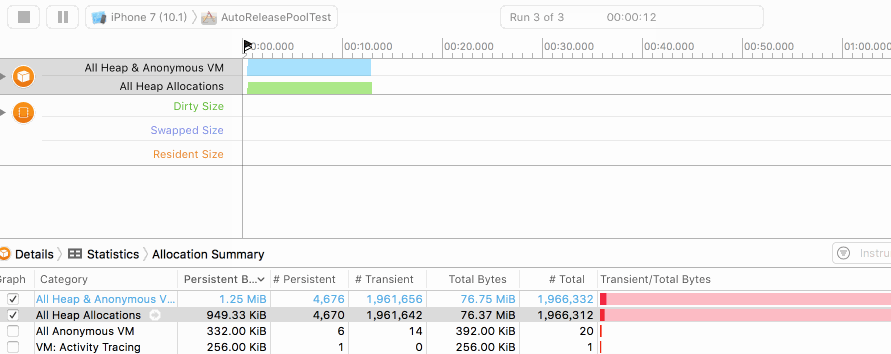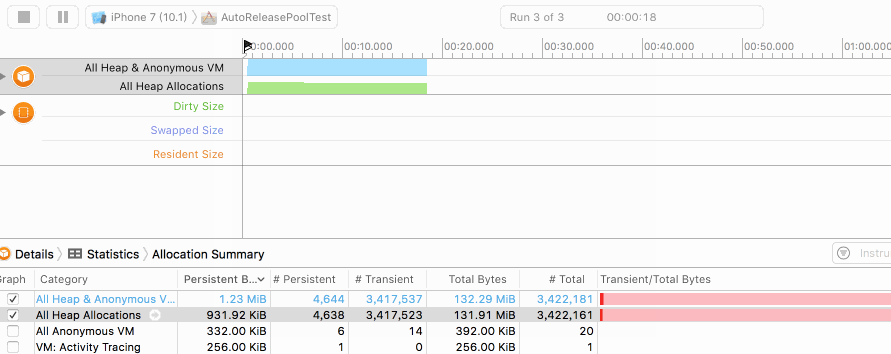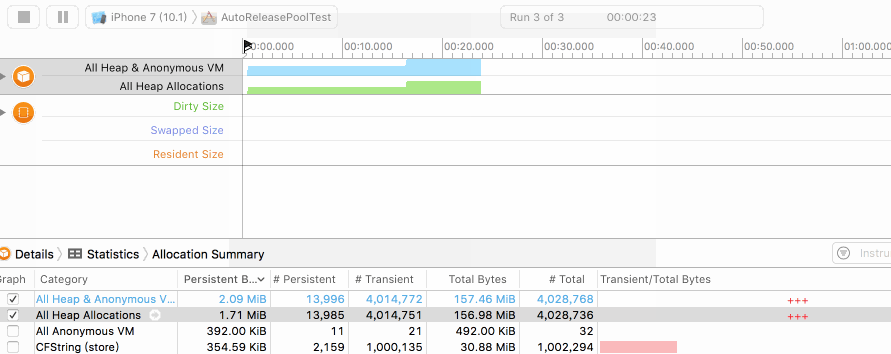
在未添加autoreleasepool时,我们的堆内存实时分配情况如下图:
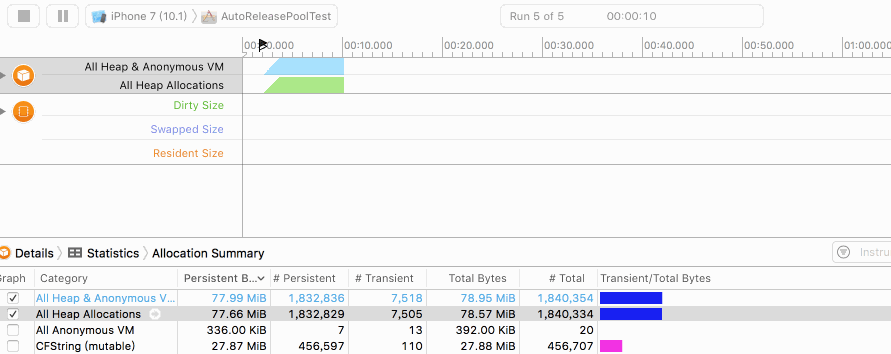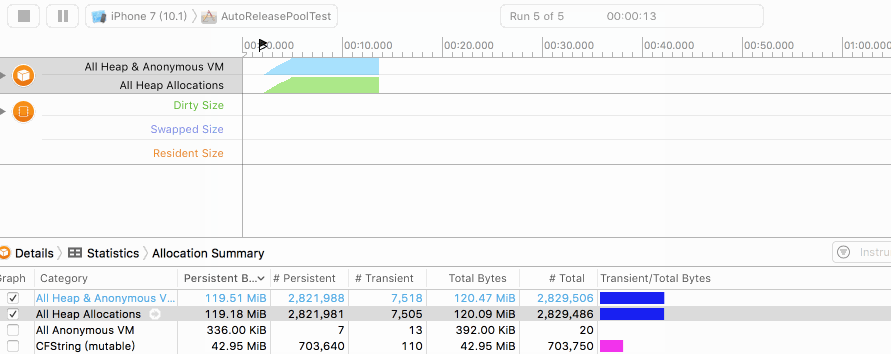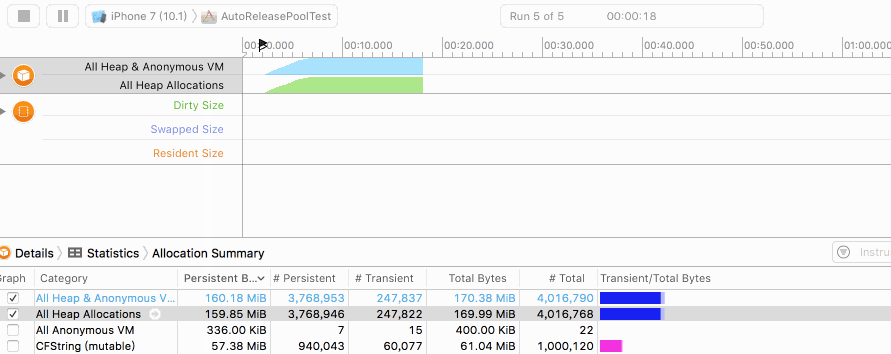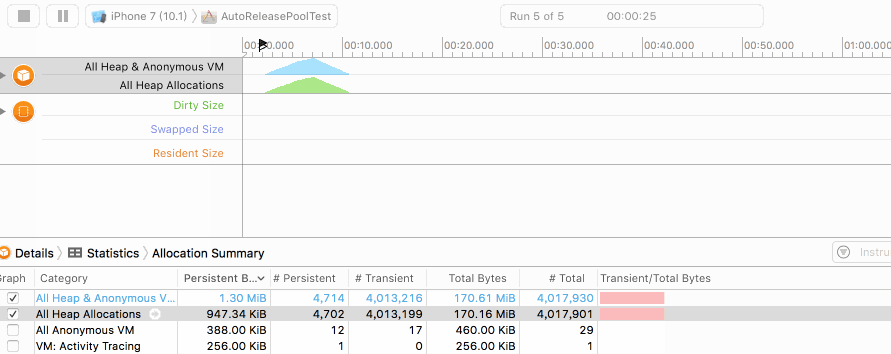
大家可以看到Persistent Bytes不断增加,到达100W次的创建峰值后(出for循环)开始逐步释放。因此图像是一个向上凸的曲线。
而在加入autoreleasepool后,我们看到如下的曲线:
可以发现尽管字符串在不断地创建,但由于得到了及时的释放,堆内存始终保持在一个很低的水平。
其他注意点
@autoreleasepool语法还有一个好处,就是可以避免无意间误用那些在清空池之后已被系统回收的对象,例如:
@autoreleasepool {
id obj = [self createObject];
}
[self useObject:obj];
上述代码在编译时就会基于错误警告,因为obj出了自动释放池就不可用了。
@autoreleasepool小结
- 自动释放池排布在栈中,对象受到autorelease消息后,系统将其放入栈顶的池里。
- 合理运用自动释放池,可以降低程序的内存峰值。
关于retainCount
大家在搜索引擎中输入“retainCount”,可以看到非常多的文章讲述retainCount的作用。
大多数文章都在强调这个retainCount是用来标记对象,进行内存管理的。所谓“reatin +1;release -1;到0释放;打印retainCount查看当前计数”等等。但其实retainCount并不应该像上述那样使用,OC的引用计数也不是那样理解的。
误区一
retainCount似乎可以返回某对象的保留计数,其实即便在MRC下,retainCount在实际编程过程中也并没有什么用。首要原因在于:它返回的保留计数只是某个时间点上的值。该方法并未考虑到系统会稍后把自动释放池清空,因而没有将后续的释放操作从返回值里减去。
如果你想根据这个数值来进行某些释放操作,那就很糟糕了。例如:
while ([object retainCount]) {
[object release];
}
其中存在两个错误,第一个就是没有考虑到自动释放操作,只是不停地release,直到对象被系统回收。假如此对象在自动释放池里,那么稍后系统在清理空池子时还要仔把它释放一次,这将导致程序崩溃。
第二个错误就是:retainCount可能永远也不会减少到0。因为有时候系统会优化对象的释放行为,在保留计数还是1的时候就把它回收了。只有在系统不打算这么优化时,计数值才会递减址0。所以靠上述条件进行判断,完全是在赌运气。
我们真正应该做的是确保release和retain操作的匹配(即可以相互抵消),我们在期望系统回收某对象时,应该确保没有尚未抵消的保留操作,也就是不要让保留计数大于我们的期望值。如果发现内存泄漏了,那么应该检查还有社仍然保留这个对象,并查明为何没有释放。
虽然Apple建议大家使用ARC,实际也确实如此。但基于MRC的开发也并非一无是处,至少它能够让我们更加清晰地理解内存管理的真谛。
误区二
如果我们打印一些字符串或者数值对象的retainCount,如下代码:
NSString *string = @"Apple";
NSLog(@"string retainCount: %lu", (unsigned long)[string retainCount]);
NSNumber *numberI = @1;
NSLog(@"numberI retainCount: %lu", (unsigned long)[numberI retainCount]);
NSNumber *numberF = @3.14f;
NSLog(@"numberF retainCount: %lu", (unsigned long)[numberF retainCount]);
其输出将会如下:
2016-12-04 20:04:51.007 tmp[1522:138528] string retainCount: 18446744073709551615
2016-12-04 20:04:51.008 tmp[1522:138528] numberI retainCount: 9223372036854775807
2016-12-04 20:04:51.008 tmp[1522:138528] numberF retainCount: 1
我们发现结果非常奇怪。怎么回事呢?
第一个string的保留计数其实为2的64次方-1,而第二个numberI是2的63次方-1。二者皆为“单例对象”(singleton object),所以保留计数都很大。
系统会尽可能地把NSString实现成单例对象。像上述代码中的字符串,其实是一个编译期常量,编译器会把NSString对象所表示的数据放到应用程序的二进制文件里,这样的话,运行程序时就能直接用了。这一点对应到底层的话,隶属于程序的可执行文件中数据段的.rodata小段的作用,如果你阅读过开头笔者提到的《内存中的堆和栈到底是什么》这篇文章,应该可以很容易理解。
NSNumber也类似,它使用了一种叫做“标签指针”(tagged pointer)的概念来标注特定类型的数值。关于tagged pointer,可以阅读这篇唐巧的文章:深入理解Tagged Pointer。
tagged pointer不使用NSNumber对象,而是把数值有关的全部消息都放在指针值里面。运行期系统会在消息派发期间检测到这种标签指针,并对它执行相应操作,使其行为看上去和真正的NSNumber对象一样。这种优化只在某些场合使用,比如上述代码中的浮点数对象就没有优化,所以保留计数就是1。
上述的这种单例对象,其保留计数绝对不会变。这种对象的保留及释放操作都是“空操作”(noop)。
retainCount小结
对象的保留计数看似有用,其实最好根本不要去使用。因为任何给定时间点上的“绝对保留计数”(absolute retain count)都无法反应对象生命期的全貌。