- new Thread的弊端
- 线程池
- 线程池的优势
- Executors
- ExecutorService
- ThreadPoolExecutor
- CachedThreadPool
- FixedThreadPool
- ScheduledThreadPool
- SingleThreadExecuter
- ForkJoinPool
- 参考文章
1. new Thread的弊端
- 每次都使用new Thread()性能很差。
- 线程缺乏统一管理。如线程数的管理。
2. 线程池
一种线程使用模式。线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。
一般来说,对于有N个CPU的主机(或N个核心),线程池大小应如下设置:
- 如果是CPU密集型应用,线程池大小为N+1。
- 如果是IO密集型应用,线程池大小为2N+1。
3. 线程池的优势
- 重用存在的线程,省去线程的创建销毁过程,性能佳。
- 有效控制最大并发线程数。提高了使用率并避免了竞争。
- 定时执行,定期执行,单线程,并发控制等功能。
4. Executors
Java通过Executors类提供四种线程池。创建方法为静态方式创建。
4.1. ExecutorService
继承了Executor类,在其基础上进行具体的扩展。
4.2. ThreadPoolExecutor
ThreadPoolExecutor是ExecutorService类的子树上的类,是ExecutorService类提供的四个主要线程池方法的实现类,其完整构造器包括以下参数:
- corePoolSize:线程池中核心线程数的最大数值。核心线程:线程池新建线程的时候,如果当前线程总数小于corePoolSize,则新建的是核心线程,如果超过corePoolSize,则新建的是非核心线程。核心线程默认情况下会一直存活在线程池中,即使这个核心线程闲置。如果指定ThreadPoolExecutor的allowCoreThreadTimeOut这个属性为true,那么核心线程如果不干活(闲置状态)的话,超过一定时间(时长下面参数决定),就会被销毁掉。
- maximumPoolSize:池中允许的最大线程总数。县城总数=核心线程+非核心线程。非核心线程在闲置时会被销毁。
- keepAliveTime:非核心线程闲置超时时长,若allowCoreThreadTimeOut这个属性为true,核心线程也会被影响。
- unit:keepAliveTime参数的时间单位。
- workQueue:执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务,可在Java容器:Stack,Queue,PriorityQueue和BlockingQueue一文中查询。
- threadFactory:执行程序创建新线程时使用的工厂,可用于定义创建现成的方式,一般无用。
- handler:由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序,存在默认方案。
(继承关系Executor-ExecutorService-AbstractExecutorService-ThreadPoolExecutor)
而接下来介绍的几种方法,其实即是预定义的ThreadPoolExecutor。
4.3. CachedThreadPool
创建一个可缓存线程池,线程池长度超过处理需要时,可灵活回收空闲线程,若无可回收线程则新建线程。
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
try {
Thread.sleep(index * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(index);
}
});
}
其实现代码如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
可见,该方法中所有线程均由SynchronousQueue管理,且不设置线程数量上限。对于SynchronousQueue,每个插入线程必须等待另一线程的对应移除操作。(即该队列没有容量,仅试图取得元素时元素才存在)因而,该方法实现了,如果有线程空闲,则使用空闲线程进行操作,否则就会创建新线程。
4.4. FixedThreadPool
创建一个定长线程池,可以控制最大并发数,超出的线程会在队列中等待。
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
final int index = i;
fixedThreadPool.execute(new Runnable() {
@Override
public void run() {
try {
System.out.println(index);
Thread.sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
});
}
其实现代码如下:
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory);
}
可见该方法让keepAliveTime为0,即限制了线程数必须小于等于corePoolSize。而多出的线程则会被无界队列所存储,在其中排队。
4.5. ScheduledThreadPool
创建一个定长线程池,相对于FixedThreadPool,它支持周期性执行和延期执行。
延期3秒执行
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
scheduledThreadPool.schedule(new Runnable() {
@Override
public void run() {
System.out.println("delay 3 seconds");
}
}, 3, TimeUnit.SECONDS);
每三秒隔一秒执行
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("delay 1 seconds, and excute every 3 seconds");
}
}, 1, 3, TimeUnit.SECONDS);
和FixedThreadPool的最大不同是,它采用一个DelayedWorkQueue去控制线程,该队列仅有到期时才能取出元素。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
4.6. SingleThreadExecuter
创建一个单线程线程池,只会用唯一的工作线程执行任务,保证所有任务按FIFO,LIFO的优先级执行。
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
singleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
try {
System.out.println(index);
Thread.sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
});
}
在实现上,其相当于一个线程数为1的FixedThreadPool
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
4.7. ForkJoinPool
ForkJoinPool是JDK7中引用的特殊的新的线程池,其核心思想类似于MapReduce,将大任务拆分成多个小任务(fork),再将多个小任务汇集到结果上(join),同时,他通过继承了AbstractExecutorService获得了基础的线程池功能,可以像普通线程池一样配置。其工作模式如图:
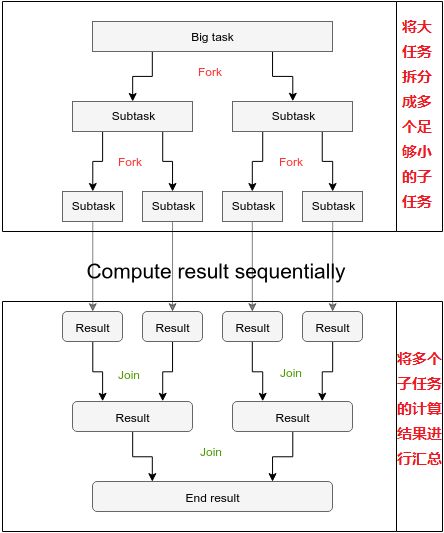
普通的线程池中每个任务都由单独的线程处理,如果出现一个耗时比较大的任务,可能出现线程池中只有一个线程在进行这个任务,其他线程却空闲着,所谓“一核有难,八核围观”,造成了CPU负载不均衡。ForkJoinPool为解决这种问题提出,在ForkJoinPool中,引入了工作窃取算法,其核心思想为:
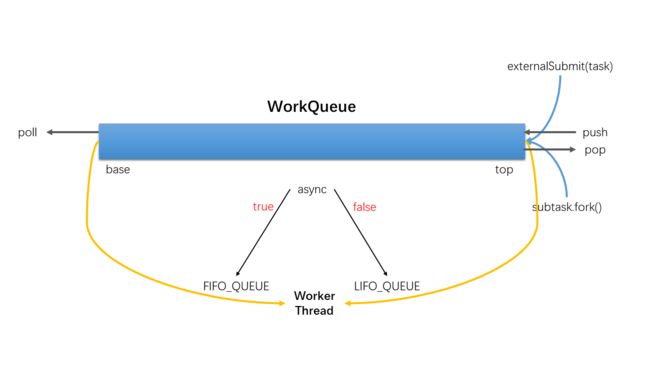
- 每个线程有自己的工作队列(WorkQueue),该队列是一个双向链表(Java的WorkQueue结构中用ArrayList实现)
- 队列所有者线程可以调用双链表的push/pop(取头取尾根据模式决定)方法,其他线程可以调用该队列poll(取尾取头根据模式决定)方法,push/poll/pop均引入CAS,为原子操作。
- 划分的子任务调用fork时,会把任务push到自己的队列中。
- 默认情况,工作线程从自己的队列pop任务并执行。
- 自己队列为空,线程随机从另一线程poll任务并执行。
队列结构
/**
* Queues supporting work-stealing as well as external task
* submission. See above for descriptions and algorithms.
*/
public class WorkQueue {
volatile int source; // source queue id, or sentinel
int id; // pool index, mode, tag
int base; // index of next slot for poll
int top; // index of next slot for push
volatile int phase; // versioned, negative: queued, 1: locked
int stackPred; // pool stack (ctl) predecessor link
int nsteals; // number of steals
ForkJoinTask[] array; // the queued tasks; power of 2 size
final ForkJoinPool pool; // the containing pool (may be null)
final ForkJoinWorkerThread owner; // owning thread or null if shared
//......
}
Java8中在Executors里也加入了新增ForkJoinPool的方法,让它像普通线程池一样工作,创建的ForJoinPool任务是FIFO的。
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
该方法也可以带参数,决定parallelism。
此外,还可以使用ForkJoinPool内部已经初始化好的commonPool:
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
当然,你可以直接调用构造方法来创建ForkJoinPool,其完整参数如下,解释见注释。
public ForkJoinPool(int parallelism,//并行化层数,默认为可用CPU处理器数。
ForkJoinWorkerThreadFactory factory,//threadFactory,前文提过,无视。
UncaughtExceptionHandler handler,//handler,前文提过,无视。
boolean asyncMode,//控制workQueue工作模式,若为true,则任务FIFO从base取任务,默认为false,任务LIFO,从top取任务。
int corePoolSize,//核心线程数,通常和parallelism数量一致。设置较大可以降低动态开销,如果任务中经常有阻塞,建议设置为小值,比如默认值0。
int maximumPoolSize,//最大线程数
int minimumRunnable,//允许的最小的不被join操作阻塞的线程数。默认值为1。
Predicate saturate,//若不为空则可能创建超过最大线程数的线程数。
long keepAliveTime,//非核心线程闲置时长。
TimeUnit unit)//keepAliveTime的单位。
由于构造器重载,多个参数可缺省。
根据工作模式不同,WorkQueue取元素模型如下:
当不把ForkJoinPool作为简单线程池使用时,使用ForkJoinPool,需要构建ForkJoinTask对象到ForJoinPool中,ForkJoinTask有三个核心方法:
- fork():用于任务分治,调用子任务fork()可以将任务放到线程池异步调用。
- join():调用子任务的join()方法等待返回的结果,不受中断机制影响。join()会抛出异常,若不需要可以使用quietlyJoin()并用getExecption()或getRawResult()自己处理异常和结果。
- invoke():在当前线程同步执行该任务,该方法不受中断机制影响。
ForkJoinTask实现了Future接口,内部维护四个状态并提供查询API
- isCancelled() => CANCELLED
- isCompletedAbnormally => status < NORMAL => CANCELLED || EXCEPTIONAL
- isCompletedNormally => NORMAL
- isDone() => status<0 => NORMAL || CANCELLED || EXCEPTIONAL
通常情况我们使用ForkJoinTask的两个子类
- RecursiveAction:没有返回值的任务
- RecursiveTask:有返回值的任务
两个例子,转载自ForkJoinPool入门篇
使用RecursiveAction
public class RecursiveActionTest {
static class Sorter extends RecursiveAction {
public static void sort(long[] array) {
ForkJoinPool.commonPool().invoke(new Sorter(array, 0, array.length));
}
private final long[] array;
private final int lo, hi;
private Sorter(long[] array, int lo, int hi) {
this.array = array;
this.lo = lo;
this.hi = hi;
}
private static final int THRESHOLD = 1000;
protected void compute() {
// 数组长度小于1000直接排序
if (hi - lo < THRESHOLD)
Arrays.sort(array, lo, hi);
else {
int mid = (lo + hi) >>> 1;
// 数组长度大于1000,将数组平分为两份
// 由两个子任务进行排序
Sorter left = new Sorter(array, lo, mid);
Sorter right = new Sorter(array, mid, hi);
invokeAll(left, right);
// 排序完成后合并排序结果
merge(lo, mid, hi);
}
}
private void merge(int lo, int mid, int hi) {
long[] buf = Arrays.copyOfRange(array, lo, mid);
for (int i = 0, j = lo, k = mid; i < buf.length; j++) {
if (k == hi || buf[i] < array[k]) {
array[j] = buf[i++];
} else {
array[j] = array[k++];
}
}
}
}
public static void main(String[] args) {
long[] array = new Random().longs(100_0000).toArray();
Sorter.sort(array);
System.out.println(Arrays.toString(array));
}
}
使用RecurisiveTask
public class RecursiveTaskTest {
static class Sum extends RecursiveTask {
public static long sum(int[] array) {
return ForkJoinPool.commonPool().invoke(new Sum(array, 0, array.length));
}
private final int[] array;
private final int lo, hi;
private Sum(int[] array, int lo, int hi) {
this.array = array;
this.lo = lo;
this.hi = hi;
}
private static final int THRESHOLD = 600;
@Override
protected Long compute() {
if (hi - lo < THRESHOLD) {
return sumSequentially();
} else {
int middle = (lo + hi) >>> 1;
Sum left = new Sum(array, lo, middle);
Sum right = new Sum(array, middle, hi);
right.fork();
long leftAns = left.compute();
long rightAns = right.join();
// 注意subTask2.fork要在subTask1.compute之前
// 因为这里的subTask1.compute实际上是同步计算的
return leftAns + rightAns;
}
}
private long sumSequentially() {
long sum = 0;
for (int i = lo; i < hi; i++) {
sum += array[i];
}
return sum;
}
}
public static void main(String[] args) {
int[] array = IntStream.rangeClosed(1, 100_0000).toArray();
Long sum = Sum.sum(array);
System.out.println(sum);
}
}
5. 参考文章
Java(Android)线程池
Java线程池使用说明
线程池,这一篇或许就够了
ForkJoinPool入门篇