一、 基本介绍
java.util.Map接口,查看定义源码为:
package java.util;
public interface Map {
……
}
HashMap、TreeMap、Hashtable、LinkedHashMap 都是实现Map接口,均为键值对形式,且map的key不允许重复
二、 详细介绍
1. HashMap
HashMap类,我在之前的文章“Java面试 HashMap、HashSet源码解析”中进行过详细的说明,想要详细了解的可以跳转过去看一下。
HashMap是最常用的Map类,根据键的Hash值计算存储位置,存储键值对,可以根据键获取对应值。具有很快的访问速度,但是是无序的、线程不安全的。且HashMap不同步,如果需要线程同步,则需要使用ConcurrentHashMap,也可以使用Collections.synchronizedMap(HashMap map)方法让HashMap具有同步的能力。其实是否同步,就看有没有synchronized关键字。 HashMap的key有且只能允许一个null。
注:线程不安全(多个线程访问同一个对象或实现进行更新操作时,造成数据混乱)
2. Hashtable
Hashtable继承自Dictionary类 ,它也是无序的,但是Hashtable是线程安全的,同步的,即任一时刻只有一个线程能写Hashtable
由此我们比较一下HashMap和Hashtable的运行效率
测试插入效率如下:
long runCount=1000000;
Map hashMap = new HashMap();
Date dateBegin = new Date();
for (int i = 0; i < runCount; i++) {
hashMap.put(i, i);
}
Date dateEnd = new Date();
System.out.println("HashMap插入用时为:" + (dateEnd.getTime() - dateBegin.getTime()));
Map hashtable = new Hashtable();
Date dateBegin1 = new Date();
for (int i = 0; i < runCount; i++) {
hashtable.put(i, i);
}
Date dateEnd1 = new Date();
System.out.println("Hashtable插入用时为:" + (dateEnd1.getTime() - dateBegin1.getTime()));
运行结果为:
HashMap插入用时为:223
Hashtable插入用时为:674
如果我们将运行次数提高到20000000次,则运行时间分别为:
HashMap插入用时为:36779
Hashtable插入用时为:22632
由此可见,在数据量较小时,HashMap效率较高,但是当数据量增大,HashMap需要进行更多次的resize,这个操作会极大的降低HashMap的运行效率,因此在数据量大之后,Hashtable的运行效率更高。
而反过来重新测试读取效率,代码如下:
long runCount=1000000;
Map hashMap = new HashMap();
for (int i = 0; i < runCount; i++) {
hashMap.put(i, i);
}
Date dateBegin = new Date();
for (Integer key : hashMap.keySet()) {
hashMap.get(key);
}
Date dateEnd = new Date();
System.out.println("HashMap读取用时为:" + (dateEnd.getTime() - dateBegin.getTime()));
Map hashtable = new Hashtable();
for (int i = 0; i < runCount; i++) {
hashtable.put(i, i);
}
Date dateBegin1 = new Date();
for (Integer key : hashtable.keySet()) {
hashtable.get(key);
}
Date dateEnd1 = new Date();
System.out.println("Hashtable读取用时为:" + (dateEnd1.getTime() - dateBegin1.getTime()));
运行结果为:
HashMap读取用时为:54
Hashtable读取用时为:65
如果将数量增加到20000000,则运行结果为:
HashMap读取用时为:336
Hashtable读取用时为:526
由此可见,HashMap的读取效率更高。
3. LinkedHashMap
LinkedHashMap是Map中常用的有序的两种实现之一, 它保存了记录的插入顺序,先进先出。
对于LinkedHashMap而言,它继承与HashMap,底层使用哈希表与双向链表来保存所有元素。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了数组中保存的元素Entry,该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表,效果图如下:
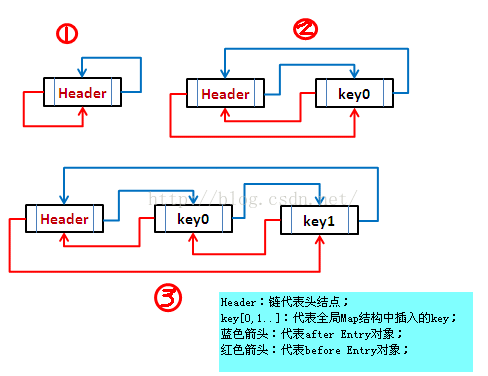
示例代码如下:
Map linkedHashMap = new LinkedHashMap();
linkedHashMap.put(1, 2);
linkedHashMap.put(3, 4);
linkedHashMap.put(5, 6);
linkedHashMap.put(7, 8);
linkedHashMap.put(9, 0);
System.out.println("linkedHashMap的值为:" + linkedHashMap);
输出结果为:
linkedHashMap的值为:{1=2, 3=4, 5=6, 7=8, 9=0}
注:LinkedHashMap在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会 比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关
4. TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
TreeMap的排序原理是:红黑树算法的实现 ,具体概念参考:点击打开链接 。
它的主要实现是Comparator架构,通过比较的方式,进行一个排序,以下是TreeMap的源码,
比较的源码为:
/**
* Compares two keys using the correct comparison method for this TreeMap.
*/
@SuppressWarnings("unchecked")
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable)k1).compareTo((K)k2)
: comparator.compare((K)k1, (K)k2);
}
我们也可以自定义Comparator, 对TreeMap数据的排序规则进行修改,这点是LinkedHashMap不能实现的
具体代码如下:
Map treeMap = new TreeMap();
treeMap.put("aa", 888);
treeMap.put("ee", 55);
treeMap.put("dd", 777);
treeMap.put("cc", 88);
treeMap.put("bb", 999);
System.out.println("使用默认排序规则,生成的结果为:" + treeMap);
Map treeMap2 = new TreeMap(new Comparator() {
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
treeMap2.put("aa", 888);
treeMap2.put("ee", 55);
treeMap2.put("dd", 777);
treeMap2.put("cc", 88);
treeMap2.put("bb", 999);
System.out.println("使用自定义排序规则,生成的结果为:" + treeMap2);
执行结果为:
使用默认排序规则,生成的结果为:{aa=888, bb=999, cc=88, dd=777, ee=55}
使用自定义排序规则,生成的结果为:{ee=55, dd=777, cc=88, bb=999, aa=888}
这边可以查看一下compareTo()的方法源码,内容为:
public int compareTo(String anotherString) {
//先得到比较值的字符串长度
int len1 = value.length;
int len2 = anotherString.value.length;
//得到最小长度
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
//逐个比较字符串中字符大小
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
//如果在两个字符串的最小长度内,字符均相同,则比较长度
return len1 - len2;
}
由此可见,当key值中存储了Integer类型的数字时,将默认无法根据数字大小来进行排序,处理方式如下:
Map treeMap = new TreeMap();
treeMap.put("1", 888);
treeMap.put("9", 55);
treeMap.put("31", 777);
treeMap.put("239", 88);
treeMap.put("177", 999);
System.out.println("使用默认排序规则,生成的结果为:" + treeMap);
Map treeMap2 = new TreeMap(new Comparator() {
public int compare(String o1, String o2) {
//修改比较规则,按照数字大小升序排列
return Integer.parseInt(o1) - Integer.parseInt(o2);
}
});
treeMap2.put("1", 888);
treeMap2.put("9", 55);
treeMap2.put("31", 777);
treeMap2.put("239", 88);
treeMap2.put("177", 999);
System.out.println("使用自定义排序规则,生成的结果为:" + treeMap2);
执行结果为:
使用默认排序规则,生成的结果为:{1=888, 177=999, 239=88, 31=777, 9=55}
使用自定义排序规则,生成的结果为:{1=888, 9=55, 31=777, 177=999, 239=88}
三、 总结
- Map中,HashMap具有超高的访问速度,如果我们只是在Map 中插入、删除和定位元素,而无关线程安全或者同步问题,HashMap 是最好的选择。
- 如果考虑线程安全或者写入速度的话,可以使用HashTable
- 如果想要按照存入数据先入先出的进行读取。 那么使用LinkedHashMap
- 如果需要让Map按照key进行升序或者降序排序,那就用TreeMap
参照
深入浅出 Map 的实现(HashMap、HashTable、LinkedHashMap、TreeMap)