用正则表达式匹配字符串,筛选出所需要的内容,加上简单网络访问代码,实现一个最简单的爬虫。
目标网页:
https://tieba.baidu.com/p/3205263090
实现一个图片批量下载的功能。把这个页面上发表的图表全部下载下来。
虽然拿到这个页面上的图片有多种方式,我们练习的是用Python+正则表达式 来下载图片。
一、获取网页源代码
直接上代码:
import urllib
page = urllib.urlopen('https://tieba.baidu.com/p/3205263090')
print page.read()
运行一下,就是看到控制台上打印出来的网页的代码。
解释一下:urllib是Python提供的基础网络访问模块。urlopen() 创建一个表示远程url的类文件对象,然后可以像本地文件一样,操作这个类文件对象来获取远程数据。
read() 方法是读取这个文件,打印出来就是所要访问网页的源代码。
二、用正则表达式匹配出所需要的图片URL
通过chrome右键检查 -- Elements 查看图片对应的代码:

找到这些图片url的共同特点(页面上还有其他的图片),是src=后面一串字符到 .jpg为止,如果加上列多特征 pic_ext="jpeg",这样可以把跟页面上的其他图片区别出来。
src="([.*\S]*\.jpg)" pic_ext="jpeg"
写出正则表达式,.代表不包括\n的任意字符,*表示有多个字符,\S表示非空字符(防止向后包含空字符匹配了很长的字符串),()表示我们所需要匹配出来的内容。
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgurls = re.findall(reg, html) #匹配出所有url
#遍历
for imgurl in imgurls:
print imgurl
三、保存下载图片
urlretrieve() 方法直接将远程数据下载到本地。
#coding=utf-8
import re
import urllib
# 获取网页源代码的方法
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
html = getHtml('http://tieba.baidu.com/p/3205263090')
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgurls = re.findall(reg, html) #用正则匹配到的图片路径的集合
x = 1
for imgurl in imgurls:
print imgurl # 打印查看一下是不是 每个图片的URL
urllib.urlretrieve(imgurl, '你机器上要保存图片的路径/%s.jpg' % x)
print "正在下载第 %d 张"%x
x +=1
快去看一下下载的图片吧。
- urllib 讲解
- Python: difference between urllib and urllib2
你可能发现图片下载的并不快,有网络原因,也有正则表达式匹配的原因。这段小代码只是一个检验,继续学习吧,后面会有更简单、快速的方式,好用的第三方库requests,xpath可以更快速定位到你需要的内容。
==============
练习问题:
有同学看完上面代码,马上想尝试另一个网站(网页)的图片爬取,这是一个很好的学习思路和方法。我们来看一下,花瓣网
http://huaban.com/pins/1120072731/
- 这个页面上图片很多,你先要确定要抓取哪网页什么地方的图片
当然可以是页面所有图片,也可以是网页下部的瀑布流布局的图片。(实际上以后这一步就是确定,你需要抓取的数据字段) - 找到数据(图片)对应的源代码进行分析,这篇文章的方式就是写一个正则表达式(以后会使用如BeautifulSoup, XPath)
不要“右键 -- 源代码”去搜索找到对应的内容,使用Chrome -- 右键 -- 检查 ,就是定位到 网页元素对应的代码。 - 检查审核
这里要检查,1)图片src对应的是不是一个完整URL(因为可以用相对文件引用的方式),如果不是要补全。2)检查 正则表达式是不是能“准确特征匹配”-- 就是用正则表达式匹配到的都是你所需要的内容。
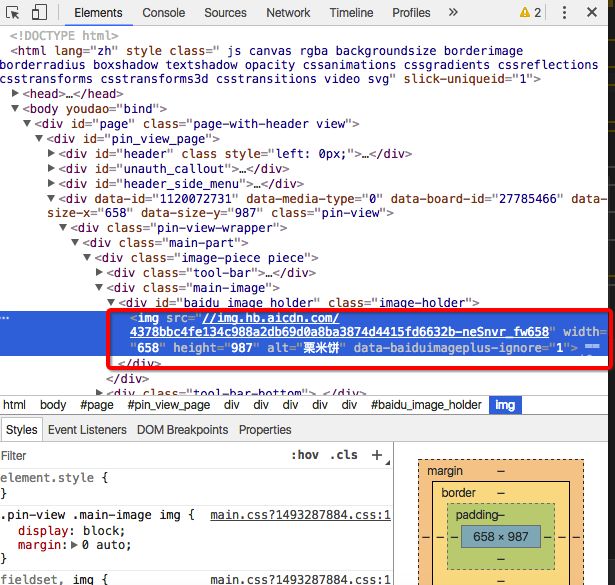
分析和对比几处图片,要想匹配出图片的URL
)
检查一下,这个正则匹配到的页面所有图片URL。想一想如果是某一个区域,某一个类型的图片,正则要怎么写。
总结一下:用正则就是要找到你要数据的共同特征,而且要能与其他数据区别开来。
