- 首先我们知道客户端如果想发送数据,必须要有topic, topic的创建流程可以参考Kafka集群建立过程分析
- 有了topic, 客户端的数据实际上是发送到这个topic的partition, 而partition又有复本的概念,关于partition选主和复本的产生可参考KafkaController分析4-Partition选主和ReplicaManager源码解析2-LeaderAndIsr 请求响应
- 关于Partition的从复本是如何从主拉取数据的,可以参考ReplicaManager源码解析1-消息同步线程管理
- 客户端的ProduceRequest如何被Kafka服务端接收?又是如何处理? 消息是如何同步到复本节点的? 本篇文章都会讲到, 实际上就是综合运用了上面第三点中的内容
- 上一节我们讲到所有的Request最终都会进入到
KafkaApis::handle方法后根据requestId作分流处理,ProduceRequest也不例外;
Topic的Leader和Follower角色的创建
- 之前在ReplicaManager源码解析2-LeaderAndIsr 请求响应中留了个尾巴,现在补上;
- 通过Kafka集群建立过程分析我们知道,Kafkaf集群的Controller角色会监听zk上
/brokers/topics节点的变化,当有新的topic信息被写入后,Controller开始处理新topic的创建工作; - Controller 使用Partition状态机和Replica状态机来选出新topic的各个partiton的主,isr列表等信息;
- Controller 将新topic的元信息通知给集群中所有的broker, 更新每台borker的Metadata cache;
- Controller 将新topic的每个partiton的leader, isr , replica list信息通过LeaderAndIsr Request发送到对应的broker上;
-
ReplicaManager::becomeLeaderOrFollower最终会处理Leader或Follower角色的创建或转换; - Leader角色的创建或转换:
- 停掉partition对应的复本同步线程;
replicaFetcherManager.removeFetcherForPartitions(partitionState.keySet.map(new TopicAndPartition(_))) - 将相应的partition转换成Leader
partition.makeLeader(controllerId, partitionStateInfo, correlationId),其中最重要的是leaderReplica.convertHWToLocalOffsetMetadata(), 在Leader replica上生成新的high watermark;
- 停掉partition对应的复本同步线程;
- Follower角色的创建或转换:
- 将相应的partition转换成Follower
partition.makeFollower(controllerId, partitionStateInfo, correlationId) - 停掉已存在的复本同步线程
replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(new TopicAndPartition(_))) - 截断Log到当前Replica的high watermark
logManager.truncateTo(partitionsToMakeFollower.map(partition => (new TopicAndPartition(partition), partition.getOrCreateReplica().highWatermark.messageOffset)).toMap) - 重新开启当前有效复本的同步线程
replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset), 同步线程会不停发送FetchRequest到Leader来拉取新的消息
- 将相应的partition转换成Follower
客户端消息的写入
- kafka客户端的ProduceRequest只能发送给Topic的某一partition的Leader
- ProduceRequest在Leader broker上的处理 KafkaApis::handleProducerRequest
- 使用
authorizer先判断是否有未验证的RequestInfo
val (authorizedRequestInfo, unauthorizedRequestInfo) = produceRequest.data.partition { case (topicAndPartition, _) => authorize(request.session, Write, new Resource(Topic, topicAndPartition.topic)) } - 如果
RequestInfo都是未验证的,则不会处理请求中的数据
sendResponseCallback(Map.empty) - 否则, 调用
replicaManager来处理消息的写入; - 流程图:
- 使用
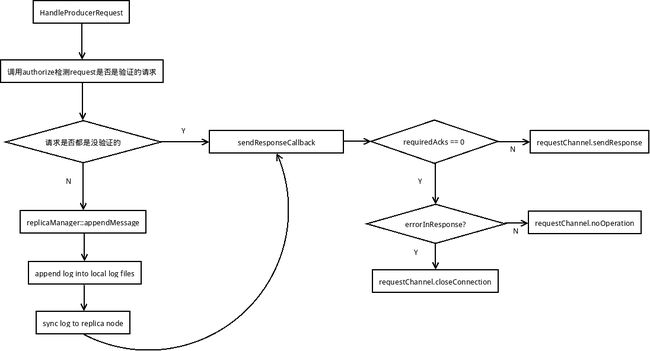
handlerequest.png
-
Leader通过调用
ReplicaManager::appendMessages,将消息写入本地log文件(虽写入了log文件,但只是更新了LogEndOffset, 还并未更新HighWaterMark, 因此consumer此时无法消费到),同时根据客户端所使用的ack策略来等待写入复本;- 等待复本同步的反馈,利用了延迟任务的方式,其具体实现可参考DelayedOperationPurgatory--谜之炼狱,
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback) - 尝试是否可以立即完成上面1中的延迟任务,如果不行才将其加入到 delayedProducePurgatory中,
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys) - 当这个Partition在本地的isr中的replica的LEO都更新到大于等于Leader的LOE时,leader的HighWaterMark会被更新,此地对应的
delayedProduce完成,对发送消息的客户端回response, 表明消息写入成功(这个下一小节后细说); - 如果在
delayedProduce没有正常完成前,其超时了,对发送消息的客户端回response, 表明消息写入失败;
- 等待复本同步的反馈,利用了延迟任务的方式,其具体实现可参考DelayedOperationPurgatory--谜之炼狱,
-
Partition在本地的isr中的replica的LEO如何更新呢?
- 前面说过Follower在成为Follower的同时会开启
ReplicaFetcherThread,通过向Leader发送FetchRequest请求来不断地从Leader来拉取同步最新数据,ReplicaManager::fetchMessage处理FetchRequest请求,从本地log文件中读取需要同步的数据,然后更新本地对应的Replica的LogEndOffset, 同时如果所有isr中的最小的LogEndOffset都已经大于当前Leader的HighWaterMark了, 那么Leader的HighWaterMark就可以更新了, 同时调用ReplicaManager::tryCompleteDelayedProduce(new TopicPartitionOperationKey(topicAndPartition))来完成对客户端发送消息的回应. - 从上面的1中我们看到实际上发送
FetchRequest的replica还未收到Response,这个Leader的HighWaterMark可能已经就更新了;
- 前面说过Follower在成为Follower的同时会开启
-
对于Replica的FetchRequest的回应
- 在
ReplicaManager::fetchMessage, 调用readFromLocalLog从本地log中读取消息后,先判断是否可以立即发送FetchRequest的response:
if(timeout <= 0 || fetchInfo.size <= 0 || bytesReadable >= fetchMinBytes || errorReadingData)
// respond immediately if
// 1) fetch request does not want to wait
// 2) fetch request does not require any data
// 3) has enough data to respond
// 4) some error happens while reading data- 如查不能立即发送, 需要构造
DelayedFetch来延迟发送FetchRequest的response,
这可能是FetchRequset中所请求的Offset, FileSize在当前的Leader上还不能满足,需要等待; 当Replica::appendToLocaLog来处理ProduceRequest请求是会尝试完成此DelayedFetch;
- 在