这天参加完TID离开北京,结果先是航班取消,然后是航班晚点(晚上11:28还没有登机),简直就是悲剧。也许是上天给个时间让我写写我分享了啥,毕竟13:00到13:30这个时间确实尴尬,也许是因为“睡觉”和“吃饭”而错过了精彩内容。下面让我帮你补回来。
回顾1.0

先来说下为什么是2.0,是因为之前在Qcon2015的时候,我分享过手Q专项测试最佳实践,那个算是1.0。在里面我把我们的专项测试建设分成了如图1.1的三个阶段,最开始是为了要有性能基线,我们用UI自动化测试监控核心功能的性能来获取基线,这里的重点是“自动化执行”;第二阶段,我严格控制核心专项自动化测试的用例量,我深信用例多,我们是维护不来的,“UI自动化测试”的坑,但带来的问题是,我们发现性能问题的场景很有限,所以我们就产生了系统测试执行用例,我们监控上报,性能分析云根据规则分析提单的想法,这里的重点是“自动化分析”。第三阶段,我们发现这样的一个分析云还是可以跟monkey结合,这就产生了我们的动态检查(相对静态检查),这里我们的重点是“自动化分析“与”自动化执行“的结合。所到底就是为了效率,而手段就是”自动化“。
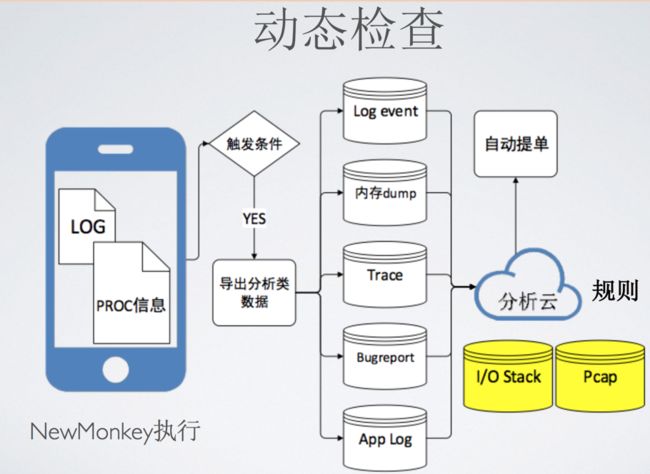
我们当时最后的落脚点是“动态检查”,下面就来稍微介绍下。我们的动态检查依托与NewMonkey来做功能遍历,然后利用SDK采集指标型数据,然后通过指标型数据作为阈值来触发采集分析型数据,这些数据包括如图1.2里面的内存dump等等,最后利用分析云中的规则定义来分析这些数据,进行自动提单。
说到这,大家也许会好奇几个问题:
• 如何让随机测试(NewMonkey)尽可能遍历功能?
• 分析的规则都有什么?如何制定的?
• 乃至缺陷如何去重?最终效果如何?
要知道详情,可以搜索我之前的两个分享,《手Q专项测试最佳实践》和《你从来没有想过的新 Monkey 测试》,里面会有详细的介绍,这里就不多说了。
我们做得如此深入,如此完美,难道我们步伐就停止了么?
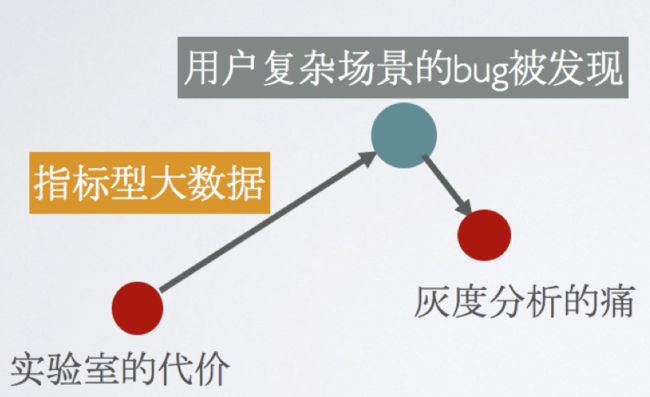
实验室的代价

并没有,因为问题来了。大家记得那些年手Q那个有点鬼畜的口令红包么?那次是完全被坑惨了,我们在研发环境里面模拟,利用后台接口,对前端UI进行压测,发现了一些问题,解决了一些,觉得应该是ok了。但是万万没想到,悲剧发生在我们的年会。那时老板在群里面发口令红包,大家热情高涨,每秒差不多上百的消息量,加上热爱腾讯业务的同学们本身就是各种挂件和气泡的使用者的叠加,作为专项测试的我,在班车的路上就开始听到了此起彼伏的“我卡死了”,“哎呀,打不开”等等等等。之后的几天,为了解决这个问题,每天我都要花300多块来发红包。按照我们案例,我们在研发环境中能不能模拟?
说实话,没有不能模拟的,只是要付出“实验室的代价”而已,模拟群里面的用户发消息不难,模拟发送的消息不同,模拟头像不同,还要群里面的用户都开通各种vip,svip的功能就麻烦了。
这里我们应对“实验室的代价”的解决方案是什么?

当然还是用好用户了,也就是我们的灰度测试,AB测试,大数据。不用模拟了,用户就有这些场景,我们采集对应的场景的指标型数据,才能在灰度阶段发现问题。但是这里有个核心的难点,如何让我们从用户采集上来的性能指标反映用户体验呢?
就先用最简单的FPS为例,用它来评估流畅度就有问题,例如用户掉了6帧,将近100ms,用户是能感受到卡顿的,但是FPS却是54FPS,这是个相当好的分数,在WWDC里面都赞的分数。因此应该用janky,也就是掉帧本身来定制指标,才能反映用户的卡顿。但是说实话,FPS再不靠谱,怎么说还是交互类指标,本身就跟用户体验相关,那资源类指标呢?怎么办?例如内存,占用多少,对用户又能有什么影响呢?
大家可以先想一个问题,内存究竟对用户能有什么影响?
两个影响,一个是crash,一个是卡顿。依据这个我们就可以定制采集的指标了。Crash最简单了,OOM等内存类型的crash在整体crash量的占比就很难说明问题。另外一个是卡顿,我们是思路是这样的,内存导致卡顿,多数是因为GC的stop the world, 而现在android 4.x以上,对于一般的GC已经有不错的优化了,剩余一个跟卡顿相关性最大的GC类型,应该是GC for alloc,而导致GC for alloc的就一个原因,内存不够花了。所以我们制定了一个指标,叫触顶率,以内存占用超过maxMemoryHeap的80%作为触顶的标志,因为我们发现这个时候,GC for alloc特别多。

灰度分析的痛
我们通过指标型大数据,可以帮助我们在灰度发现用户在复杂场景时候的性能问题。能发现当然很好,但是分析定位呢?就杯具了。
下面的两个图片就是跟进用户反馈的真实情况,这样的跟进效率实在是太低了,有没有解法?

关键BUG的纠结
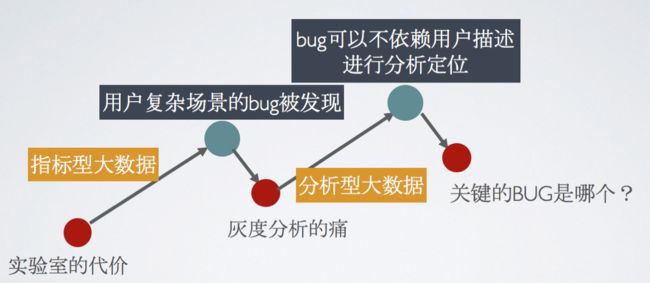
我们通过分析型数据的上报,可以让我们不用去做灰度的分析,也可以利用堆栈,内存快照快速定位我们代码的原因。这个时候,迎来来一批隐藏缺陷,容易改的都改了,但是新的痛又来了。这些bug里面还隐藏了不少难改的,例如跟架构有关,跟需求有关的,加上敏捷下的版本节奏,大家一定会问一个问题,关键的BUG是哪个。要回答这个问题,同样,我们要利用好我们的大数据。

我们利用聚合算法,去聚合用户上报的卡顿堆栈,耗电调用堆栈,内存对象。聚合后我们就可以得到一个排行榜,按照这个排行,解决top的问题。我称之为量化效应的大小。具体举个例子,下图是我们如何聚合卡顿堆栈。
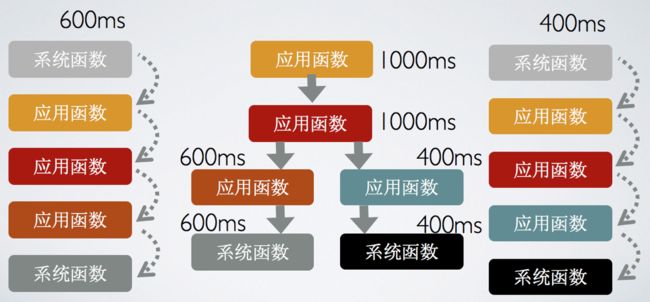
聚合后,会生成N棵树。按照总体耗时排名。
小结
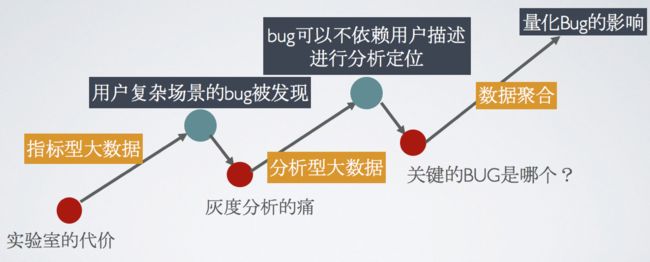
我们通过指标型大数据,分析型大数据,数据聚合,解决了发现,定位,量化三个问题。这里我们不妨换个角度看下,其实我们在干什么?

上面是我话的一个象限图,一条斜线贯穿的是代码经历的四个阶段,前面的阶段,bug的发现很难度量影响,但是解决问题的效率会很高。往后走,一直到发布运营,像SNGAPM(刚刚一直介绍的采集定位性能问题的平台)度量bug的影响会变得非常容易,如前面的卡顿聚合。
而我们一直做的事情,其实是提升这些发布运营阶段发现的BUG的解决效率,希望可以让这些工具下移到“度量易,效率高”的象限,例如获取分析型数据“堆栈”。
但是有点也许大家兴奋地听我巴拉巴拉的时候,已经忘记了一个常识。“风险”,无论后面SNGAPM怎么强大,发现BUG的时机就决定了,解决BUG的风险很大。所以我们会想前移的问题,但是采集这些用户的性能数据就没价值了么?不对,我们可以从数据中提炼规则,规则可以落地到前面说的分析云,甚至是更前置的静态检查,而且这些规则是带度量光环的,例如我们定义分析云的I/O规则,就会说主线程I/O在卡顿的影响有多大。
未来
最后我们不妨来想想未来。最近听得到app的精英日课,里面就有对大数据的应用非常精准的归纳。出了我们前面说的度量效应大小,我们还可以借助用户上报的数据发现反直觉的解决,例如我们就发现File.exist在实际应用的主线程中,比读写磁盘的内容还要耗时,当然,应该是我们已经优化了许多读写磁盘的问题下。据此我们可以定制规则,落地到静态检查或者动态检查。最后,发现罕见案例的规律,其实是说帮助我们发现问题,我们可以对性能数据,机型数据,用户行为进行相关性分析,发现一些特定行为和特定机型的缺陷。

最后不得不说,之前听到个故事,N年前,google的一个设计师因为google用大数据,AB测试的方式来选择界面使用的蓝色而离职。所以不仅仅是人工智能,早在N年前的“大数据”,已经让“失业”的步伐已经开始了。所以我总跟我们的同事说,要跳出思维的圈子,持续学习,勇于面对改变, 让我们“失业”的步伐来得更猛烈些!
广告time
