前言
这里尝试用docker做个简单的服务启动,只要能够正常启动scrapyd,并且外部可以对其进行访问即可。
至于项目打包和利用数据卷进行持久化到下一篇文章再写,到时候要将这几样东西结合起来运行一个完整的项目。--
安装docker
在本地机器上安装docker,只需要输入命令:
sudo apt-get install docker-ce
就可以安装docker了(ce是社区免费版),然后通过命令:
sudo docker images
可以查看docker是否完整安装并且可运行
项目基本知识
scrapyd是scrapy官方团队为用户提供的用于发布scrapy项目的web服务,通过pip install安装好后输入scrapyd即可启动,但是如果需要外部访问则要将bind_adress设置为0.0.0.0
在安装好docker后,需要编写Dockerfile和docker-compose.yml以构建docker镜像。我这里新建了一个空目录,在里面通过sudo nano 编写Dockerfile:
FROM python:3.6
MAINTAINER ranbos
RUN pip install scrapyd \
&& pip install scrapyd-client
COPY default_scrapyd.conf /usr/local/lib/python3.6/site-packages/scrapyd/
CMD ["scrapyd"]
- 基于python3.6
- 作者ranbos
- 安装scrapyd 接着安装scrapyd-client
- 复制本机上改好的default_scrapyd.conf 到docker python镜像内的 /usr/local/lib/python3.6/site-packages/scrapyd/目录下,以覆盖原来的配置文件,实现外部可访问(里面我只改动了bind地址,将127.0.0.1改成0.0.0.0)
- 最后执行命令scrapyd来启动服务
更改后的default_scrapyd.conf内容为:
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
至于为什么复制后的路径是/usr/local/lib/python3.6/site-packages/scrapyd/呢?
在容器启动后,通过命令:
sudo docker exec -it a86 bash
其中a86是镜像id可以进入到容器内部,然后在里面通过:
pip show scrapyd
就可以找到scrapyd的安装路径。
在编写好Dockerfile后,就需要编写docker-compose.yml文件了:
version: '3'
services:
web:
build: .
ports:
- "6800:6800"
指定compose版本
然后指定服务为web
在当前目录构建
映射端口将开放给外部的端口映射到scrapyd服务端口6800
将Dockerfile和docker-compose.yml文件编写好后,通过命令:
sudo docker-compose up
就可以让它自行打包(根据Dockerfile的设定),下载和复制对应的依赖及文件,然后根据docker-compose.yml的设定构建镜像并且运行。

可以看到容器正常启动,而且外部也可以访问scrapyd服务了。
下次启动
这次的打包构建做好了,那么下一次的呢?
通过命令:
sudo docker-images
可以看到本地有一个名为dockerscrapyd_web的镜像,就是刚才我构建的镜像
然后用命令:
sudo docker run -p 6800:6800 dockerscrapyd_web
其中dockerscrapyd_web就是容器的名称,就可以看到它又被启动了。
存储到云仓库
构建好的镜像可以通过命令启动,但是这不是最终目的,最终目的应该是将它放到云仓库当中,当自己需要的时候直接run或者pull就可以使用了。
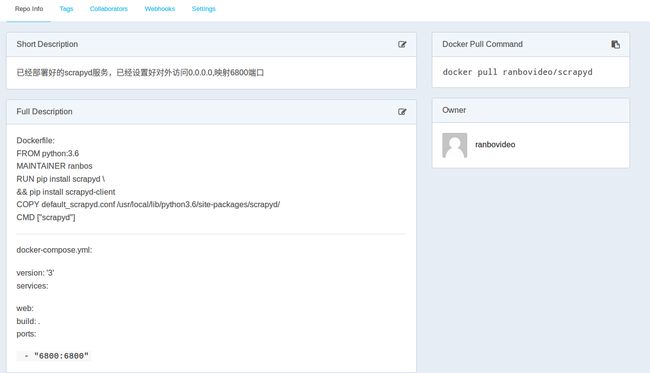
Docker官方为人们提供了这样的服务,网址是hub.docker.com
登录后可以点击create

输入信息后创建一个云镜像
用命令登录docker:
sudo docker login
根据提示输入用户名和密码就行,登录成功后会回传消息:
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
Username: ranbovideo
Password:
Login Succeeded
然后再用命令提交镜像:
sudo docker push /:

后面跟着版本tag,用命令举例:
sudo docker push dockerscrapyd_web
如果是这样的命令,直接输入镜像名称是不行的
会得到回传信息:
denied: requested access to the resource is denied
要根据刚才的格式,将镜像tag和名称改一下:
sudo docker tag dockerscrapyd_web ranbovideo/scrapyd
然后可以用 sudo docker images查看是否改成功。看到镜像存在后用命令进行上传:
sudo docker push ranbovideo/scrapyd:latest
就可以看到它在一步步上传镜像了

注意:推送Docker Hub速度很慢,耐心等待,很有可能失败,之后断开推送(但已推送上去的会保留,保留时间不知道是多久,可以通过刚才的命令继续上传,毕竟一个镜像几百M(我也不知道为什么那么大,700多M,我看了python3.6镜像有690多M,估计就是它),不是那么容易的
最后检查
push上云端之后,为了检查是否正常和正确,我把本地的镜像全都删了,然后从云端将它pull下载到本地运行
阿里云仓库
阿里云也为广大用户提供了仓库,可以传到共有也可以申请私有本地仓库,而且速度肯定比远在国外的hub docker快,而且对于直接在阿里云ECS上部署的话,拉取的速度超快,还不计算公网流量,可以体验一下:
$ sudo docker login --username=m152********@163.com registry.cn-beijing.aliyuncs.com
$ sudo docker tag [ImageId] registry.cn-beijing.aliyuncs.com/ranbos/scrapyd:[镜像版本号]
$ sudo docker push registry.cn-beijing.aliyuncs.com/ranbos/scrapyd:[镜像版本号]
上面由于700多M的数据上传到国外服务器实在是卡得不行,我这次就放在Aliyun的私有仓库中
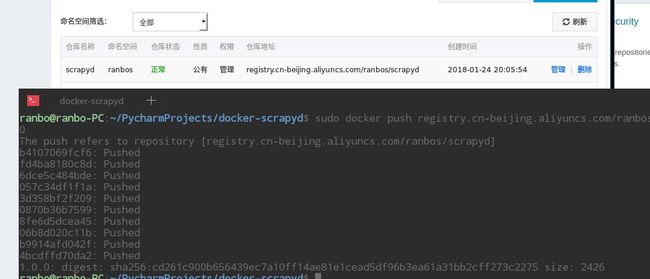
速度真是快的没话说,767M的镜像 2分钟左右上传完毕