
原文:How CALCULATE works in DAX
链接:http://sqlblog.com/blogs/marco_russo/archive/2010/01/03/how-calculate-works-in-dax.aspx
转载:BI佐罗([email protected])
注:计算字段与度量值为同意词。原文对CALCULATE的基础执行已经说明得非常详尽,这里进行翻译整理,以备参考。个人修改与添加内容不再注明。
简介
CALCULATE是学习DAX(也就是学习PowerPivot,PowerBI,Excel数据建模)中最复杂最灵活最强大的函数,没有之一。该文以实验的一步一步的方式揭开CALCULATE不同情景下的效果,如果你正对CALCULATE的诡异表现甚为困惑,那此文必读。
举个例子,在书(绿皮书)《微软Excel 2013:用PowerPivot 建立数据模型》的第269页,有一个关于实现YTD(年度截止到目前累计求和公式),如下:
Sales YTD =
IF (
HASONEVALUE ( Calendar[Year] ),
CALCULATE (
SUM ( FactSales[SalesAmount] ),
FILTER (
ALL ( Calendar ),
Calendar[FullDate] <= MAX ( Calendar[FullDate] )
&& Calendar[Year] = VALUES ( Calendar[Year] )
)
)
)
为了获得累计效果,需要使用ALL获取全部日期,但如此一来,MAX的参数不就是全部日期了吗,那应该得到12月31日,而实际中MAX却表现正确,书中写到MAX使用了筛选上下文,但这仍然无法解释MAX的筛选上下文为什么没有被ALL改变为全部日期,而是当前透视表行标签对应的日期所产生的筛选上下文。
CALCULATE涉及的几个重要内容需要深入理解,分别是:
- CALCULATE的执行顺序
- CALCULATE执行时所处的筛选上下文范围
- CALCULATE的第一个参数特点
- CALCULATE的其他参数(第一个参数以外)特点
- CALCULATE中ALL的作用
- CALCULATE中VALUES的作用
- CALCULATE的上下文转换作用
- CALCULATE的筛选上下文自动传递
- CALCULATE在扩展表作用下的表现
每一个度量值(计算字段)在计算时都涉及到上述所有问题,你可能已经学习了CALCULATE的写法,但CALCULATE远比我们想象的强大和复杂。
测试一下对以下几个例子的理解:
【案例一】
假设DimDate表有2556条记录,则:
CountRows(DimDate)
返回结果:2556。
DimDate与FactSales有激活的关系存在,如下计算:
Calculate(CountRows(DimDate), FactSales)
返回结果:1096。思考为什么?答案是:扩展表原理。
再看如下计算:
CALCULATE ( COUNTROWS ( DimDate ), ALL ( FactSales ) )
返回结果:2556。思考为什么?答案是:对ALL的作用之一:取消筛选的理解。
再看如下计算:
CALCULATE ( COUNTROWS ( DimDate ), FILTER ( ALL ( FactSales ), TRUE ) )
返回结果:1996。思考为什么?答案是:对ALL的作用之二:表函数的理解。
再看一个令人头疼的例子:
DEFINE
MEASURE Sales[Average Sales Amount] =
AVERAGEX ( Sales, 'Sales'[Quantity] * 'Sales'[Net Price] )
EVALUATE
ADDCOLUMNS (
VALUES ( Product[Color] ),
"Sales", CALCULATE ( [Average Sales Amount], FILTER ( Sales, Sales[Quantity] > 3 ) )
)
参考:http://www.sqlbi.com/articles/context-transition-and-expanded-tables/
我们希望返回:不同颜色下,订单中数量大于3的那些订单平均销售额。可结果却是:
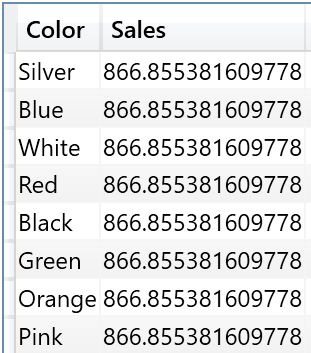
怎么会全部都是一样的?请思考。
答案是:CALCULATE的上下文转换及筛选传递与扩展表的共同作用结果。
再看一个深度例子:
篇幅有限,请直接参考:
http://www.sqlbi.com/daxpuzzle/unexpected-filter-behavior-in-calculate/
完全想通了,那你已经基本掌握CALCULATE计算背后各种可能遇到的坑。
晕了?没关系。
《详解CALCULATE系列》让我们一起逐步了解CALCULATE及相关场景的每个细节。
本文先让我们理解CALCULATE的基本工作原理。
原文
The CALCULATE function in DAX is the magic key for many calculations we can do in DAX. However, it is not pretty intuitive how it works and I spent a lot of time trying to understand how it can be used.
DAX的CALCULATE函数是很多应用场合的关键。然而,它的工作原理远没有看上去那么简单,需要花费很多时间去理解它的用法。
First of all, this is the syntax.
CALCULATE( , , … )
The expression that we put in the first parameter has to be evaluated to return the result (that is a value, not a table). For this reason, the expression is usually an aggregation function like SUM, MIN, MAX, COUNTROWS and so on.
置于CALCULATE函数的第一个参数是为了运算后返回结果(该结果是一个值而不是表),正是这个原因,该参数常常会用聚合函数如SUM, MIN, MAX, COUNTROWS等。
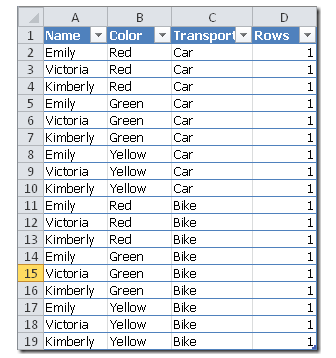
This expression is evaluated in a context that is modified by the filters in the following parameters. A key point is that these filters can both enlarge and restrict the current context of evaluation. Let’s try to understand what it means by considering a few examples. The following table is the one we import in PowerPivot in a table named Demo.
置于CALCULATE函数的第一个参数的表达式会基于CALCULATE函数随后几个筛选器参数所修改的上下文中计算,这些后面的筛选器参数的重要特性就是用来进一步扩大或进一步限制计算的上下文。从下面一个Demo来理解,这是一个原始数据表:
If we project the count of Rows in a PivotTable putting the Name on the Rows, we get the following result:
当使用透视表,将Name置于行标签,计算行数时,得到如下结果:
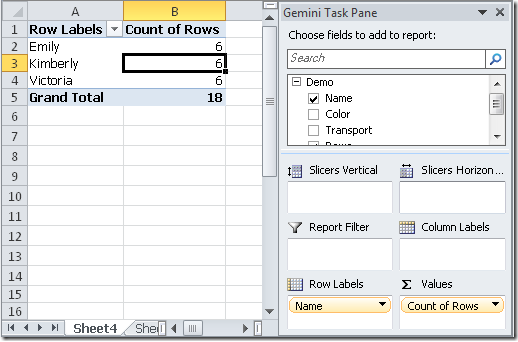
Now, we might have the need to calculate a measure which is not affected by the selection of the Name or, in other words, which always calculate the context for all the names. Thus, we define this calculated measure:
现在,如果需要计算总绝对行数,而不希望受到Name的影响,也就是说希望计算的上下文总是所有的Name,定义如下的计算字段:
CountAllNames =
CALCULATE ( COUNTROWS ( 'Demo' ), ALL ( 'Demo'[Name] ) )
We obtain the CountAllNames column in the PivotTable that always returns the number of all the rows of the Demo table, without considering the filter on the Name.
将该计算字段添加进透视表,可以看到,不受行标签处的Name的筛选,它总是返回所有的行数值,如下:
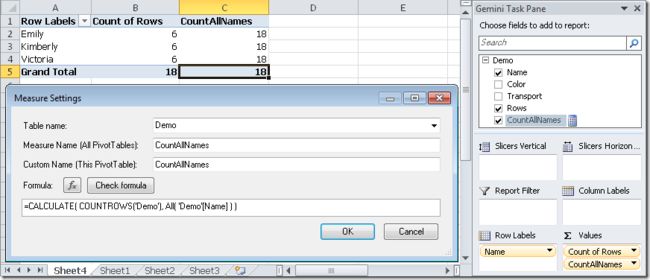
However, if we add Color attribute to the rows of the PivotTable, the CountAllNames is filtered by that attribute too. In fact, for each color, we have 2 rows for a Name (see Count of Rows column) and 6 rows considering all the names (see CountAllNames column).
如果此时添加Color属性到透视表的行标签,计算字段CountAllNames又受到其影响了,观察透视表,可以看出Count of Rows列标黄色的单元格为2,这是因为数据区对应的2行被筛选出,同理 CountAllNames列标绿色的单元格为6,这是因为数据区对应的6行被筛选出,如下所示:
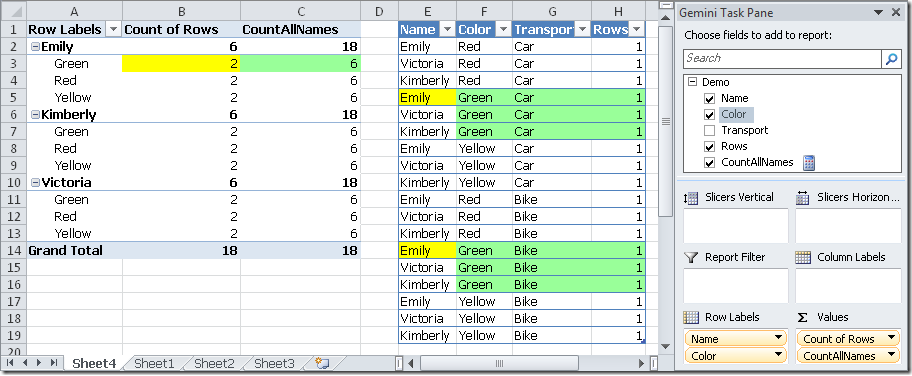
Now, we can also add a Boolean expression as a filter of the CALCULATE function. For example, we might filter just the Car transport.
如果再添加一个对Car的筛选,写出计算字段:
CountAllNamesCar =
CALCULATE (
COUNTROWS ( 'Demo' ),
ALL ( 'Demo'[Name] ),
'Demo'[Transport] = "Car"
)
In this case, we will reduce the CountAllNamesCar column for a color of Emily to 3, because the number of rows with color Green and Car transport are 3.
这种情况下,观察透视表的CountAllNamesCar列,可以看出每个单元格为3,这是因为数据区对应的标绿色的3行被筛选出,也就是满足Color与行标签一致,且transport属性值为Car的行,如下所示:
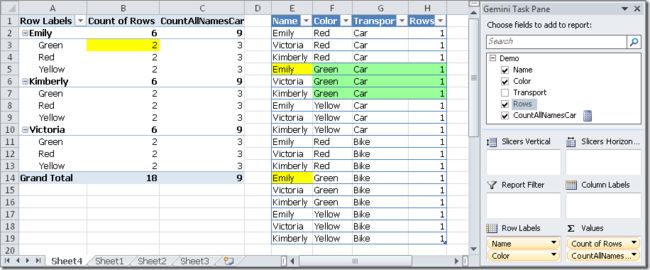
At this point we might wonder whether the Calculate filter parameters are enlarging or restricting the context of evaluation. The rule is the following one.
通过上述几个例子看出,Calculate函数的filter参数部分可以扩大或缩小计算上下文的范围使得计算结果不同,它满足以下规则:
If the current context has a filter on a column of a PowerPivot table (which is a selection of a PivotTable, regardless it is a slicer, a report filter or a row/column selection), any reference for that column in one or more filter parameters of the Calculate function replaces the existing context. Then, the filters specified in the CALCULATE parameters are combined together like they were in an AND condition of a WHERE clause of a SQL SELECT statement.
如果透视表对数据列x存在一个筛选,这个筛选可能是切片器、行/列标签等(用户在操作透视表时产生的筛选);同时,Calculate函数内直接存在对同一个数据列x的筛选参数,那么Calculate函数对数据列x的筛选将替换透视表已有的筛选。接着,该Calculate函数的这些筛选各自对应的行集合进行交集运算便是最后结果。这类似SQL语句Select中WHERE子句中AND条件的效果。
For instance, consider a filter on the Color green using a Boolean expression in the CALCULATE function:
例如,考虑一个在Calculate函数直接使用布尔表达式筛选Color列为green的计算字段,如下标蓝色所示:
ColorGreen =
CALCULATE ( COUNTROWS ( 'Demo' ), 'Demo'[Color] = "Green" )
A Boolean expression used as a filter parameter in a CALCULATE function corresponds to an equivalent FILTER expression that operates on all the values of a column (for this reason, you can only a single column can be used in a Boolean expression that is used as a table filter expression):
CALCULATE函数内直接使用布尔表达式作为筛选参数就等效于一个处理该列所有值的FILTER表达式效果(正是这个原因,作为Calculate函数的布尔表达式筛选参数表达式中只允许使用一列),其等效定义如下所示:
ColorGreen =
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( ALL ( 'Demo'[Color] ), 'Demo'[Color] = "Green" )
)
We obtain that ColorGreen column always filters by color Green and each Name has only 2 rows with color Green.
把ColorGreen放入透视表,结果是ColorGreen列总是筛选Color为Green的行数,所以每个位于ColorGreen列的单元值都是2。
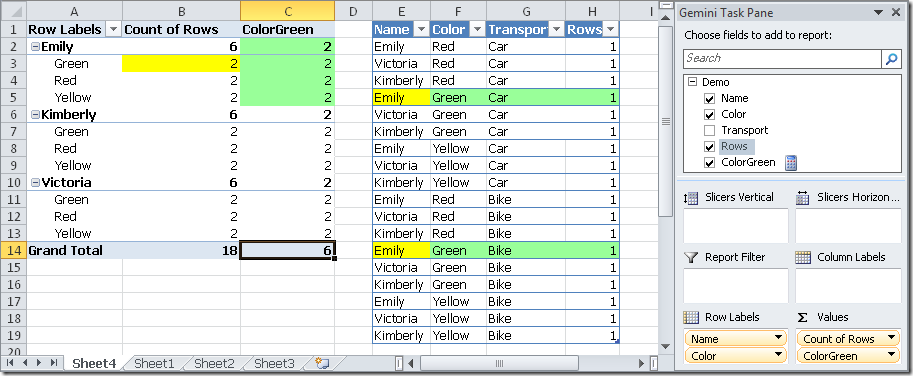
Any filter expression in a CALCULATE statement overrides the existing selection of the PivotTable for the columns it contains. In the previous rule we highlighted the “reference” definition, because the FILTER that is internally used in place of the Boolean expression uses a FILTER expression that returns a set of values for the Color column. Thus, the existing selection for the color (the color is in fact specified in the rows of the PivotTable) is overridden by our filter and only green rows in the source table are considered to calculate the ColorGreen measure value. The true reason we lose the current selection on the color attribute is that the ALL( Demo[Color] ) expression returns a set of all the color values and ignores the existing selection.
如果CALCULATE函数内有筛选表达式,且所筛选的列同样在透视表也存在被筛选的情况,那CALCULATE函数内有筛选表达式会覆盖透视表的筛选。注意上述布尔表达式筛选和FILTER筛选器筛选,实际上,布尔表达式筛选的内部实现正是FILTER(ALL(...),...)筛选表达式。因此,对于这个例子的Color,虽然透视表存在对Color的筛选,但会被计算字段ColorGreen的Calculate中同样对于Color的筛选所覆盖,在覆盖中,ALL( Demo[Color] )表达式返回了所有的行而忽略了透视表已经存在的筛选。
If we don’t want to lose the existing selection of the PivotTable (that means that we don’t want to lose the existing filters on the calculation context), we can simply use in the FILTER expression a function that doesn’t ignore the existing selection. Instead of using the ALL( Demo[Color] ) expression as the source of the filter, we can use the VALUES( Demo[Color] ) expression, which keeps existing selections and returns the values still available in the color attribute.
In fact, if we use the following calculated measure:
如果不希望丢失透视表已经存在的筛选,换句话说,不希望丢失Calculate上下文中已有的筛选器,仍然可以使用FILTER表达式,并使用VALUES( Demo[Color] )子句替换ALL( Demo[Color] )子句,这样就能保持对Demo[Color]列已有的筛选,如下所示:
ColorGreen =
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( VALUES ( 'Demo'[Color] ), 'Demo'[Color] = "Green" )
)
We obtain as a result that the Color filter in the PivotTable is still active, and returns no rows for all the colors but green.
此时透视表的ColorGreen列,除了Color为Green的行标签对应的单元格仍然结果是2,其他单元格都是空。如下所示:
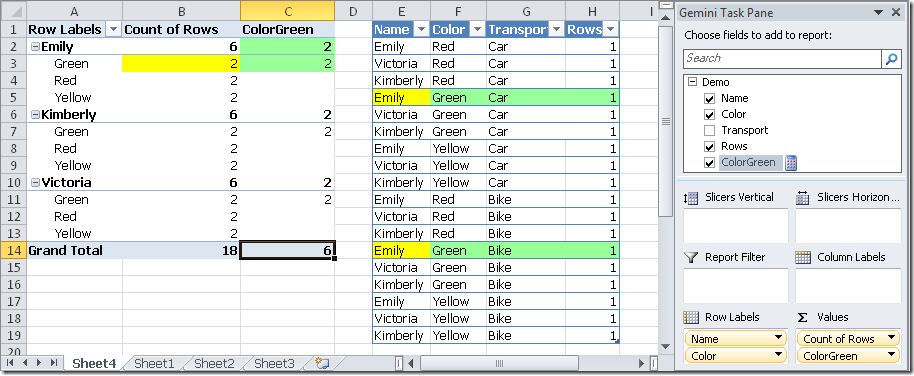
We can see that the FILTER expression in a CALCULATE function always replaces the previous context for the referenced columns. However, we can save the existing context by using an expression which uses the existing context and further restricts the members we want to consider for one or more columns. And this is what we have done using VALUES formula instead of ALL as the first parameter of the FILTER call.
Thanks to Marius Dumitru, the various combination of FILTER, ALL, VALUES in a CALCULATE statement can be summarized in this way.
也就是说,位于CALCULATE函数中的FILTER表达式对其中指定列x的筛选总是会替换之前上下文对该列x的筛选,而且可以通过使用VALUES作为FILTER的第一个参数来保存之前上下文的筛选。CALCULATE的中FILTER,ALL,VALUES的组合应用可总结如下:
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( ALL ( 'Demo'[Color] ), 'Demo'[Color] = "Green" )
)
ignores/replaces existing Color filters and sets a filter on Green
这将忽略/替换已存在的颜色筛选器并重新设置一个Color为Green的筛选器。
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( VALUES ( 'Demo'[Color] ), 'Demo'[Color] = "Green" )
)
keeps existing Color filters and adds a further filter on Green
这将保持已存在的对Demo[Color]列的筛选,并对此列增加一个Color为Green的筛选器。
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( ALL ( 'Demo'[Color] ), 'Demo'[Color] = "Green" ),
VALUES ( 'Demo'[Color] )
)
same as the previous expression (keeps existing Color filters) NOTE: the first filter would consider all the colors, but the second expression (VALUES) only consider the current selection and the two filters will be considered using an AND condition, thus.
与上一个例子类似, FILTER( ALL('Demo'[Color]), 'Demo'[Color] = "Green" )重置了一个Color为Green的筛选器,VALUES('Demo'[Color])保持了已有的筛选器,整个筛选结果是这两个筛选器的综合效果,即同时满足两处筛选的那些行。
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( ALL ( 'Demo' ), 'Demo'[Color] = "Green" )
)
ignores/replaces filters on all Demo columns, and sets a filter on all columns (Name, Transport etc., not just Color) with rows that meet the condition.
注意这里是:ALL('Demo')而不是ALL('Demo'[Color]),即重置对于'Demo'的所有列筛选器,其中'Demo'[Color] = "Green",在这种情况下选择符合筛选的所有行。
Finally, some words of caution have to be spent to the first parameter we pass to the FILTER function. If we consider this expression:
FILTER的第一个参数很重要,再举一个列子如下所示:
ColorGreen =
CALCULATE ( COUNTROWS ( 'Demo' ), FILTER ( 'Demo', 'Demo'[Color] = "Green" ) )
We pass the whole Demo table to the FILTER condition, which results a filter of the current context with all the columns! In this way we apply a restrictions on the color green and we get the same result as before (no rows for all the colors but green, the selection of color of the PivotTable is still applied) but, remember, the FILTER is returning ALL the rows. What does it mean?
在FILTER第一个参数使用整个Demo表,这将使用与Demo表当前筛选上下文完全一致的筛选上下文,在此基础上,重设对'Demo'[Color]列的筛选为Green,虽然整个计算字段ColorGreen的效果与之前是一致的,即除了Color为Green的单元格值为2,其他该列的单元格值为空,但不同的是FILTER在这里返回了所有的列,而不仅仅是'Demo'[Color]这列了。
Well, consider a further selection on the PivotTable where the Transportation attribute is filtered by Bike. This is the result using the ColorGreen definition we have just defined.
为了更充分地理解上面这个FILTER返回单列和多列的不同,对透视表增加一个Transportation 为Bike的报表筛选,此时在刚刚定义的计算字段ColorGreen列对应的值处可以看出变化,由于FILTER是在与'Demo'当前完全一致的筛选上下文(也就是携带着Transportation 为Bike的报表筛选)基础上再做'Demo'[Color] = "Green"的进一步筛选,对于行标签为Green处符合筛选的只有一行,透视表单元格值为1,标为绿色,如下所示:
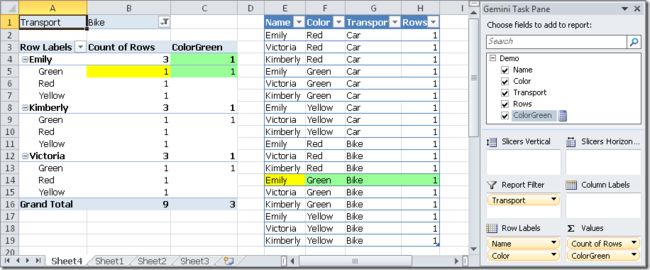
Now, let’s add another filter to the CALCULATE function, filtering also the rows with Trasport equals to Car.
所有透视表的情况不变,再进一步修改计算字段CarGreen如下:
CarGreen =
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( 'Demo', 'Demo'[Color] = "Green" ),
'Demo'[Transport] = "Car"
)
which, as we have seen before, corresponds to:
如之前所述,CALCULATE筛选参数形如“表[列]=值”的布尔表达式等效于“FILTER(ALL(表[列]),表[列]=值)”,即:
CarGreen =
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( 'Demo', 'Demo'[Color] = "Green" ),
FILTER ( ALL ( 'Demo'[Transport] ), 'Demo'[Transport] = "Car" )
)
The results is that the filter for Bike defined in the PivotTable plus the filter for Car defined in the CarGreen measure returns no rows at all in the CarGreen result. If we think about it, why this happens is not very intuitive at this point!
结果是两个FILTER的结果的交集,第一个FILTER使用已存在的筛选上下文,包括行/列标签处即报表筛选器,并覆盖替换'Demo'[Color]列的筛选器为"Green",选出符合的行;第二个FILTER只是针对'Demo'[Transport]列,覆盖替换'Demo'[Transport]列的筛选器为"Car",选出符合的行;这时对于计算字段CarGreen的每个单元格值都是空。这点只有严格根据已知的规则去计算才会明确知道结果,已不是单从表面就能看出来的了,如下所示:
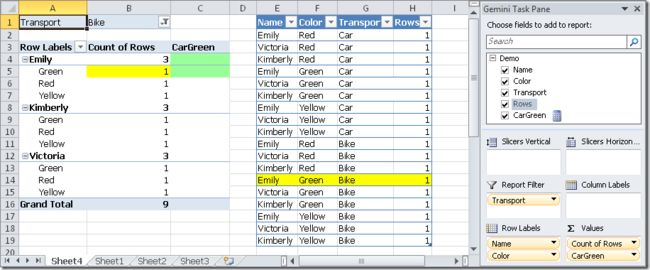
Our filter on the Transport column is actually restricting the current selection and is not replacing it! But, wait, if we write just the filter on Transport, without the filter on Color, we have:
值得注意和强调的关键是:第二个FILTER对于Transport列并非替换了当前筛选上下文,从Bike替换为Car,而只是在这个FILTER里将当前筛选上下文对于Transport列重新做了限定,限定为Car。如果去掉第一个对于Color的筛选器,如下所示:
TransportCar =
CALCULATE ( COUNTROWS ( 'Demo' ), 'Demo'[Transport] = "Car" )
that produces the following result, which replaces the Bike selection of the PivotTable in the TransportCar column!
这将Transport列重新做了限定,限定为Car,这种重新限定也可以说是替换了报表筛选器对Transport列的筛选,如下所示:
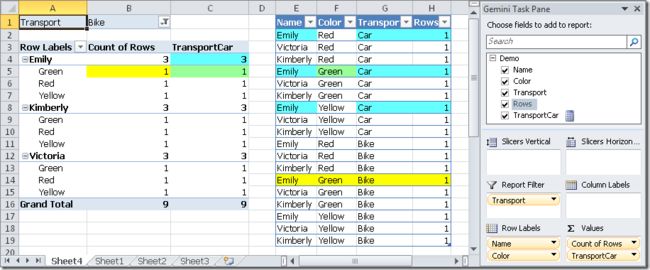
This last calculation (TransportCar) is simple to explain, because it has the same behavior we have seen before with the first ColorGreen calculated measure, where the filter of the color green replaced any existing color selection in the PivotTable. The difference in the CarGreen calculation is the other filter parameter, which returns all the columns from the Demo table. Consider the highlighted filter in the CarGreen formula:
这个计算字段TransportCar很容易解释,但和之前定义的计算字段ColorGreen 的解释不同的是,以表'Demo'作为FILTER的第一个参数时,返回的是所有的列:
CarGreen =
CALCULATE (
COUNTROWS ( 'Demo' ),
FILTER ( 'Demo', 'Demo'[Color] = "Green" ),
FILTER ( ALL ( 'Demo'[Transport] ), 'Demo'[Transport] = "Car" )
)
The filter on color green returns all the columns of the current context. If we consider the corresponding rows for the cell B5 of the PivotTable (Emily, Green, Bike), this is just one row (the yellow one), and this row has the Bike value for the Transport attribute. When we apply the second filter, we have a single value for the attribute Transport, which is Car. At this point, the intersection between those two sets of Transport (one is only Bike, the other is only Car) is an empty set. Thus, the result for CarGreen measure is empty, because there are no corresponding rows for the selection made.
第一个FILTER返回了基于当前筛选上下文的所有列,如以上的透视表所示,如果考虑位于B5的单元格,被透视表筛选限定为(Emily, Green, Bike),这对应于计算字段Count of Rows的单元格,值为1,即只有一行同时满足筛选;再考虑第二个FILTER,返回Transport列值为Car的行;同时考虑两个FILTER,它们结果的交集是空。值得注意和强调的是:第二个FILTER对于Transport列并非替换了当前筛选上下文,从Bike替换为Car,而只是单纯地基于Filter的规则进行计算。
This can be tricky, but we finally have this behavior.
- The CALCULATE function applies a calculation (the first parameter) for each cell, considering the resulting context by applying the filters (the second and following parameters) to the current context.
- Each filter can have values for one or more columns.
- Each column is computed individually in the filters expressions of the CALCULATE function
- If a column value is specified in at least one filter, it replaces the selection of the current context for that column.
- If a filter expression returns more columns, each one has its own independent set of values in the final calculation context definition
- If a column is specified in more filters, the resulting values are the intersection of these set of values (for that column).
- After all the filters have been evaluated, the intersection of the column values determines the calculation context for the expression passed as the first parameter to the CALCULATE function
Despite its complexity, this calculation is pretty fast. The key point is to understand all the side effects we have when a filter returns more columns than those we specified in the filter condition itself, which is something we have to consider carefully each time we use one or more FILTER functions inside a CALCULATE expression.
最终总结以上所有行为的规律如下:
- CALCULATE函数基于当前上下文应用第二个参数起所有筛选器对(计算字段)每个单元格使用第一个参数进行计算。
- 每个筛选器可以是对单列或多列的。
- 每列都在CALCULATE函数的等效FILTER表达式中独立计算。
- 如果CALCULATE函数的等效FILTER表达式对某列存在筛选,这将覆盖/替换当前筛选上下文位于该列的筛选器。
- 如果等效FILTER表达式返回多列,每一列都有独立的结果。
- 如果某列在不同的等效FILTER表达式结果中均有返回,该列的最终筛选结果是交集。
- 在所有等效FILTER计算后,这些被筛选的列的交集形成了CALCULATE第一个参数计算的上下文。
这种复杂机制是为了确保计算的效率,关键是要搞清楚可能对CALCULATE计算上下文产生影响的各个方面,尤其是置于CALCULATE函数中的诸多FILTER的共同作用。
后记
考虑开篇给出的案例作为收尾:
YTD =
IF (
HASONEVALUE ( Calendar[Year] ),
CALCULATE (
SUM ( FactSales[SalesAmount] ),
FILTER (
ALL ( Calendar ),
Calendar[FullDate] <= MAX ( Calendar[FullDate] )
&& Calendar[Year] = VALUES ( Calendar[Year] )
)
)
)
ALL( Calendar )对Calendar做了重新限定,FILTER将对Calendar所有的行做迭代返回<=MAX(Calendar[FullDate])的行集合,而关键是MAX进行运算的上下文是什么,是透视表产生的上下文还是ALL( Calendar ),如果是透视表产生的上下文,将根据不同行标签得到不同的值,如果是ALL( Calendar ),总会得到最大日期,现实情况是运算是符合预期的正确的,也就是前者,而不是ALL( Calendar )。关键在于正文中重复了多次的关键:FILTER对于表/列并非替换了当前筛选上下文,而只是在这个FILTER里将当前筛选上下文对于表/列重新做了限定。MAX使用的当前上下文并没有变化。值得进一步揭示的是:FILTER对于表/列并非替换了当前筛选上下文,而只是单纯地根据FILTER的规则进行计算。
为了更好地理解带有ALL的问题,我们需要在后续的文章中进一步讨论。
