0.前言
RMQ对于消息持久化的方式是顺序写到本地磁盘文件,相对于持久化到远程的数据库或者KV来说,往本地磁盘文件持久化消息少去了网络开销以及因为带宽的原因影响到消息的发送和消费的TPS,但是相对而言想要设计一个能从本地磁盘高性能精确读和精确写的程序还是要下不少功夫的...
1.构成
以commitlog为例子,持久化后的文件一般都如下
而完成持久化文件创建以及写入管理由这些基础操作主要由rocketmq-store包下的以下几个类配合完成
- MapedFile(对应一个持久化文件,如上图所示范)
- MapedFileQueue(管理所有创建的MapedFile)
- AllocateMapedFileService(负责创建MapedFile)
可能单单用文字描述这几个类不够直观,所以我画了如下的示意图(程序员的画功):
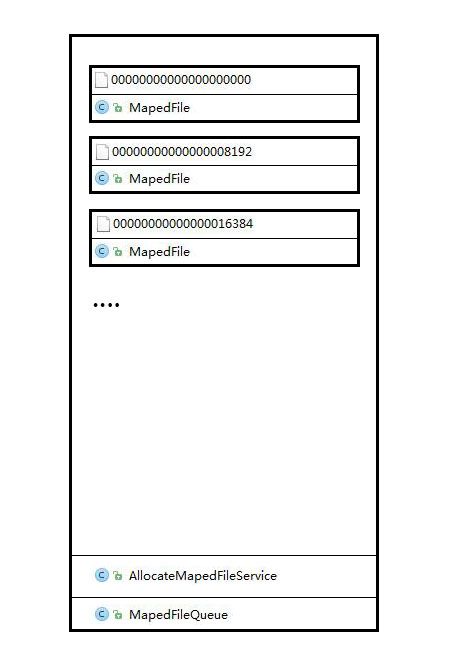
MapedFileQueue用于管理一批MapedFile同时也管理何时创建MapedFile,而具体创建MapedFile的任务则是由AllocateMapedFileService这个类完成,这3个类构成了RMQ文件持久化的基础。
2.基础知识
2.1Page Cache
顾名思义可以叫做页缓存,而每一页的大小通常是4K,在Linux系统中写入数据的时候并不会直接写到硬盘上,而是会先写到Page Cache中,并打上dirty标识,由内核线程flusher定期将被打上dirty的页发送给IO调度层,最后由IO调度决定何时落地到磁盘中,而Linux一般会把还没有使用的内存全拿来给Page Cache使用。而读的过程也是类似,会先到Page Cache中寻找是否有数据,有的话直接返回,如果没有才会到磁盘中去读取并写入Page Cache然后再次读取Page Cache并返回。而且读的这个过程中操作系统也会有一个预读的操作,你的每一次读取操作系统都会帮你预读出后面一部分数据,而且当你一直在使用预读数据的时候,系统会帮你预读出更多的数据(最大到128K)。
2.2mmap
mmap是一种将文件映射到虚拟内存的技术,可以将文件在磁盘位置的地址和在虚拟内存中的虚拟地址通过映射对应起来,之后就可以在内存这块区域进行读写数据,而不必调用系统级别的read,wirte这些函数,从而提升IO操作性能,另外一点就是mmap后的虚拟内存大小必须是内存页大小(通常是4K)的倍数,之所以这么做是为了匹配内存操作。
3.实现
3.1MapedFile
RMQ的文件存储中,最终对应内存和文件映射的类是MapedFile这个类,而这个类完成内存和文件的映射主要是通过Java NIO包下FileChannel所提供的map方法来完成,这个类的构造函数如下:
public MapedFile(final String fileName, final int fileSize) throws IOException {
this.fileName = fileName;
this.fileSize = fileSize;
this.file = new File(fileName);
this.fileFromOffset = Long.parseLong(this.file.getName());
boolean ok = false;
ensureDirOK(this.file.getParent());
try {
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
TotalMapedVitualMemory.addAndGet(fileSize);
TotalMapedFiles.incrementAndGet();
ok = true;
} catch (FileNotFoundException e) {
log.error("create file channel " + this.fileName + " Failed. ", e);
throw e;
} catch (IOException e) {
log.error("map file " + this.fileName + " Failed. ", e);
throw e;
} finally {
if (!ok && this.fileChannel != null) {
this.fileChannel.close();
}
}
}
这个类接受2个参数,一个是带完整路径的文件名,另一个是这个映射文件的大小,也是这个文件最大的大小,最后通过
this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
完成文件映射到内存的操作,映射大小是整个文件的大小,并返回一个MappedByteBuffer对象,之后我们想对映射后的内存区域操作都可以通过MappedByteBuffer提供的方法来完成。关于Java NIO包下MappedByteBuffer更详细的介绍大家可以自行搜索一下~
MapedFile提供了appendMessage方法来让你追加对象到映射内存中,同时这个方法也有一个重载,用于让你追加byte类型数据到映射内存中,两个方法实现类似,看懂一个另一个也不会太难懂,来看一个追加对象到映射文件的实现:
public AppendMessageResult appendMessage(final Object msg, final AppendMessageCallback cb) {
assert msg != null;
assert cb != null;
int currentPos = this.wrotePostion.get();
if (currentPos < this.fileSize) {
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
byteBuffer.position(currentPos);
AppendMessageResult result =
cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, msg);
this.wrotePostion.addAndGet(result.getWroteBytes());
this.storeTimestamp = result.getStoreTimestamp();
return result;
}
log.error("MapedFile.appendMessage return null, wrotePostion: " + currentPos + " fileSize: "
+ this.fileSize);
return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);
}
这个方法接受2个参数,第一个是要追加进映射文件的对象,同时每个MapedFile对象内部还维护了一个类型为AtomicInteger的wrotePostion变量,用于记录当前追加了多少个字节大小,在每次追加后都会自增这个变量,自增的大小为追加对象序列化后的大小,第二个是接受一个AppendMessageCallback的实现类,用于序列化要追加的对象并写入,在CommitLog类中有一个名为DefaultAppendMessageCallback的内部类,用于存储消息对象到映射文件中,AppendMessageCallback的接口定义如下
public interface AppendMessageCallback {
/**
* After message serialization, write MapedByteBuffer
*
* @param byteBuffer
* @param maxBlank
* @param msg
*
* @return How many bytes to write
*/
public AppendMessageResult doAppend(final long fileFromOffset, final ByteBuffer byteBuffer,
final int maxBlank, final Object msg);
}
这个接口要求实现一个doAppend方法,并接受4个参数,第一个参数fileFromOffset可以暂时理解为连续文件开始的下标,类似数组一样,第一个元素从0开始,第二个元素从1开始....而从文章第一幅的图可以看出,MapedFile映射的文件在一起都是,第一个映射文件名是00000000000000000000,第二个映射文件名是000000000000008192.....,文件名就是这些文件的下标,第一个文件是从0开始。第二个文件是从8192开始,依次类推,这里可以看出单个文件的大小是8K,文件名也以8K为递增,所以第三个文件的fileFromOffset通过文件名000000000000016384可以知道是16384,当然单个MapedFile的文件大小是可以通过构造函数第二个参数指定的,本文单个文件大小是8K。
第二个参数是MapedFile通过调用ByteBuffer的slice()方法获取一份副本所传入的,doAppend序列化后也是通过这个byteBuffer写入到映射虚拟内存中。
第三个参数是这个byteBuffer还剩多少大小可供写入,从MapedFile的appendMessage方法可以看到传入的是this.fileSize - currentPos,这个currentPos就是MapedFile内部维护的wrotePostion变量,这个变量记录了一共写入了多少字节大小,最后一个参数就不用多少了,要序列化写入映射虚拟内存的对象。
当数据写入到映射虚拟内存后,如何保证数据已经写到磁盘文件呢?在MapedFile中有一个commit方法,实现如下
public int commit(final int flushLeastPages) {
if (this.isAbleToFlush(flushLeastPages)) {
if (this.hold()) {
int value = this.wrotePostion.get();
this.mappedByteBuffer.force();
this.committedPosition.set(value);
this.release();
} else {
log.warn("in commit, hold failed, commit offset = " + this.committedPosition.get());
this.committedPosition.set(this.wrotePostion.get());
}
}
return this.getCommittedPosition();
}
主要保障数据写到磁盘文件的是MappedByteBuffer提供的force方法,它会强制将映射虚拟内存的数据写到磁盘文件中,但并不是调用commit就会强制写入一次,方法内部也会有一次判断决定是否强制写入,所以commit方法有一个参数flushLeastPages,之前我们说过mmap映射后的内存一般是内存页大小的倍数,而内存页大小一般为4K,所以写入到映射内存的数据大小可以以4K进行分页,而flushLeastPages这个参数只是指示写了多少页后才可以强制将映射内存区域的数据强行写入到磁盘文件,具体的判断实现在isAbleToFlush这个方法,如下
private boolean isAbleToFlush(final int flushLeastPages) {
int flush = this.committedPosition.get();
int write = this.wrotePostion.get();
if (this.isFull()) {
return true;
}
if (flushLeastPages > 0) {
return ((write / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE)) >= flushLeastPages;
}
return write > flush;
}
wrotePostion这个变量前面已经说过了,每次通过appendMessage方法写入数据到映射内存的时候都是自增这个变量,自增大小是写入数据的字节大小,而committedPosition这个变量则是通过commit方法判断可以强制将映射内存区域的数据写到磁盘文件的时候会设置这个变量为wrotePostion变量当前记录的大小。
通过上面的实现可以看出,如果通过方法isFull判断文件已经写满了是可以强制写文件的,然而就是如果没满而且给commit方法的参数大于0,则会先按OS_PAGE_SIZE(内存页大小,这里是4K每页)大小通过“write / OS_PAGE_SIZE”求出已经写入了多少页,同理,然后依然通过内存页大小通过“flush / OS_PAGE_SIZE”求出已经提交了多少页,然后相减得出已经写入了多少页了,这个时候比较commit的参数flushLeastPages,如果大于等于这个值则也可以强制写入文件,当然如果给commit的参数给了一个0,则比较写入的大小是否大于提交的大小“write > flush”,也就是只要一写入数据到映射内存就可以强制写到文件中。
3.2AllocateMapedFileService
你可以选择徒手new MapedFile对象的同时也可以选择使用AllocateMapedFileService类来帮你构造MapedFile,AllocateMapedFileService内部维护了一个类型为PriorityBlockingQueue的requestQueue队列,通过一个线程去处理队列中创建MapedFile的请求达到创建MapedFile的串行化。
还是一样,先看构造函数
public AllocateMapedFileService(DefaultMessageStore messageStore) { this.messageStore = messageStore; }
依赖一个DefaultMessageStore类,这个类实现了RMQ对消息的存储,现在的版本基本上可是说是必须的,不能给null,因为内部的方法都是直接使用messageStore的方法,如果给null会直接触发Null异常。
在AllocateMapedFileService里面,分配MapedFile的请求都被封装为一个名叫AllocateRequest的内部类,这个内部类的总览定义如下
static class AllocateRequest implements Comparable {
// Full file path
private String filePath;
private int fileSize;
private CountDownLatch countDownLatch = new CountDownLatch(1);
private volatile MapedFile mapedFile = null;
public AllocateRequest(String filePath, int fileSize) {
this.filePath = filePath;
this.fileSize = fileSize;
}
......
}
这个分配MapedFile的请求类接受2个参数,一个是要创建的MapedFile的完整路径并带上文件名,第二个是要分配的MapedFile的文件大小。
通过AllocateMapedFileService创建MapedFile的方法是putRequestAndReturnMapedFile,这个方法的实现如下
public MapedFile putRequestAndReturnMapedFile(String nextFilePath, String nextNextFilePath, int fileSize) {
AllocateRequest nextReq = new AllocateRequest(nextFilePath, fileSize);
AllocateRequest nextNextReq = new AllocateRequest(nextNextFilePath, fileSize);
boolean nextPutOK = (this.requestTable.putIfAbsent(nextFilePath, nextReq) == null);
boolean nextNextPutOK = (this.requestTable.putIfAbsent(nextNextFilePath, nextNextReq) == null);
if (nextPutOK) {
boolean offerOK = this.requestQueue.offer(nextReq);
if (!offerOK) {
log.warn("never expetced here, add a request to preallocate queue failed");
}
}
if (nextNextPutOK) {
boolean offerOK = this.requestQueue.offer(nextNextReq);
if (!offerOK) {
log.warn("never expetced here, add a request to preallocate queue failed");
}
}
if (hasException) {
log.warn(this.getServiceName() + " service has exception. so return null");
return null;
}
AllocateRequest result = this.requestTable.get(nextFilePath);
try {
if (result != null) {
boolean waitOK = result.getCountDownLatch().await(WaitTimeOut, TimeUnit.MILLISECONDS);
if (!waitOK) {
log.warn("create mmap timeout " + result.getFilePath() + " " + result.getFileSize());
return null;
} else {
this.requestTable.remove(nextFilePath);
return result.getMapedFile();
}
} else {
log.error("find preallocate mmap failed, this never happen");
}
} catch (InterruptedException e) {
log.warn(this.getServiceName() + " service has exception. ", e);
}
return null;
}
这个方法接受3个参数,第一个是当前要分配的MapedFile的带路径的文件名,第二个是下一次要分配的MapedFile的带路径的文件名,这是因为putRequestAndReturnMapedFile会一次性创建2个MapedFile,第三个是分配的MapedFile的文件大小。
可以看到内部首先先创建2个MapedFile创建请求对象,一个是当前需要创建的,另一个是下一次需要创建的,然后分别将2个请求放进map中,最后确认如果存放到map成功,则通过offer方法添加到PriorityBlockingQueue中,最后会从map中取出负责创建当前MapedFile的AllocateRequest对象,从前面AllocateRequest的定义中可以发现内部有一个CountDownLatch类的锁,这个时候putRequestAndReturnMapedFile方法会通过获取这个锁变量等待MapedFile的创建完成,当创建完成后会从requestTable移除掉这个请求并将创建好的MapedFile对象返回回去,如果失败则返回null。
当然putRequestAndReturnMapedFile方法虽然把创建请求对象AllocateRequest放到了PriorityBlockingQueue中,可谁来消费的呢?AllocateMapedFileService继承了一个抽象类ServiceThread,这是RMQ自己封装一个线程服务类,也就是意味着AllocateMapedFileService这个类是可以被启动的,从这个类的run方法实现如下
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStoped() && this.mmapOperation())
;
log.info(this.getServiceName() + " service end");
}
这个类一直循环调用一个叫mmapOperation的方法,找到mmapOperation方法,这个方法实现如下
private boolean mmapOperation() {
boolean isSuccess = false;
AllocateRequest req = null;
try {
req = this.requestQueue.take();
AllocateRequest expectedRequest = this.requestTable.get(req.getFilePath());
if (null == expectedRequest) {
log.warn("this mmap request expired, maybe cause timeout " + req.getFilePath() + " "
+ req.getFileSize());
return true;
}
if (expectedRequest != req) {
log.warn("never expected here, maybe cause timeout " + req.getFilePath() + " "
+ req.getFileSize() + ", req:" + req + ", expectedRequest:" + expectedRequest);
return true;
}
if (req.getMapedFile() == null) {
long beginTime = System.currentTimeMillis();
MapedFile mapedFile = new MapedFile(req.getFilePath(), req.getFileSize());
long eclipseTime = UtilAll.computeEclipseTimeMilliseconds(beginTime);
if (eclipseTime > 10) {
int queueSize = this.requestQueue.size();
log.warn("create mapedFile spent time(ms) " + eclipseTime + " queue size " + queueSize
+ " " + req.getFilePath() + " " + req.getFileSize());
}
// pre write mappedFile
if (mapedFile.getFileSize() >= this.messageStore.getMessageStoreConfig()
.getMapedFileSizeCommitLog() //
&& //
this.messageStore.getMessageStoreConfig().isWarmMapedFileEnable()) {
mapedFile.warmMappedFile(this.messageStore.getMessageStoreConfig().getFlushDiskType(),
this.messageStore.getMessageStoreConfig().getFlushLeastPagesWhenWarmMapedFile());
}
req.setMapedFile(mapedFile);
this.hasException = false;
isSuccess = true;
}
} catch (InterruptedException e) {
log.warn(this.getServiceName() + " service has exception, maybe by shutdown");
this.hasException = true;
return false;
} catch (IOException e) {
log.warn(this.getServiceName() + " service has exception. ", e);
this.hasException = true;
if (null != req) {
requestQueue.offer(req);
try {
Thread.sleep(1);
} catch (InterruptedException e1) {
}
}
} finally {
if (req != null && isSuccess)
req.getCountDownLatch().countDown();
}
return true;
}
你会发现,这个方法一直从类型为PriorityBlockingQueue的requestQueue变量将putRequestAndReturnMapedFile添加进去的AllocateRequest对象take出来并消费。
mmapOperation方法将AllocateRequest从PriorityBlockingQueue取出后,如果AllocateRequest内部没有包含MapedFile也就是“req.getMapedFile() == null”就会开始创建流程,流程内将会new一个MapedFile对象并将AllocateRequest中的filePath和fileSize都设置给刚实例化的MapedFile对象。
之后,中间那一段,如果你的MapedFile大小设置的大于或者等于getMapedFileSizeCommitLog(默认1G)方法返回的值并且isWarmMapedFileEnable为true,就会按照OS_PAGE_SIZE的大小为1页进行byteBuffer.put(i, (byte) 0)然后mappedByteBuffer.force();,为什么这样做,我的猜想是,因为操作系统读写文件基本上只和Page Cache打交道,所以中间如果没有命中Page Cache则会产生一个缺页异常然后创建一个页再去读磁盘内容最后写回Page Cache最后在读取Page Cache命中然后返回,这可能是为了避免之后产生过多的缺页异常,当然我这个猜想也可能不对,欢迎拍砖纠正~这个MapedFile的warmMappedFile实现如下
public void warmMappedFile(FlushDiskType type, int pages) {
long beginTime = System.currentTimeMillis();
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
int flush = 0;
long time = System.currentTimeMillis();
for (int i = 0, j = 0; i < this.fileSize; i += MapedFile.OS_PAGE_SIZE, j++) {
byteBuffer.put(i, (byte) 0);
// force flush when flush disk type is sync
if (type == FlushDiskType.SYNC_FLUSH) {
if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) {
flush = i;
mappedByteBuffer.force();
}
}
// prevent gc
if (j % 1000 == 0) {
log.info("j={}, costTime={}", j, System.currentTimeMillis() - time);
time = System.currentTimeMillis();
try {
Thread.sleep(0);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// force flush when prepare load finished
if (type == FlushDiskType.SYNC_FLUSH) {
log.info("mapped file worm up done, force to disk, mappedFile={}, costTime={}",
this.getFileName(), System.currentTimeMillis() - beginTime);
mappedByteBuffer.force();
}
log.info("mapped file worm up done. mappedFile={}, costTime={}", this.getFileName(),
System.currentTimeMillis() - beginTime);
this.mlock();
}
warmMappedFile接受2个参数,一个是刷盘的类型,有同步:SYNC_FLUSH和异步:ASYNC_FLUSH,当然强制写回磁盘的策略和之前说过的MapedFile的commit是一致的,按照 (写入字节 / OS_PAGE_SIZE) - (force后提交字节 / OS_PAGE_SIZE) = 已经写入的页,最后比较传入的pages参数“(i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages”来决定是否mappedByteBuffer.force(),在这个循环里不断向映射的内存区域写入字节数据,循环结束后,在将还没写到磁盘的数据在来一遍force来达到最后flush效果,最后这个mlock是个黑科技了,实现如下
public void mlock() {
final long beginTime = System.currentTimeMillis();
final long address = ((DirectBuffer) (this.mappedByteBuffer)).address();
Pointer pointer = new Pointer(address);
{
int ret = LibC.INSTANCE.mlock(pointer, new NativeLong(this.fileSize));
log.info("mlock {} {} {} ret = {} time consuming = {}", address, this.fileName, this.fileSize, ret, System.currentTimeMillis() - beginTime);
}
{
int ret = LibC.INSTANCE.madvise(pointer, new NativeLong(this.fileSize), LibC.MADV_WILLNEED);
log.info("madvise {} {} {} ret = {} time consuming = {}", address, this.fileName, this.fileSize, ret, System.currentTimeMillis() - beginTime);
}
}
这个方法是一个Native级别的调用,调用了标准C库的方法,首先看mlock方法,mlock方法在标准C中的实现是将锁住指定的内存区域避免被操作系统调到swap空间中,而madvise方法则要配合着mmap来说了,一般来说通过mmap建立起的内存文件在刚开始并没有将文件内容映射进来,而是只建立一个映射关系,而当你读相对应区域的时候,它第一次还是会去读磁盘,而我们前面说了,读写基本上都只是和Page Cache打交道,那么当读相对应页没有拿到数据的时候,系统将会产生一个缺页异常,然后去读磁盘中的内容,最后写回Page Cache然后再次读取Page Cache然后返回,而madvise的作用是一次性先将一段数据读入到映射内存区域,这样就减少了缺页异常的产生,不过mlock和madvise在windows下的C库可没有,所以如果要在windows下调试,还是要做一些修改,我的修改如下
public void mlock() {
if (!Platform.isWindows()) {
final long beginTime = System.currentTimeMillis();
final long address = ((DirectBuffer) (this.mappedByteBuffer)).address();
Pointer pointer = new Pointer(address);
{
int ret = LibC.INSTANCE.mlock(pointer, new NativeLong(this.fileSize));
log.info("mlock {} {} {} ret = {} time consuming = {}", address, this.fileName, this.fileSize, ret, System.currentTimeMillis() - beginTime);
}
{
int ret = LibC.INSTANCE.madvise(pointer, new NativeLong(this.fileSize), LibC.MADV_WILLNEED);
log.info("madvise {} {} {} ret = {} time consuming = {}", address, this.fileName, this.fileSize, ret, System.currentTimeMillis() - beginTime);
}
} else {
log.info("Platform is windows. not support mlock");
}
}
3.3MapedFileQueue
通过MapedFile你可以完成文件存储,但是如果你单用这个类还有很多问题会等着你解决,比如,你需要管理单个MapedFile写满后创后续MapedFile并管理的工作,你还需要解决如果存在多个MapedFile如何查询offset的工作等,当然自己写不会太难,所以MapedFileQueue就是负责管理MapedFile的工作,还是先来看构造函数
public MapedFileQueue(final String storePath, int mapedFileSize,
AllocateMapedFileService allocateMapedFileService) {
this.storePath = storePath;
this.mapedFileSize = mapedFileSize;
this.allocateMapedFileService = allocateMapedFileService;
}
MapedFileQueue接受3个参数,第一个是后续创建一些列MapedFile的存储路径位置,第二个参数指示单个MapedFile的文件大小,也是最大大小,第三个则是一个负责创建MapedFile对象的服务,当MapedFileQueue要创建MapedFile的时候都是通过这个Service类完成。
在RMQ中写文件的常见流程是通过MapedFileQueue获取到MapedFile,然后通过MapedFile的appendMessage写入追加数据,MapedFileQueue常用的2个获取MapedFile的方法是getLastMapedFileWithLock和getLastMapedFile,这2个方法都是获取最后一个MapedFile的方法实习,区别就是getLastMapedFileWithLock如果获取不到返回的是个null,而getLastMapedFile获取不到则会创建MapedFile然后返回,先看getLastMapedFileWithLock的实现,非常简单的实现
public MapedFile getLastMapedFileWithLock() {
MapedFile mapedFileLast = null;
this.readWriteLock.readLock().lock();
if (!this.mapedFiles.isEmpty()) {
mapedFileLast = this.mapedFiles.get(this.mapedFiles.size() - 1);
}
this.readWriteLock.readLock().unlock();
return mapedFileLast;
}
MapedFileQueue创建的MapedFile对象都放在内部类型为ArrayList的mapedFiles变量中,而获取最后一个的逻辑也非常简单,mapedFiles的size减1就是最后一个MapedFile位于ArrayList的index,如果是空的则返回一个null。
getLastMapedFile方法调用的是重载方法,这个重载方法的实现如下
public MapedFile getLastMapedFile(final long startOffset, boolean needCreate) {
long createOffset = -1;
MapedFile mapedFileLast = null;
{
this.readWriteLock.readLock().lock();
if (this.mapedFiles.isEmpty()) {
createOffset = startOffset - (startOffset % this.mapedFileSize);
} else {
mapedFileLast = this.mapedFiles.get(this.mapedFiles.size() - 1);
}
this.readWriteLock.readLock().unlock();
}
if (mapedFileLast != null && mapedFileLast.isFull()) {
createOffset = mapedFileLast.getFileFromOffset() + this.mapedFileSize;
}
if (createOffset != -1 && needCreate) {
String nextFilePath = this.storePath + File.separator + UtilAll.offset2FileName(createOffset);
String nextNextFilePath =
this.storePath + File.separator
+ UtilAll.offset2FileName(createOffset + this.mapedFileSize);
MapedFile mapedFile = null;
if (this.allocateMapedFileService != null) {
mapedFile =
this.allocateMapedFileService.putRequestAndReturnMapedFile(nextFilePath,
nextNextFilePath, this.mapedFileSize);
} else {
try {
mapedFile = new MapedFile(nextFilePath, this.mapedFileSize);
} catch (IOException e) {
log.error("create mapedfile exception", e);
}
}
if (mapedFile != null) {
this.readWriteLock.writeLock().lock();
if (this.mapedFiles.isEmpty()) {
mapedFile.setFirstCreateInQueue(true);
}
this.mapedFiles.add(mapedFile);
this.readWriteLock.writeLock().unlock();
}
return mapedFile;
}
return mapedFileLast;
}
这个方法接受2个参数,第一个参数startOffset只有在首次创建MapedFile的时候才会用到,可以理解为我们前面说的fileFromOffset,这个startOffset将绝对首次创建的MapedFile的fileFromOffset是多少,一般来说RMQ里都是以0进行调用这个方法,也就是从0开始。
第二个参数needCreate是如果找不到最后一个MapedFile也就是内部ArrayList类型mapedFiles变量为空的话是否创建,如果为false,效果和getLastMapedFileWithLock就是一样的了,会返回null,否则会经过一个MapedFile创建流程。
首先会优先寻找最后一个MapedFile,所以先判断内部的mapedFiles是不是空的,如果不是空的,赋值给mapedFileLast变量,然后下面创建MapedFile的流程就不会走了,如果是空的,则是第一次创建,用startOffset算出创建MapedFile的fileFromOffset,使其进入到创建MapedFile的流程,这里也还存在一种情况,找到了最后一个MapedFile,但是写满了,这个时候会进入上面代码所示的这个流程里
if (mapedFileLast != null && mapedFileLast.isFull()) {
createOffset = mapedFileLast.getFileFromOffset() + this.mapedFileSize;
}
还记得我们前面说过fileFromOffset是单个MapedFile文件大小叠加的吗?如果MapedFile文件大小是8K,第一个文件名和第二个文件名会是:00000000000000000000和00000000000000008192,就是这样生成的。之后会把累加后的fileFromOffset给createOffset 也会使其进入到创建MapedFile的流程。
最后是创建MapedFile的流程,进入到创建流程必须满足createOffset 不是-1并且needCreate参数必须为true才行,进入创建流程后,会创建2个文件名,本次需要创建的和下一次需要创建的,生成文件名的方法在UtilAll工具类的offset2FileName方法,实现如下
public static String offset2FileName(final long offset) {
final NumberFormat nf = NumberFormat.getInstance();
nf.setMinimumIntegerDigits(20);
nf.setMaximumFractionDigits(0);
nf.setGroupingUsed(false);
return nf.format(offset);
}
如果你在构造MapedFileQueue的时候传入了AllocateMapedFileService ,则每次创建除了本次的MapedFile同时也会帮下一次需要创建的MapedFile也创建了,如果你构造时没给AllocateMapedFileService,MapedFileQueue则会直接构造一个MapedFile,最后在创建流程内返回这个MapedFile,拿到MapedFile对象后你应该知道怎么做了~
3.4总结
这几个类组成了RMQ文件持久化存储的基础,消息的持久化和队列文件的存储都是依靠这几个类去完成的,当然这几个类都是可以单拿出来玩的,所以你可以在单元测试里面测试和使用这几个类来进行调试学习,这里只是暂时说了写入文件的相关源代码实现,下一章我们再说这几个类通过offset读出数据的过程。
我的本职工作是写拍黄片(PHP)的,对Java并不是专业的,所以以上的分析和总结如有误区可以随意拍砖,大家一起进步~
by zhiyanglee | email:[email protected]