本文主要参考李航老师的《统计学习方法》第二章感知机
感知机(perceptron)是一个二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别,取值为+1或-1。感知机模型是神经网络和SVM的基础。
注:下面用到的xi为行向量, ω为列向量
原始感知机
感知机的模型为:
其中,ω称为权值(weight),b称为偏置(bias)。
损失函数为:
对于误分类样本点(xi, yi),损失函数为:L(ω,b ) = -yi ( xi · ω + b ),对其求ω和b的导数为:

故,只要找出误分类点(xi , yi)通过 ω += yi · xiT和 b += yi,即可实现损失函数的减小。
算法的思路为:
- 对权重ω,偏置b进行初始化
- 通过循环语句从训练样本中找出误分类点,若不存在误分类点,模型训练完成
- 通过误分类点更新 ω 和 b,跳转到第2步
以《统计学习方法》上的一个例子进行编码:对训练集( (3,3), 1),( (4,3), 1),( (1,1), 1) 训练感知机。
代码如下:
# 初始化 w=[[0],[0]], b=0
w = np.array([0,0]).reshape(-1,1)
b = 0
def predict(x):
x = x.reshape(1,-1)
v = np.dot(x,w)+b
if(v > 0):return 1
if(v < 0):return -1
if(v==0):return 0
# 设置训练速率为1
eta = 1
# 设置训练集
x = np.array([[3,3], [4,3], [1,1]])
y = np.array([1, 1, -1])
# 设置最多迭代次数为100,避免死循环
for i in range(100):
for j in range(len(y)):
if(predict(x[j])*y[j]<=0):
w += x[j].reshape(-1, 1)*y[j]*eta
b += y[j]*eta
break
else:
# 不存在误分类点,跳出迭代循环
break
print("w =", w.tolist())
print("b =", b)
结果为:
w = [[1], [1]]
b = -3
将上述代码封装成一个原始感知机类:
class originPerceptron:
def __init__(this):
this.w = 0
this.b = 0
# 参数更新一次
def trainOnce(this, x, y, eta):
indexs = np.arange(len(x))
# 为了避免总是拿靠前的数据进行测试,在此处打乱顺序
np.random.shuffle(indexs)
for i in indexs:
if this.predict(x[i])*y[i] <= 0:
this.w += (x[i]*y[i]).reshape(-1,1)*eta
this.b += y[i]*eta
return True
else:
# 没有误分点后,返回false,表示没有更新参数
return False
# x:训练的输入, y:训练的输出, eta:学习速率, times:最多迭代次数
def train(this, x, y, eta, times):
this.w = np.zeros(len(x[0])).reshape(-1,1)
for i in range(times):
if this.trainOnce(x, y, eta)==False:
return
# 获取参数
def getWB(this):
return this.w, this.b
# 预测
def predict(this, xi):
return np.dot(xi, this.w)+this.b
# 设置训练集
x = np.array([[3,3], [4,3], [1,1]])
y = np.array([1, 1, -1])
# 使用原始感知机类
oP = originPerceptron()
oP.train(x, y, 1, 100)
w, b = oP.getWB()
print("w=", w.tolist())
print("b=", b)
由于使用了随机函数,故迭代次数和循环次数并不确定,可以为
w= [[1.0], [1.0]]
b= -3
或者是:
w= [[1.0], [0.0]]
b= -2
或者是:
w= [[2.0], [1.0]]
b= -5
这样,一个原始感知机模型就实现了。
感知机对偶形式
既然原始感知机已经能够实现对数据的二分类,为什么需要感知机的对偶形式 ?
我认为算法的设计主要用于解决两类问题:
- 没有现成算法可以解决的问题,新设计算法可以看成是 功能型算法 ,就是为了解决某个问题而设计;
- 存在解决某个问题的现成算法,但是现成算法的性能不能达到要求,新设计算法可以看成是 性能型算法 ;
而感知机对偶形式就是解决感知机原始形式的性能问题;在原始感知机中,为了找到一个误分类点,我们需要使用for循环遍历,如果我们的样本数量非常大,性能会大大降低,特别是后期,误分类的样本点数量非常少之后,寻找这些误分类点时间会大大增加;
现在考虑,能不能使用矩阵运算一次性求出所有的误分类点,毕竟python的numpy库非常善于矩阵运算;
注:在数学领域中,对偶一般来说是以一对一的方式,把一种概念、公理、数学结构转化为另一种概念、公理、数据结构,如果A的对偶是B,那么B的对偶就是A
在学习率为1的原始感知机中,权重ω的第i个分量 ωi = (yi·xiT)*αi,其中αi为第i个样本点作为误分类点的次数。
例如,我们一共有n个样本点,共进行了N次参数修正,其中使用样本1进行修正α1次,使用样本2进行修正α2次,...,使用样本n进行修正αn次,可知α1 + α2 +...+ αn = N;
ω = α1y1·x1T + α2y2·x2T +...+ αnyn·xnT ,写成矩阵形式为:

因此,一次计算所有样本 xω+b的值可以表示为:

上述公式中 * 表示Hadamard乘积,即两个同型矩阵(或向量)对应元素相乘,形状不变;
Y*XXT在训练前计算一次即可,故每次计算误分类点时的运算量并不大。之后,用sign函数作用于求得的列向量,与真实的标签比较即可获得误分类点,在实际代码中,我们直接用上述公式求得的列向量和标签向量做Hadamard乘积,并判断所得列向量中元素是否大于0得到分类是否正确。
注:XXT 称为Gram矩阵
代码如下:
x = np.array([[3,3], [4,3], [1,1]])
y = np.array([1, 1, -1]).reshape(-1, 1)
b = 0
yGram = y.T*np.dot(x, x.T)
alpha = np.zeros(len(x)).reshape(-1,1)
for i in range(100):
v = np.dot(yGram, alpha)+b
# 获取布尔数组,True为分类正确,False为分类错误
check_right = ((v*y).flatten()>0)
# 没有分类错误,算法结束
if(np.all(check_right)):break
# 获取第一个分类错误的点
error_index = check_right.tolist().index(False)
# 更新alpha、b
alpha[error_index, 0] += 1
b += label[error_index]
# 根据公式求w
w = np.dot(y.T*x.T, alpha)
print("w =", w.tolist())
print("b =", b)
输出为:
w = [[1.0], [1.0]]
b = -3
将对偶感知机也封装成一个类,代码如下:
import random
x = np.array([[3,3], [4,3], [1,1]])
y = np.array([1, 1, -1]).reshape(-1, 1)
class dualPerceptron:
def __init__(this):
this.b = 0
this.w = 0
def train(this, x, y, eta, times):
alpha = np.zeros(len(x)).reshape(-1, 1)
y = y.reshape(-1,1)
yGram = np.dot(x, (x*y).T)
for i in range(times):
# 获取所有分类错误的索引
err = np.arange(len(alpha))[
((np.dot(yGram, alpha)+this.b)*y<=0).flatten()]
if(len(err)==0):
this.w = np.dot((x*y).T,alpha)
return
# 随机选一个分类错误的样本i,其alpha[i]加一
randerr = random.randint(0, len(err)-1)
alpha[err[randerr]] += eta
this.b += y.flatten()[err[randerr]]
else:
# 到达指定的迭代次数,更新权重
this.w = np.dot((x*y).T,alpha)
def predict(this, xi):
v = np.dot(xi, this.w)+this.b
if v>0 :return 1
if v<0 :return -1
if v==0 : return 0
def getWB(this):
return this.w, this.b
# 使用对偶感知机
dP = dualPerceptron()
dP.train(x, y, 1, 100)
w, b = dP.getWB()
print("w =", w.tolist())
print("b =", b)
结果可能为:
w = [[1.0], [0.0]]
b = -2
使用scikit-learn中的感知机进行训练
在scikit-learn库中,存在感知机模型,我们可以直接使用,还是训练上面那个例子:
from sklearn.linear_model import Perceptron
p = Perceptron(max_iter=100, shuffle=False)
p.fit([[3,3],[3,4],[1,1]],[1,1,-1])
print("w =", p.coef_)
print("b =", p.intercept_)
输出为:
w = [[ 1. 1.]]
b = [-3.]
与我们写的非随机的感知机数据结果是完全相同的;
训练数据量更多的数据集
前面的例子中,样本数据非常少,现在,我们使用scikit-learning创建更多数据量的数据集,并进行测试;
创建数据
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 创建1000个样本的数据集
x, y = make_classification(n_samples=1000, n_features=2,
n_redundant=0, n_informative=1,
n_clusters_per_class=1)
x0 = x[y==0]
x1 = x[y==1]
plt.scatter(x0[:,0], x0[:,1], c="m")
plt.scatter(x1[:,0], x1[:,1], c="r")
plt.show()
显示的散点图为:
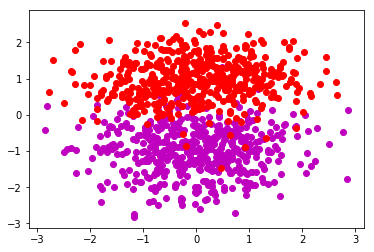
该散点图应该不能用一条直线将不同类的点分开;各位显示的图应该和上图不一样,毕竟是随机产生的;
现在,我们用上面的3中方法进行测试;
使用scikit-learning中的感知机测试
from sklearn.linear_model import Perceptron
clf = Perceptron(fit_intercept=False, max_iter=300, shuffle=False)
clf.fit(x, y)
# 绘制分类情况
plt.scatter(x0[:,0], x0[:,1], c="m")
plt.scatter(x1[:,0], x1[:,1], c="r")
line_p1 = np.linspace(-3,3,1000)
line_p2 = (-clf.intercept_[0]-clf.coef_[0][0]*line_p1)/clf.coef_[0][1]
print(clf.score(x, y))
plt.plot(line_p1, line_p2)
plt.show()
通过感知机类的 score 方法可以计算正确率,打印出来的正确率为 0.92,还是挺不错,打印出的图为:

使用对偶感知机测试
为了能过定量地计算正确率,我们需要定义一个计算正确率的函数:
# perceptron 感知机实例,x输入,y标签
def calcAccurate(perceptron, x, y):
sum_cnt = len(x)
right_cnt = 0
for xi,yi in zip(x, y):
if perceptron.predict(xi)*yi>0:
right_cnt += 1
return right_cnt/sum_cnt
应用类的多态性,对偶感知机和原始感知机都可以用该函数测试正确率;
由于scikit-learning创建的样本标签为0或1,所以我们需要将0的标签改为-1,之后,定义并测试对偶感知机:
dP = dualPerceptron()
# 由于原始数据中,负例标记为0,故先修改标签
ty = y.copy()
ty[y==0]=-1
dP.train(x, ty, 1, 300)
w, b = dP.getWB()
# 绘制分类情况
plt.scatter(x0[:,0], x0[:,1], c="m")
plt.scatter(x1[:,0], x1[:,1], c="r")
line_p1 = np.linspace(-3,3,1000)
line_p2 = (-b-w[0]*line_p1)/w[1]
plt.plot(line_p1, line_p2)
print(calcAccurate(dP, x, ty))
plt.show()
打印出来的正确率为 0.95,比scikit-learning的还高一点点。当然,不能保证每次训练的正确率都高,不过基本上在0.9以上,打印出的图为:

使用原始感知机测试
oP = originPerceptron()
# 由于原始数据中,负例标记为0,故先修改标记
ty = y.copy()
ty[y==0]=-1
oP.train(x, ty, 1, 300)
w, b = oP.getWB()
# 绘制分类情况
plt.scatter(x0[:,0], x0[:,1], c="m")
plt.scatter(x1[:,0], x1[:,1], c="r")
line_p1 = np.linspace(-3,3,1000)
line_p2 = (-b-w[0]*line_p1)/w[1]
plt.plot(line_p1, line_p2)
print(calcAccurate(oP, x, ty))
plt.show()
打印出的正确率为 0.942,也是挺高的;绘制的图为:

其实,上面3个的测试代码长度都不多,非常简洁;
总结
感知机作为基本的训练模型,是很多模型的基础,值得花时间真正掌握。