
王钰
2016 年加入 Qunar,目前在去哪儿网平台事业部前端架构组(YMFE)任前端工程师一职。欢迎访问团队博客YMFE(http://ymfe.tech)查看更多技术...。
不久前我在 YMFE Conf 上分享了关于构建流畅动画相关的内容,这篇文章是我分享内容的文字版,你可以在这里()看到对应的 PPT。
什么是 fps,60fps 意味着什么?
fps(frames per second),指一秒内屏幕刷新的次数或者动画在一秒内更新的帧数。现代浏览器大多每秒刷新 60 次,为了和设备的刷新频率保持一致,动画也要保证每秒 60 更新帧。如果低于 60 fps,称动画发生了掉帧,如果掉帧严重,用户则能够明显地感觉到卡顿。高的帧率,意味着更连贯的动画,更流畅的滚动,这些总是能带来极好的用户体验。
本文首先谈了谈现代浏览器的渲染流程,并结合各个流程谈了一下构建流程动画的技巧和注意事项。
本文的结构如下:
- 从 HTML/CSS 到 Web 页面
- 浏览器在每一帧中要做的工作
- 构建流程动画的技巧和注意事项
从 HTML/CSS 到 Web 页面
要想高效地操作DOM, 完成流畅的动画,需要了解浏览器是如何将 HTML/CSS/Java 等资源渲染为 Web 页面的。下面就此过程进行描述:
浏览器接收到 HTML 文档后就会开始解析文档,并建立 DOM 树 (Document Object Model Tree),DOM 树中记录了当前文档的所有节点。同时浏览器使用内联的 style 标签或者外部加载的 CSS 文档来构建 CSSOM 树(CSS Object Model Tree),CSSOM 树中记录了各个节点的样式规则。随后联合 DOM 树和 CSSOM 树构建出渲染树(Render Tree),渲染树中记录了当前页面中所有可见节点的实际样式。之所以说实际样式,是因为 CSS 中可能出现width: 50%或color: inherit这样的写法,浏览器需要自顶向下地去根据父节点来计算出某个节点的实际样式。
整个步骤,如下图所示:
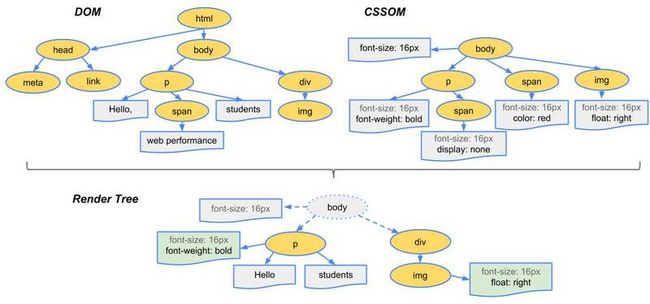
△渲染树的构建过程(图片来自 Chrome developer)
- DOM 树:记录了文档的结构与内容
- CSSOM 树:记录了 DOM 节点的样式规则
- Render 树:表示 DOM 中每个节点真实的样式
得到了渲染树,浏览器还不能开始进行绘制,因为页面上存在太多元素,如果页面中有一个元素被改变,这个时候如果重绘整个页面就显得很浪费,毕竟很多时候只是很小的一部分被改变了。浏览器为了高效地绘制,提出了图层(layer)的概念,按照某些规则将 DOM 节点划分在不同的图层中,这样一个节点的改变,浏览器会智能地去重绘那些受到影响的图层,而非所有图层,浏览器绘制的时候是以图层为单位的。
细分后的过程,大致是这样:
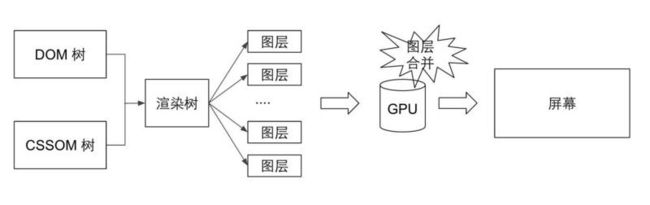
△Web 页面渲染流程
绘制过程就是浏览器调用绘图 API 来完成图层的绘制,绘制过程就是填充像素的过程,浏览器会调用一些类似于moveTo, lineTo 这样的绘图 API,将 各图层绘制出来,得到一些像素点的集合,类似于一张位图(bitmap),这些位图随后被上传至 GPU,GPU 帮助浏览器将这些位图合并起来,得到最终显示在屏幕上的图片。
综上,浏览器渲染出 Web 页面的过程,大体可分为以下几个步骤:
- 解析 HTML/CSS 生成 DOM 树 CSSOM 树
- 联合 DOM 树和 CSSOM 树得到渲染树
- 将 Render 树划分为多个图层,并绘制图层
- 将各图层的数据上传至 GPU
- GPU 合并图层得到最终展示在屏幕上的图片
可以想象浏览器内部实现原本以上论述复杂千万倍,以上也只是从非常宏观的角度去描述了浏览器渲染页面的过程。其中还没牵扯到 Java,不过知道以上这些内容,起码对浏览器的渲染流程有了一个大体的认识。
浏览器在每一帧中要做的工作
Java 通过 API 来修改 DOM 树和 CSSOM 树,CSS 中的 animation 或 transition 都会改变渲染树,每当渲染树被改变后,浏览器都需要重新计算样式,样式计算会涉及多个 DOM 节点,因为有些样式存在继承关系,还有则是相对父节点的。
每一帧中浏览器都可能要进行下列部分或全部步骤:

△每一帧浏览器可能要进行的工作
对上图中的各个步骤进行一个简要的解释说明:
- Java:运行 Java 代码,期间可能会添加 DOM 节点,修改节点的样式等,这会影响 DOM 树和 CSSOM 树,最终影响渲染树。另外 CSS 动画和 CSS 过渡都会修改渲染树。
- Recalculate Style:这个节点会根据 CSS 选择器来计算节点的最终样式。
- Layout:一旦知道了各个节点关联的样式,这儿时候就能计算节点的实际尺寸以及其在屏幕上的位置,因为可能牵扯继承和相对单位,因此一个节点的改变可能会影响多个节点,比如修改了的宽度,下面很多元素都会受到影响。
- Update Layer Tree:Layer Tree 中记录了各个图层之间的层叠关系,这会影响最终谁那些元素在上那些元素在下。
- Paint:填充像素,将图层上的文字、边框、阴影等绘制出来,绘制是基于图层的,绘制需要绘制的图层,最终得到一张位图,其中记录了当前图层的视觉表现。
- Composite Layer:得到图层以后需要将其按照正确的层叠关系合并起来,最终得到一整块需要显示在屏幕上图片。
在 Chrome DevTools 可以清楚地看到这几个步骤:
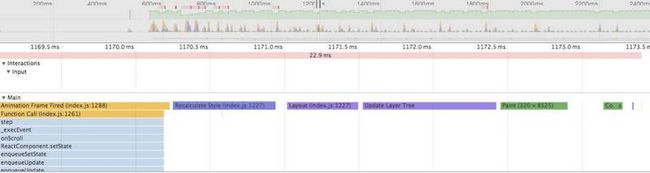
部分步骤可以被跳过
如果修改了一个会影响元素的尺寸或位置的属性,比如 width 和 height 或者 top 等,需要重新进行 Layout 操作,随后会进行重绘,随后将图层合并得到新一帧。这就会执行以上的所有步骤。
但如果只是修改了 color 这样的不涉及节点尺寸或定位的属性,则不需要执行 Layout 这一步骤。因为 color 的修改,并不会影响元素的尺寸和位置,只需要进行一次重绘就好了,此时以上步骤中的 Layout 就被跳过了。

△不需要重排
同样的,如果修改了一个都不需要进行重绘的属性,那么可以跳过 Layout 和 Paint 这两个步骤,此时只需要要进行图层的合并操作就能得到新一帧的图片。

△不需要重排和重绘
不需要进行重排(Layout)和重绘(Paint)操作,自然会耗时更短,每一帧中浏览器需要进行的工作也就越少,一定程度上也就能够提升性能。由此看来对 DOM 树的修改、对 DOM 节点属性或样式的修改,需要付出的代价是不同的,某些操作可能会触发重排和重绘操作,而有些操作则可以完全跳过以上步骤。
规律
不过也可以得出如下的一个规律:
- Layout:涉及到 DOM 操作,DOM 节点的尺寸、位置的属性的修改会触发 layout 进而会导致 repaint(重绘)和图层合并。比如修改 width,margin,border 等样式,或者修改 clientWidth 等属性。
- Paint:涉及 DOM 节点的颜色的属性会导致重绘,比如 color,background,box-shadow 等
- Composite:目前常用的 CSS 属性中,对opacity,transform,filter这三个属性的修改只需要进行 Composite 操作。这几个属性的改变,GPU 只需要在合并图层之前对图层进行一些变换,比如 opacity 属性的改变,GPU 只需要在合并之前改变图层的 alpha 通道。其他两个属性的修改,GPU 也可以直接进行一些矩阵运算得到变换后的图层。
参考资料
paul irish 罗列了那些操作会触发重排,你可以在这里看到:What forces layout / reflow()
另外在https://csstriggers.com/这个...,Chrome 团队的一伙人列出了对 CSS 各属性的修改会引发以上那些操作。
在实践中可以时刻参考这两个列表,并结合调试工具,来避免没有不要的重排和重绘。
构建流程动画的技巧和注意事项
前面介绍了不少关于浏览器渲染过程的基础知识,旨在帮助对此不清楚的朋友从宏观上理清楚 Web 页面的渲染过程。
实现连贯的动画,流畅的滚动,了解以上基础知识对后续编码、优化有着巨大的好处。下面根据浏览器渲染原理,结合每一帧的浏览器需要做的各个步骤,给出了一些切实可行的优化方案,并提出一些注意事项。
后面的内容我想分 5 个点来介绍,分别是:
- 避免没有必要的重排
- 避免没有必要的重绘
- 利用 GPU 加速渲染
- 构建更为流畅的动画
- 正确地处理滚动事件
1 避免没有必要的重排
每个前端工程师在入门的时候,都被告知 DOM 很慢,使用脚本对 DOM 进行操作的代价很昂贵,要批量修改 DOM 等等,关于 DOM 操作的话题已经有不少著作进行过论述了。强烈推荐《高性能 Java》()这本书,我觉得这本书应该是前端工程师必读。
虽说已经有很多关于 DOM 操作的内容了,这里我还是想提一个注意事项:避免强制性同步布局,因为我经常看到这个字眼,不妨提出来谈谈。
避免强制性同步布局
强制性同步布局(forced synchonous layout),发生在使用 Java 改变了 DOM 元素的属性,而后又读取 DOM 元素的属性的时候,通常也说读取了脏 DOM 的时候。比如改变了 DOM 元素的宽度,而后又使用clientWidth 读取 DOM 元素的宽度。这个时候为了获取到 DOM 元素真实的宽度,需要重新计算样式。也就是会重新进行计算样式(Recalculate Style)和计算布局( Layout)操作。
设想以下案例,有一组 DOM 元素,需要将其其高度设为与宽度一致,新手很快就能写出以下代码:
解决方案 1 - 简单粗暴:

执行这段代码的时候,每次迭代开始的时候,DOM 都是脏的(被改动过),为了获得真实的 DOM 尺寸,都会重新计算布局。该循环就会引发多次强制性同步布局,这是很低效的做法,千万要避免。

△引发了强制性同步布局
从 Chrome DevTools 中很容易地发现该低效操作,可以看到浏览器进行了很多次的重新计算样式(Recalculate Style)和布局(Layout),也叫做 reflow(重排)的操作,且这一帧用时很长。
解决方案 2 - 分离读和写:
可以很轻松地解决这个问题,使用两次循环,在第一次循环中读取 DOM 元素宽度并将结果保存起来,在第二个循环中修改 DOM 元素的高度。


△分离读写后
分离读写,一个时刻只读取,另一个时刻只改写,这样就能很有效地避免强制性同步布局。
在实际项目中往往没有上面提到的那样简单,有时尽管已经分离了读和写,但在写操作后面还是不可避免地存在读取操作,这个时候不妨将写操作放在requestAnimationFrame中,浏览器会在下一帧执行这个对 DOM 的改写操作。关于requestAnimationFrame后文有详细的讲解。
补充资料
- 《高性能 Java》- Nicholas C.Zakas ()中讲解了更多关于 DOM 操作的内容,包括如何最小化重绘与重排,如何高效实用 CSS 选择器等。
- What forces layout/reflow(),这个 Gist 中列出了那些操作会导致强制性同步布局。
2 避免没有必要的重绘
在开始之前需要回顾一下什么时候需要重绘:
- 当 DOM 节点的会触发重绘的属性(color,background 等)被修改后,会进行重绘
- 当 DOM 节点所在的图层中其他元素的会触发重绘的属性被修改后,整个层会被重绘
- 图片加载完成后会发生重绘,GIF 图片的每一帧都会发生重绘
在 Chrome DevTools 的 Rendering 选择卡中勾选 Painting Flashing 选项后,可以观察到页面上正在进行重绘的区域。
避免 fixed 定位元素在滚动时重绘
一个常见的场景是,网页有一个 fixed 定位的头部导航栏或者侧边栏。问题存在于每次滚动后,这些 fixed 定位的元素相对于整个内容区域的位置改变了。这就相当于一个图层中的某个元素的位置改变了,为了获得滚动后的图层,需要进行重绘,因此每次滚动都会进行重绘操作。
举个例子,在腾讯网首页上有如下 fixed 定位的元素:
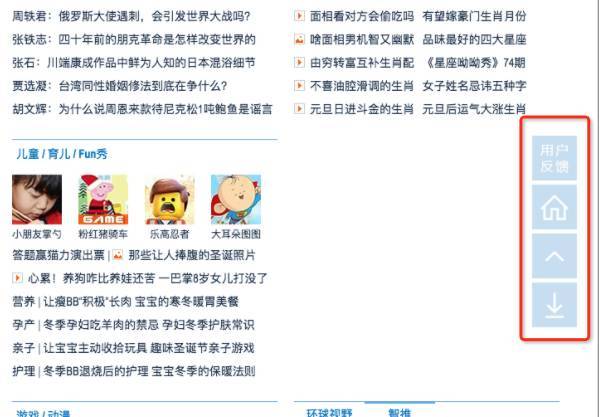
不幸的是这几个 fixed 定位的元素和整个网页位于同一个图层:

滚动后,因为定位元素相对于整个文档的位置发生了改变,因此整个文档都需要被重绘。解决此类问题的方法就是将 fixed 定位的元素提升至单独的图层。使用transform:translateZ(0);这样的写法,可以强制将元素提升至单独图层,关于此后文中还有详细说明。
注:Chrome 在高 dpi 的屏幕上会自动将 fixed 定位的元素提升至单独的图层,在低 dpi 的屏幕上不会提升,因此很多开发者在 MacBook Pro 上测试的时候,不会发现问题,但用户在低 dpi 的屏幕上访问的时候就出问题了。
将部分元素提升至单独图层,避免大面积重绘
使用 transform:translateZ(0); 这样的 CSS hark 写法会将元素提升至单独的图层。在这么做之前要考虑为什么要这样做,创建新的图层的目的应该是,避免某个元素的改变导致大面积重绘,比如某个小标签的颜色的改变,导致大面积重绘,因此将其提升至单独的图层中。
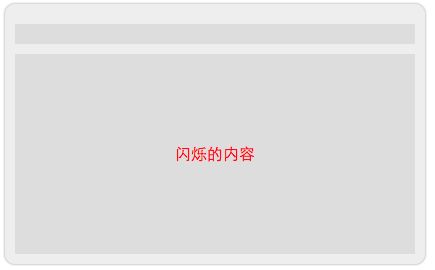
这是一个面板,其中内容区域的文字会不断地闪烁(文本的颜色会改变),如果将该文本使用transform:translateZ(0); 提升至单独的图层,那么文本的颜色改变,就只会导致它所在的图层重绘,而不需要整个面板重绘。这是正确地利用 transform:translateZ(0); 的方式。因此,如果页面中存在小面积的 DOM 节点需要频繁地重绘,可以考虑将其提升至单独的图层中。你可以在这里看到 demo —— 避免大面积重绘()。
正确地处理动图
页面加载的时候为了更好的用户体验常常会使用一个 loading,但在页面加载完成后如何处理 loading 呢?一个错误的方法是将其 z-index 设置一个更小的值,将其隐藏起来,不幸的是就算 loading 不可见,浏览器依然会在每一帧对它进行重绘。因此对于像 loading 这样的动态图,在不需要显示的时候最好使用display:none或者visibility: hidden;来彻底隐藏,或者干脆移除 DOM。
3 利用 GPU 加速网页渲染
前端工程师应该都听说过硬件加速,通常是指利用 GPU 来加速页面的渲染。早期浏览器完全依赖 CPU 来进行页面渲染。现在随着 GPU 的能力增强和普及,且目前绝大多数运行浏览器的设备上都集成了 GPU。浏览器可以利用 GPU 来加速网页渲染。
GPU 包含几百上千个核心,但每个核心的结构都相对简单, GPU 的结构也决定了它适合用来进行大规模并行计算。进行图层合并需要操作大量的像素,这方面 GPU 能比 CPU 更高效的完成。这里有个视频(),很清楚地说明 CPU 与 GPU 的差别。
常常看到有文章指出使用transform:translateZ(0);这样的 hark 可以强制开启硬件加速来提高性能,这是错误的说法。下面就来说说硬件加速的实质。
何为硬件加速
GPU 能够存储一定数量的纹理(texture),也就是一个矩形的像素点集合。通常这个集合会对应到 Web 页面上的某个图层,GPU 能够高效地对这些像素点进行多种变换(位移、旋转、拉伸)操作。在实现动画的时候,利用 GPU 的这一特性,如果只需要对原像素集合在 GPU 内进行一次变换,就能得到新一帧的图层,那么动画的所有操作都在 GPU 内高效地完成了,没有重绘操作。
得到了变换后的图层,只需要再进行一次图层的合并,将该变换后的图层和其他图层合并起来,最终得到在屏幕上显示的整幅图片。GPU 的这一特性就常常被称为硬件加速。
要利用硬件加速也是有条件的,盲目地使用transform:translateZ(0);而不知原理,只会让事情变得更糟糕。硬件加速的本质是说让下一帧的图层在 GPU 内经过变换得来,但是如果某些操作 GPU 无法完成,必须动画修改了 DOM 节点的宽度,颜色等,这依然是需要在 CPU 端进行软件的重绘的,这种情况就无法利用硬件加速的机制。
使用transform:translateZ(0);会强制浏览器创建一个新的层,每创建一个层都需要消耗额外的内存,有太多的层就会消耗大量内存,这会导致设备内存不够用,有可能导致应用奔溃。另外这些图层最后需要上传至 GPU 进行图层合并,太多的层,会导致 GPU 和 CPU 之间的带宽不够用,反而影响性能。
目前常见的 CSS 属性中只有 filter, transform, opacity 这几个属性的改变可以在 GPU 端进行处理,这在前面已经提到过了,因此应该尽可能使用这些属性来完成动画。
后面会有更多关于利用 GPU 的这一特性的例子,下面先看一个需要注意的点:
避免无谓地新建图层
一个真实案例:

△每个列表项都是一个图层
这是一个城市选择页,这个页面中的每一项都使用了 transform:translateZ(0); 强制提升至了单独的图层,滚动列表,并录制了一段 Timeline。
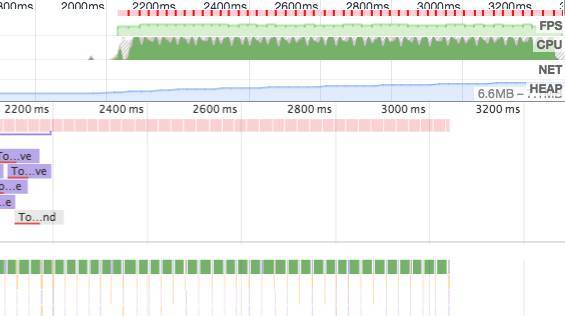
△优化前
从上图中可以看到,性能是相当糟糕的,大量时间都花费在了图层的合并上,每一帧都需要合并上千个列表子项,这不是一件很轻松的事情。
为了体现,错误使用 transform:translateZ(0); 的严重性,下面来看看去掉后的效果,去掉该属性后,一片绿,没有任何性能问题。
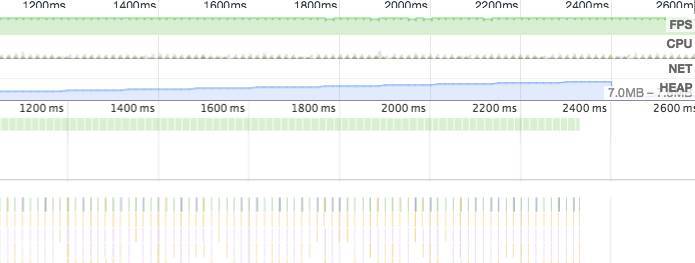
△优化后
因此在谈起硬件加速的时候,一定知道,什么是硬件加速,硬件加速是如何工作的,它能做什么,不能做什么。合理的利用 GPU 才能利用它帮我们构建出 60fps 的体验。
4 构建更加流畅的动画
上面讲了,使用 transform 和 opacity 来创建动画(filter 的支持度还不够好)最为高效。因此每当需要用到动画的时候,首先要考虑使用这两个属性来完成。
避免使用会触发 Layout 的属性来进行动画
有时候看起来不太可能使用这两个属性来完成,不过仔细想想往往能够想到解决方案。考虑下面动画:
demo 地址:expand cord()
一般的想法可能是修改每个卡片的 top, left, width, height 来实现这个功能,这样做当然可以实现效果,只是改变这些属性都会触发 Layout 进而触发 Paint 操作,在复杂应用上势必造成卡顿。下面介绍一种使用 transform 来完成此动画的方法。

以上思路是使用getBoundingClientRect将动画的始态和终态的尺寸和位置计算出来,然后利用 transform 来进行过渡,思路在代码注释中已经进行了说明。
经过这样的处理,原本需要使用top,left,width,height来进行的动画使用transfrom就搞定了,这会大大地提示动画的性能。
使用 transform, filter 和 opacity 来完成动画
使用以上 3 个属性来完成动画,可以避免在动画的每一帧进行重绘。但如果在动画中改变了其他属性,那也不能避免重新绘制。要尽可能地利用这几个属性来完成动画。涉及位移的考虑使用 translate,涉及大小的考虑 scale,涉及颜色的考虑 opacity,为了实现流畅的动画要想尽一切办法。
这里给出一个案例,Instagram 的安卓 APP 在登录的时候,有一个颜色渐变的效果,这种效果常常见到。
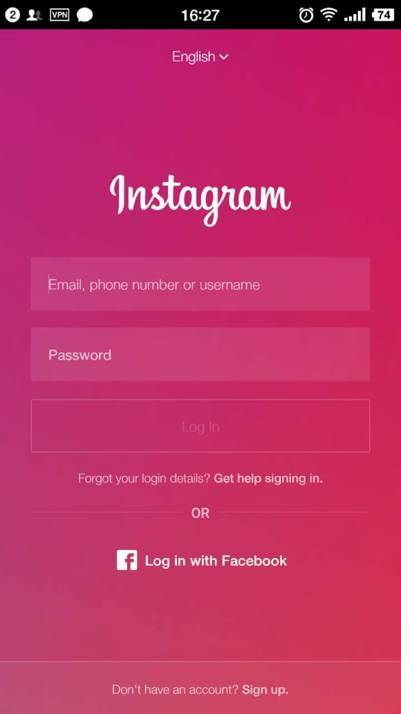
△Instagram 登录页的背景色渐变效果
通过地不断地改变背景颜色能很快地实现,测试后会发现在低端设备上会感到卡顿,CPU 使用率飙升,这是因为修改背景颜色会导致页面重绘。为了不重绘也能达到同样的效果,我们可以使用两个 div,给它们设置两个不同的背景色,在动画中改变两个 div 的透明度,这样两个不同透明度的 div 叠加在一起就能得到一个颜色演变的效果,而整个动画只使用了 opacity 来完成,完全避免了重绘操作。
关于示例,你可以在此处看到: 使用 background 完成渐变 vs 使用 opacity 完成渐变()
不要混用 transform, filter, opacity 和其他可能触发重排或重绘的属性,虽然使用 transform, filter, opacity 来完成动画能够有很好的性能,但是如果在动画中混合使用了其他的会触发重排或重绘的属性,那么依然不能达到高性能。
使用 requestAnimationFrame 来驱动动画
前面提到的动画大多是使用 CSS 动画 和 CSS 过渡 CSS 动画通常是事先定义好的,无法很灵活地控制,某些时候可能需要使用 Java 来驱动动画。新手常常使用 setTimeout 来完成动画,问题在于使用 setTimeout 设置的回调会在主线程空闲的时候才会调用,想象下面场景:
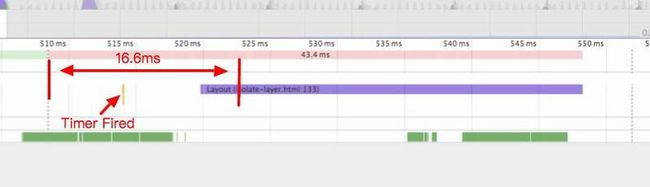
setTimeout在一帧的中间位置被触发,随后导致重新计算样式进而导致一个长帧。setTimeout/setInterval 主要存在以下局限性:
- 在页面不可见的时候依然会调用(耗电)
- 执行频率并不固定(一帧内可能多次触发,造成不必要的重排/重绘)
setTimeout/setInterval 会周期性的调用,及时当前网页并没有在活动。另外因为调用时机不确定可能引发的在同一帧内多次调用同一个回调,如果回调中触发了多次重绘,那么会出现在一帧中重绘多次的情况,这是没有必要的,且会导致掉帧。
而requestAnimationFrame,一个专门用来驱动动画的 API,它有以下好处:
- 保证回调在下一帧调用
- 根据机器的刷新频率调整执行频率
- 当前网页不可见的时候不执行回调
虽然requestAnimationFrame是一个已经存在很多年的 API 了,但是还是存在诸多误读,其中最严重的是认为使用requestAnimationFrame能够避免重新布局和重绘,浏览器能够启动优化措施,让动画更流畅,这是错误的,浏览器能保证的仅仅是以上 3 条,在requestAnimationFrame的回调中进行强制同步布局依然会触发重排。
在编写使用 Java 驱动的动画时,使用requestAnimationFrame可以将对 DOM 的写操作放在下一帧进行,这样该帧后面对 DOM 的读取操作就不会引发强制性同步布局,浏览器只需要在下一帧开始的时候进行一次重排。
5 正确地处理滚动事件
现代浏览器都使用一个单独的线程来处理滚动和输入,这个线程叫做合成线程,它能够和 GPU 进行通信来告诉 GPU 如何移动图层,进行页面的滚动。如果页面上绑定了 touchmove,mousemove 这类事件,合成线程需要等待主线程执行相应的事件监听函数,因为这些函数里面可能会调用 preventDefault 来阻止滚动。
对于优化 scroll,touchmove,mousemove 等事件,其中一个最为重要的建议就是,要控制此类高频事件的回调的执行频率。说到控制频率,自然会想到 debounce 和 throttle 这两个函数。曾一度为止迷惑,不妨简要对这两个函数进行科普:
使用 debounce 或 throttle 控制高频事件触发频率
debounce 和 throttle 是两个相似(但不相同)的用于控制函数在某段事件内的执行频率的技术。
debounce
多次连续的调用,最后只调用一次
想象自己在电梯里面,门将要关上,这个时候另外一个人来了,取消了关门的操作,过了一会儿门又要关上,又来了一个人,再次取消了关门的操作。电梯会一直延迟关门的操作,直到某段时间里没人再来。
throttle
将频繁调用的函数限定在一个给定的调用频率内。它保证某个函数频率再高,也只能在给定的事件内调用一次。比如在滚动的时候要检查当前滚动的位置,来显示或隐藏回到顶部按钮,这个时候可以使用 throttle 来将滚动回调函数限定在每 300ms 执行一次。
需要注意的是这两个函数的使用方法,它们接受一个函数,然后返回一个节流/去抖后的函数,因此下面第二种用法才是正确的

使用 requestAnimationFrame 来触发滚动事件的回调
如果在事件监听函数中进行了 DOM 操作,这可能会消耗不少时间,事件监听函数执行的时间变长,与 GPU 进行通信的合成线程也就迟迟接收不到通知,浏览器也就迟迟不知道如何滚动页面,由此引发的就是卡顿。对于这类同步的事件(浏览器等待事件执行完成),可以在事件触发的时候先读取需要获取的 DOM 元素的尺寸位置等信息,然后将其他改写 DOM 的操作安排在 requestAnimationFrame 中完成,浏览器能够更快地执行完事件回调,还能避免后续的读取 DOM 的时候发生重排。
另外,有时候希望事件在每一帧执行一次,此时是使用 throttle 是无法满足需求的,使用requestAnimationFrame 可以保证每一帧都会调用,需要注意的是有的事件触发的频率可能是一帧好几次。因此在使用 requestAnimationFrame 的时候要注意判断是否在一帧内多次触发了回调。

总结
这两篇文章对浏览器的渲染过程进行了简要描述,然后根据浏览器渲染原理,分析实现流畅的动画需要注意的方方面面,并给出多个实现流畅动画的实用技巧。
不过规则最是不停在改变的,浏览器也不断在更新,一年前是性能瓶颈的点,现在可能已经不是瓶颈了。在开发过程中应该结合调试工具,去分析每一次重排和重绘,分析各个阶段的耗时,找出真正的问题所在。而不是仅仅记住一些条条框框。
欢迎留言交流或投稿,和我们一起分享知识。