一。 windows GPU 版本的 darknet 环境
环境:(基本都是按照github上的要求的来的,之前试过没按照上面的版本来,失败了,不挣扎了~ )
1. VS2015 community 免费的社区版本,这个装在哪个位置随意。
2. CUDA9.1 cudnn7.1 使用默认安装位置(CUDA安装在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1,cudnn解压出来直接覆盖该目录)。CUDA安装过程中黑屏没关系,只是小小的黑一下而已。
3. opencv3.4.0 将opencv-3.4.0-vc14_vc15.exe解压出来,C盘建个名为“opencv_3.0”的目录,然后把解压出来的东西扔进去,目录结构如下(C:\opencv_3.0\opencv\build)
4. darknet windows版本:github路径:https://github.com/AlexeyAB/darknet(下载的时候是2018.10.7)
二。 在VS2015上编译DEMO
1. 打开 darknet-master\build\darknet\darknet.sln 这个是GPU版本的(darknet_no_gpu.sln 这个是CPU版本的,如果只跑前向,用这个完全没问题,如果要训练,还是GPU版本的吧,CPU版本的实在是太慢了!)
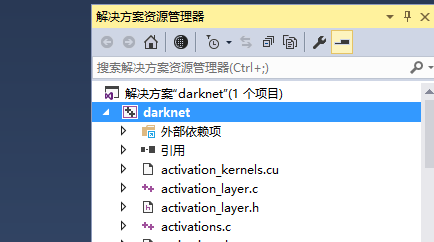
2. 如下图,打开后,右击选中部分,点重新生成,如果是按照我上面的流程安装的环境,应该不要修改配置就能直接使用。darknet-master\build\darknet\x64 中会生成 darknet.exe
三。 训练自己的数据集
1. 搜集训练样本(不使用开源数据集)
使用网络爬虫,爬取样本图片。网络爬虫我几乎是小白,是网上随便找的一个比较快且稳定的爬虫脚本(原版在哪里暂时找不到了,找到了再加上去),总共爬了7W多张,可怕。。。
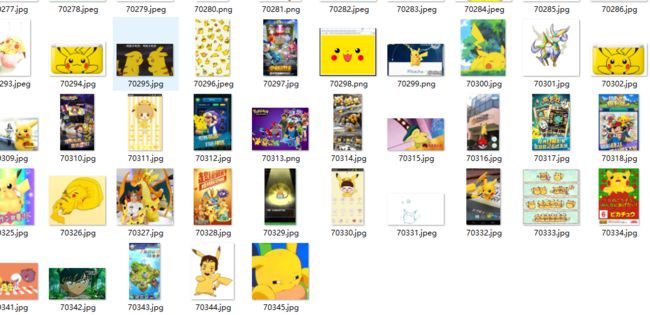
2. 训练的 yolo label 标注
标注工具是基于网上的一个版本改的,基于opencv(http://www.cnblogs.com/louyihang-loves-baiyan/p/4457462.html)。
标样本的时候,取了前1W张图片,然后当标了几百张的时候发现越来越多重复的图片了,最终,我只标了接近1000张图片,实在是懒得标了~!
标注的代码里面会将图片缩放成固定大小,方便我去标。
yolo的label格式是这样的:类别下标(第几个类别,从0开始) 中心点x坐标 中心点y坐标 目标宽度 目标高度 (后面4个值都是实际像素点值除以实际宽高的,也就是占比)

每张图片都对应一个label文件,比如图片名字是1.jpg,那么它的标注文件就是1.txt。
3. 准备训练前的东西
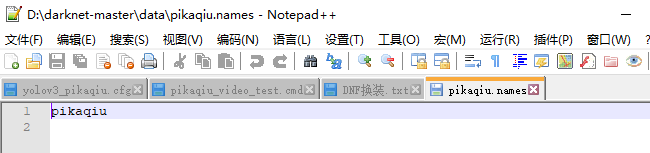
1. 标签名字文件:pikaqiu.names 里面每行存放着标签的名字(该文件一般放在data目录,这里我训练的是皮卡丘检测,所以就一个标签)
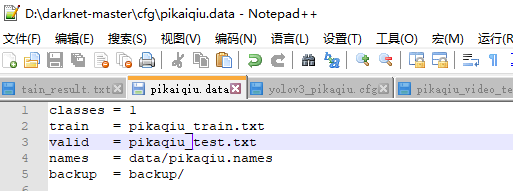
2. data文件(一般放在cfg目录):如图,从上到下分别为类别数量,训练集位置,测试集位置,标签名字文件,模型备份路径
3. 训练集(pikaqiu_train.txt)和测试集(pikaqiu_test.txt )位置文件:存放图片的位置,在当前目录,每张图片都会有对应的label文件:
训练集
图片和对应的label文件
4. 网络配置文件(再cfg/yolov3-voc.cfg的基础上改的):
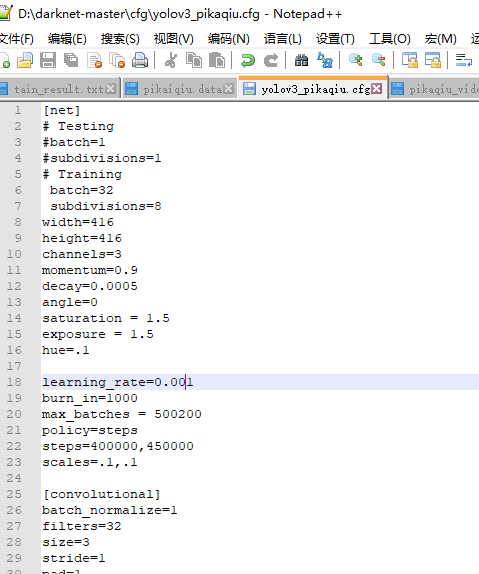
batch:batchSize数,每batch个样本更新一次参数。
subdivisions:如果内存不够大,将batch分割为subdivisions个子batch,每个子batch的大小为batch/subdivisions。在darknet代码中,会将batch/subdivisions命名为batch。
width:网络输入的宽度 height:网络输入的高度 channels:网络输入的通道数
momentum:动量
decay:权重衰减正则项,防止过拟合
angle:通过旋转角度来生成更多训练样本
saturation :通过调整饱和度来生成更多训练样本
exposure :通过调整曝光量来生成更多训练样本
hue:通过调整色调来生成更多训练样本
learning_rate:初始学习率
max_batches:训练达到max_batches后停止学习
policy:调整学习率的policy,有如下policy:CONSTANT, STEP, EXP, POLY, STEPS, SIG, RANDOM
steps:根据batch_num调整学习率
scales:学习率变化的比例,累计相乘

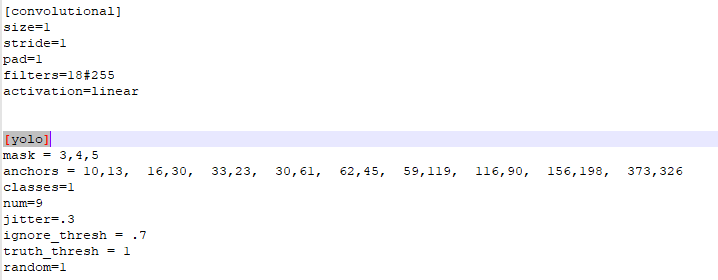
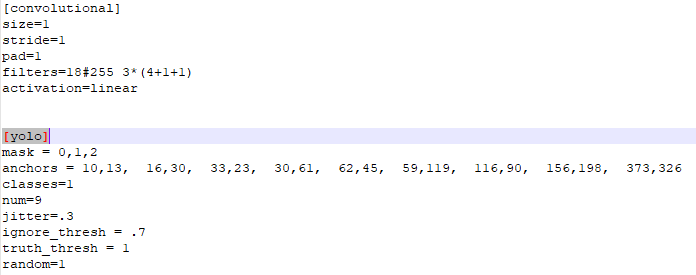
anchors:预选框,可以手工挑选,也可以通过k means 从训练样本中学出
num:预选框的个数,即anchors总数
mask:当前属于第几个预选框
classes:网络需要识别的物体种类数(这里我要训的模型只有一个类别,所以填1)
jitter: 通过抖动增加噪声来抑制过拟合
ignore_thresh:过滤阈值和truth_thresh待研究
random:设置为0,表示关闭多尺度训练(显存小可以设置0)
yolo层前面的卷积层的filters数目是怎么计算的:3x(classes+5),和聚类数目分布有关。如果想修改默认anchors数值,使用k-means即可。
4. 训练及测试
直接从头开始训练(开始loss比较大,慢慢来,会降下去的):build\darknet\x64\darknet.exe detector train .\cfg\pikaiqiu.data .\cfg\yolov3_pikaqiu.cfg
训练的过程中backup目录里面每到一定迭代次数,会有模型参数文件保存下来(比如yolov3_pikaqiu_1000.weights)。
基于前面训练的模型继续训:build\darknet\x64\darknet.exe detector train .\cfg\pikaiqiu.data .\cfg\yolov3_pikaqiu.cfg backup\yolov3_pikaqiu_2500.weights
用生成的模型测试图片:build\darknet\x64\darknet.exe detector test .\cfg\pikaiqiu.data .\cfg\yolov3_pikaqiu.cfg backup\yolov3_pikaqiu_19800.weights
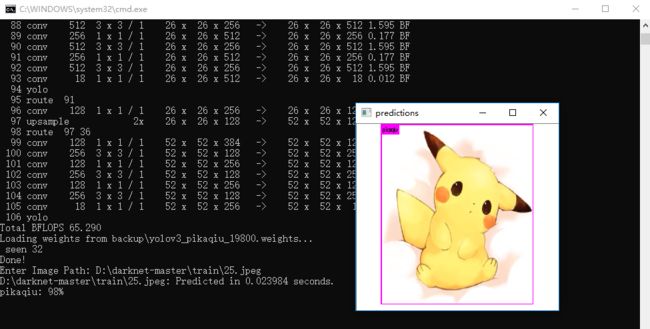
用生成的模型测试视频:build\darknet\x64\darknet.exe detector demo .\cfg\pikaiqiu.data .\cfg\yolov3_pikaqiu.cfg backup\yolov3_pikaqiu_19800.weights -i 0 -thresh 0.25 pikaqiu2.mp4
5. anchors说明:
配置文件里面的9个anchor宽高,实际使用的时候是根据训练的样本,通过k-means算法计算出来的点,上面图片中用的默认的配置点,不是计算的,因为当时做这个的时候我还不懂anchor,哈哈。k-mean的原理说明可以参考:https://blog.csdn.net/hrsstudy/article/details/71173305 ,生成anchor的脚本用的https://github.com/AlexeyAB/darknet/blob/master/scripts/gen_anchors.py 这个脚本,这个脚本用在YOLOV3上有个BUG,write_anchors_to_file函数中anchors[i][0]*=width_in_cfg_file/32.
anchors[i][1]*=height_in_cfg_file/32. 这两行“/32”是不对的,yolov2才这么用,yolov3的anchor值是基于网络输入分辨率的,而不是基于feature map,所以要把 /32 去掉就OK了。
以上所有用到的东西(爬虫脚本spider_baidu_pic.py,label标注代码mark_tool.cpp,opencv, vs2015, cuda9.1 CUDNN7.1, darknet windows 2018.10.7版本,皮卡丘检测所有用到的文件和样本,label, 训练出来的模型)我全部存在了网盘里备份,需要的可以下载试试:
链接:https://pan.baidu.com/s/10h8j5OWbdle-Pm2sopLlKw 密码:olxl
第一次写博客,记录自己的学习过程,备份,强化记忆,写的不好大家见谅。