环境:windows10、virtualBox、centos6.8、hadoop2.6.0、 jdk1.7.0_79、mysql
本文主要分为4大块,分别是virtualbox下centos安装、hadoop安装、hive安装。
virtualbox下centos安装
参见网址:
http://blog.csdn.net/risingsun001/article/details/37934975
特别提醒:
virtualbox安装centos的时候需要设置内存大概为1G左右,否则centos不会显示图形化操作界面。
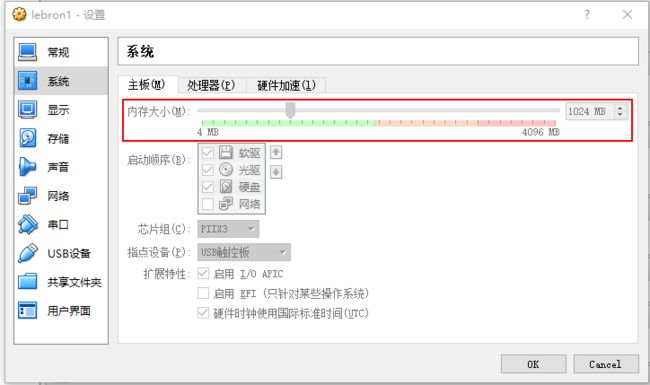
virtualbox啊装centos的时候网络选择桥接模式
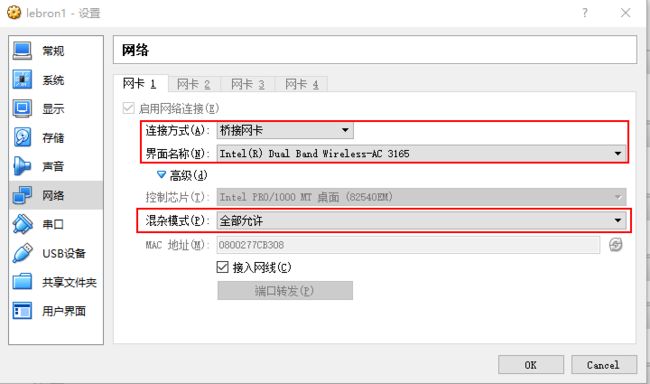
启动centos后需要设置连接网络
centos下hadoop安装
特别提醒:
安装hadoop的需要注意jdk、hadoop的版本,因为这样子网上相同的资料会比较好找,本次安装使用的是hadoop2.6.0、 jdk1.7.0_79。
安装hadoop需要理解下hadoop之间的免密登录的概念,hosts相关的修改等,都是比较细节的内容,但是容易踩坑。
参考文章:
安装介绍:http://www.powerxing.com/install-hadoop-cluster/
安装步骤(好文强力推荐):http://www.cnblogs.com/kevinq/p/5101679.html
免密登录:http://blog.csdn.net/w12345_ww/article/details/51910030
hadoop端口:http://www.cnblogs.com/tnsay/p/5753838.html
机器配置
192.168.0.112 lebron1 作为master
192.168.0.113 lebron2 作为slave
安装jdk
查看已经安装的jdk rpm -qa | grep jdk
卸载已经安装的jdk rpm remove -y xxx
下载jdk安装包 wget http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz
安装jdk 解压jdk-7u79-linux-x64.tar.gz到/opt/jdk1.7.0_79 并配置/etc/profile后执行source /etc/profile
export JAVA_HOME=/opt/jdk1.7.0_79
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=./:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
配置hosts文件
192.168.0.112 lebron1
192.168.0.113 lebron2
建立hadoop账号
新增账号 useradd hadoop
修改密码 passwd hadoop
新增目录 mkdir /usr/local/hadoop
修改权限 chmod 777 –R /usr/local/hadoop
hadoop免密登录
以下为lebron1机器的操作,lebron2机器的操作相同
su hadoop 切换到hadoop账户
ssh-keygen -t rsa 生成密钥文件id_rsa和id_rsa.pub
拷贝lebron1的id_rsa.pub内容到lebron2机器的authorized_keys
su 权限下修改/etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
重启sshd service sshd restart
测试免密连接 ssh lebron1 或 ssh lebron2
安装hadoop
wget http://archive.apache.org/dist/hadoop/core/hadoop-2.6.0/hadoop-2.6.0.tar.gz
解压到hadoop目录 /usr/local/hadoop/hadoop-2.6.0
修改/etc/profile新增hadoop环境变量并执行source /etc/profile使生效
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
解决启动问题:WARN util.NativeCodeLoader: Unable to loadnative-hadoop libraryforyour platform...using builtin-java classes where applicable
wget http://dl.bintray.com/sequenceiq/sequenceiq-bin/:hadoop-native-64-2.6.0.tar
tar -xvf hadoop-native-64-2.6.0.tar -C /usr/local/hadoop/hadoop-2.6.0/lib
tar -xvf hadoop-native-64-2.6.0.tar -C /usr/local/hadoop/hadoop-2.6.0/lib/native
ps:以下操作都在cd /usr/local/hadoop/hadoop-2.6.0/etc/hadoop进行
配置可以参见链接:http://www.cnblogs.com/kevinq/p/5101679.html
修改hadoop-env.sh文件
export JAVA_HOME=/opt/jdk1.7.0_79
修改yarn-env.sh文件
export JAVA_HOME=/opt/jdk1.7.0_79
修改core-site.xml文件
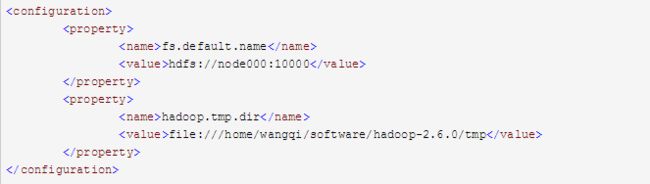
修改hdfs-site.xml文件

修改mapred-site.xml文件

修改yarn-site.xml文件

配置masters和slaves文件
vim slaves 新增slave节点
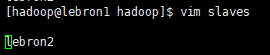
向各节点复制hadoop
将配置的hadoop2.6.0复制到各个节点,建议通过scp命令
格式化namenode
hadoop namenode -format,第一次启动的时候需要执行
启动hadoop和yarn
cd /usr/local/hadoop/hadoop-2.6.0/sbin
./start-all.sh
用jps检验各后台进程是否成功启动
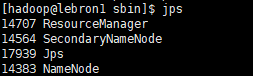
PS:查看日志确认下是否没有报错,如果有报错肯定是某些地方配置没有对,重新网上找资料修复即可,如果完全没有问题可以通过hadoop的shell命令操作检验一下。
hive安装
参见:http://blog.csdn.net/u014591781/article/details/52895176