1. 缓存优缺点
缓存常用的结构如下:
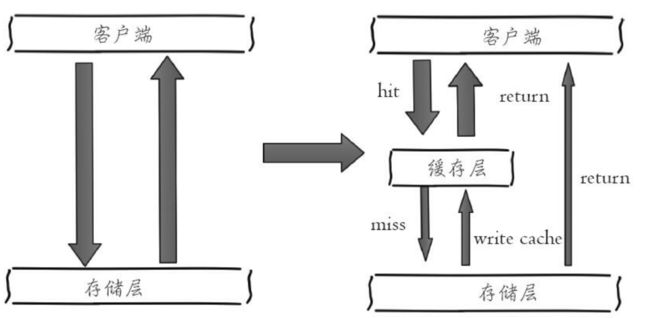
1.1. 优点
加速读写:由于数据库读写速度慢,而基于内存的读写速度快,所以使用缓存可以加速读写,优化用户体验
降低后端负载:帮助后端减少访问量和复杂计算,从而降低了后端的负载。
1.2 缺点
数据不一致:缓存层和存储层可能存在数据不一致的问题,具体何时一致和同步更新策略有关。
代码维护成本增加:要同时维护缓存层和存储层
运维成本增加
2. 缓存更新策略
2.1 LRU/LFU/FIFO算法剔除
剔除算法通常用于缓存超过预设的最大值的时候,如何对现有的数据进行剔除。redis使用maxmemory-policy这个配置作为内存超过预设的最大值后对于数据的剔除策略。
2.2 超时剔除
通过给缓存数据设置过期时间,让其在过期时间后自动删除,如expire命令。
2.3 主动更新
真实数据更新后,立即更新缓存数据。
3. 缓存粒度控制
以使用redis+mysql为例:
首先从数据库中获取用户信息:
select * from user where id={id}
然后再将数据保存到redis中:
set user 'select * from user where id={id}'
这样表中的全部列的信息都保存到缓存中了,但是如果想保存部分列呢:
set user 'select id,name... from user where id={id}'
如果列很多的时候,这样一一列举就不太方便,导致代码可维护性增加。
缓存全部和缓存部分对比如下,使用时要自行取舍:
- 缓存全部:通用性高,占用空间大,代码维护简单
- 缓存部分:通用性低,占用空间小,代码维护复杂
4. 缓存穿透
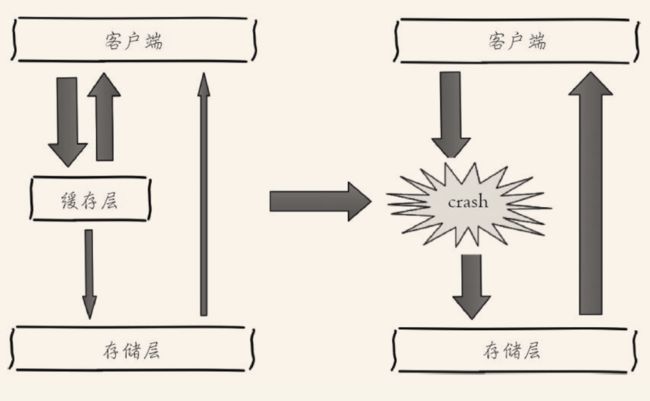
通常情况下,处于容错的考虑,根据key先去缓存层查询,如果缓存查不到,再去数据查询。如果数据库也查不到数据则不写入缓存层。图示如下:
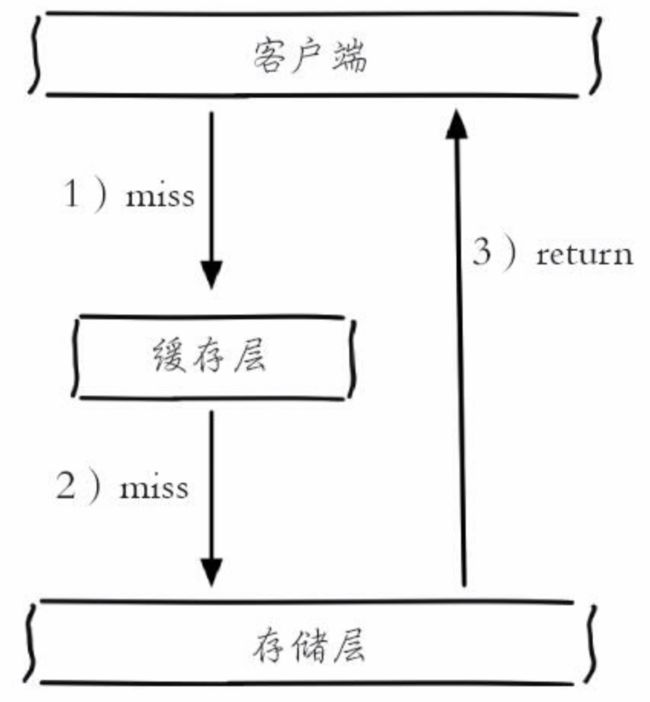
如果一些恶意攻击对很多此类缓存和存储层都没有的值进行查询,就会导致缓存层没有起到保护存储层的效果,大量请求加大数据库负载,从而导致宕机,这就是缓存穿透的后果。
4.1 优化
为解决上述缓存穿透问题,可以使用下述方法进行优化。
4.1.1 缓存空对象
当数据库查不到数据时,仍将空对象保存到缓存中。之后再访问这个数据时,就会先去访问缓存,这样就起到了保护数据库的作用。
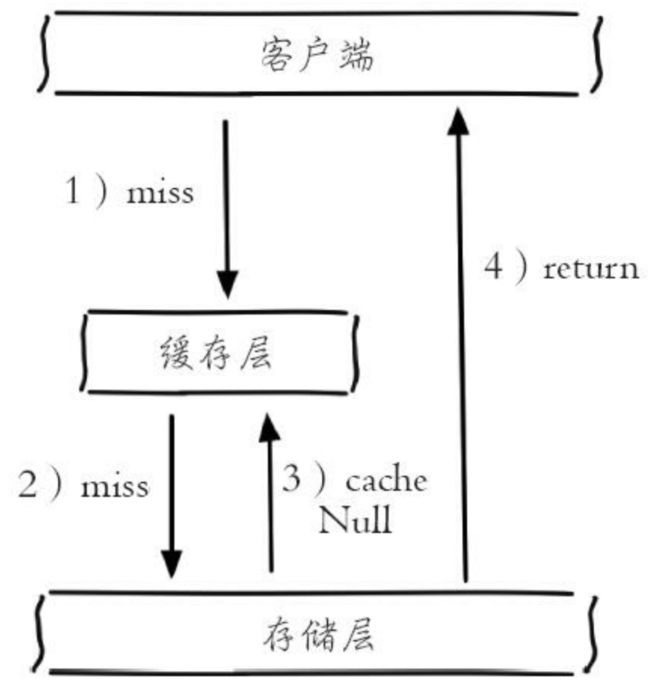
缓存空对象有如下问题:
- 如果这些空对象很多的时候,也会占用过多的redis存储空间,导致缓存的压力加大,比较有效的方法是,设置一个较短的过期时间,让其自动剔除。
4.1.2 布隆过滤器拦截
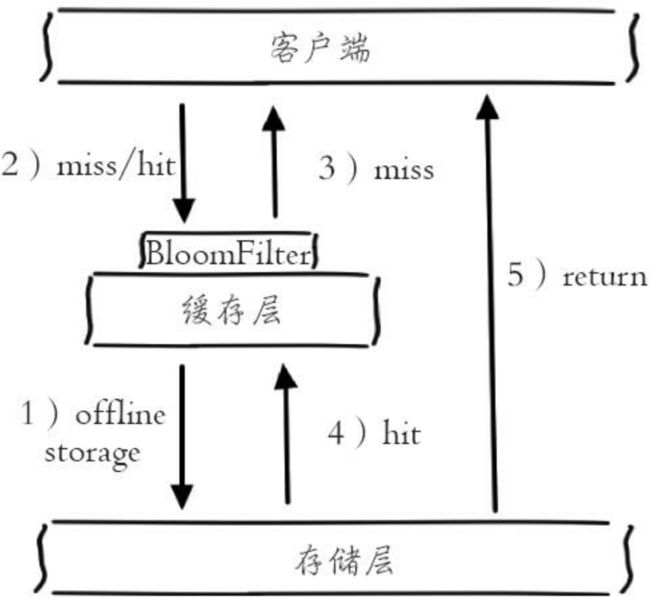
将可能出现的缓存key的组合方式的所有数值以hash形式存储在一个很大的bitmap中<布隆过滤器>(需要考虑如何将这个可能出现的数据的hash值之后同步到bitmap中, eg. 后端每次新增一个可能的组合就同步一次),一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
布隆过滤器类似于将一个key通过n个不同的hash函数定位成n个整数,然后将这n个整数定位在一个长度在M的初始数值为0的数组下标上,设置该n个下标的数值为1。 那只要当查询过来,用这n个hash函数定位判定都为1那基本就存在,只要有任一下标的数组值不是1,则代表不存在。
5. 雪崩优化
下面描述了什么是缓存雪崩:由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。缓存雪崩的英文原意是stampeding herd(奔逃的野牛),指的是缓存层宕掉后,流量会像奔逃的野牛一样,打向后端存储。
预防和解决缓存雪崩问题,可以从以下三个方面进行着手。
1)保证缓存层服务高可用性 。和飞机都有多个引擎一样,如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如前面介绍过的Redis Sentinel和Redis Cluster都实现了高可用。
2)依赖隔离组件为后端限流并降级 。无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞(hang)在这个资源上,造成整个系统不可用。降级机制在高并发系统中是非常普遍的,如Java依赖隔离工具Hystrix。
3)提前演练 。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
6. 缓存击穿
开发人员通常使用“缓存+过期时间”的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是如果当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大,那这个key正好到了过期时间失效了,导致众多请求都获取不到这个原保存到缓存中的key,从而全部去请求数据库了,但是执行数据库可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等,就会瞬间增大数据库的压力,引起数据库服务器宕机,这就是缓存击穿。
解决方案如下。
6.1 互斥锁
当缓存中没有数据的时候会去访问数据并重写到缓存,这个过程可称其为重建缓存。
此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,示例代码如下:
String get(String key){
String value = redis.get(key);
if(value == null){
String mutexKey = "mutex:key:"+key; // 设置作为上锁的key
if(redis.set(mutexKey,"1","ex 180","nx")){ // 使用setnx上锁
value = db.get(key); // 从数据库中获取
redis.setex(key,timeout,value); // 重建该key的缓存
redis.delete(mutexKey); // 解锁
} else {
Thread.sleep(50);
get(key);
}
}
return value;
}
1)从Redis获取数据,如果值不为空,则直接返回值;否则执行下面的2.1)和2.2)步骤。
2.1)如果set(nx和ex)结果为true,说明此时没有其他线程重建缓存,那么当前线程执行缓存构建逻辑。
2.2)如果set(nx和ex)结果为false,说明此时已经有其他线程正在执行构建缓存的工作,那么当前线程将休息指定时间(这里为50毫秒,取决于构建缓存的速度)后,重新执行函数,直到获取到数据。
使用互斥锁存在的问题就是通过加锁阻塞其他调用方的方式,可能会存在死锁和线程阻塞的风险。
6.2 永远不过期
“永远不过期”包含两层意思:
从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
-
从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存(相当于不使用redis的过期功能,而是自己实现过期判断逻辑)。
示例代码如下:
String get(final String key){ V v = redis.get(key); String value = v.getValue(); long logicTimeout = v.getLogicTimeout();// 自定义逻辑超时时间 if(logicTimeout<=System.currentTimeMillis()){ String mutexKey = "mutex:key:"+key; // 设置作为上锁的key if(redis.set(mutexKey,"1","ex 180","nx")){ // 使用setnx上锁 threadPool.execute(new Runnable(){ public void run(){ String dbValue = db.get(key); // 从数据库中获取 redis.set(key,(dbValue,newLogicTimeout)); // 重建该key的缓存 redis.delete(mutexKey); // 解锁 } }); } } }上述实现有一个问题就是在单独创建线程重新构建缓存的过程中,如果有其他服务去获取缓存中的该值就会取到旧值,即出现短暂数据不一致的问题。