文章转自我个人博客
本文前半部分对照 Proguard 文档 (Manul 中的 Introduce 部分)进行翻译同时加上个人的理解,如果有与原文不同,请以原文为主。后半部分是对几个步骤的验证。
介绍
混淆器(ProGuard)会对 Java class 文件进行 shrinker(压缩),optimizer(优化),obfuscator(混淆)以及preverifier(校验)。shrinker(压缩)这一步会找到并移除没用到的类,变量,方法,属性。optimization(优化)这一步,会分析并且优化方法的字节码。obfuscation(混淆)则会对 class,fields,methods替换成一些短的无意义的名字。第一步会把代码量变小,运行更加有效率,同时更加难以被逆向。在 Java Micro Edition 和 Java 6或者更高版本中,最后一步的检验过程,会向class文件中添加一些预校验的信息。
上述的每个步骤,都是可以选择的(可以进行也可以不进行)。例如,ProGuard 可以只进行preverify,从而更高效的运行。
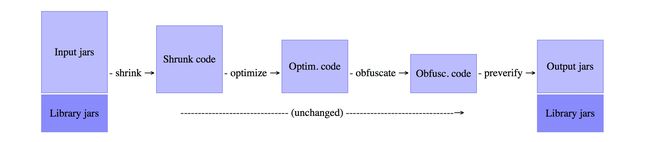
- 首先,ProGuard(混淆器) 读入输入的 jars (也可以是 aars, wars, ears, zips, apks, 或者目录)。随后,开始进行 shrinker(压缩),optimizer(优化),obfuscator(混淆)以及preverifier(校验)。你可以选择性的让ProGuard(混淆器)进行多种类型的优化操作。ProGuard(混淆器)会把修改过的结果写入一个或者多个输出的 jars (也可以是 aars, wars, ears, zips, apks, 或者目录)中。
- 混淆器需要明确输入文件(Input jars)是jars包(也可以是 aars, wars, ears, zips, apks, 或者目录)。这些 libraries 本质上是你将会用来编译的代码。混淆器为了能够正确进行整个过程,会重新构建类之间的依赖。而依赖包(Library jars) 往往是不会被改变的,但你依旧需要把它们放在最终的App的环境中。
Entry points(入口点)
- 在压缩步骤(shrinker),混淆器会从这些点(入口点)进入,并且递归寻找决定哪些类和哪些类成员会被使用。所有的其他类和类成员都会被抛弃掉
- 在优化步骤(optimizer),混淆器会进一步优化代码。在这些优化过程中,那些不是入口点的类和方法会变成private static或者final,不被用到的参数会被移除,一些方法会变成内敛方法
- 在混淆这一步(obfuscator),混淆器会重新命名那些不是入口点的类和类的成员。在这整个过程中,那些成为入口点的地方,依旧会为他们保留原来的名字
- 预验证阶段(preverifier)是唯一一个不需要知道入口点的阶段
反射
- 对于反射和introspection 进行代码的自动处理时,都会存在一些特殊的问题。在混淆器进行处理时,代码中类和类成员都是被动态创建或者被动态调用的(通过对应类的名字,或者成员名字),这些地方都必须被定义成入口点。例如,
Class.forName()这个构造器会在运行时指向任何的类。又比如,类的名字可能会从配置文件中读入,这通常很难去计算出是那些类需要被保留(通过原始的名字)。因此,你必须得在混淆器的配置中,通过简单相同的操作-keep来指定他们。
然而,混淆器已经能够帮你发现并处理以下的情况:
Class.forName("SomeClass")
SomeClass.class
SomeClass.class.getField("someField")
SomeClass.class.getDeclaredField("someField")
SomeClass.class.getMethod("someMethod", new Class[] {})
SomeClass.class.getMethod("someMethod", new Class[] { A.class })
SomeClass.class.getMethod("someMethod", new Class[] { A.class, B.class })
SomeClass.class.getDeclaredMethod("someMethod", new Class[] {})
SomeClass.class.getDeclaredMethod("someMethod", new Class[] { A.class })
SomeClass.class.getDeclaredMethod("someMethod", new Class[] { A.class, B.class })
AtomicIntegerFieldUpdater.newUpdater(SomeClass.class, "someField")
AtomicLongFieldUpdater.newUpdater(SomeClass.class, "someField")
AtomicReferenceFieldUpdater.newUpdater(SomeClass.class, SomeType.class, "someField")
- 类和类成员的名字会不一样,但是构造方法必然是相同的,由此,混淆器能够认出他们。被引用的类和类的成员在压缩(shrinking)阶段会被保留,同时,string 类型的参数也会在混淆时(obfuscation)被准确的修改。
- 除此之外,混淆器会提供一些建议:是否保留一些出现的类和类成员。举例,混淆器会标记
(SomeClass)Class.forName(variable).newInstance()这样的构造器。因为这些方法可能会指向其他类,这些可能是类,也可能是接口,或者是继承自这些接口或者类的类。你需要在配置中做相应的处理。 - 为了能够得到正确的混淆结果,你应该对进行混淆的代码多少有所熟悉。当面临大量反射代码时,混淆代码需要进行大量的试验,并处理错误,特别是对于内部代码没有足够的信息的情况下
以上是对官方文档首页的翻译内容
具体的验证
该部分不是翻译内容,是根据ProGuard 的使用方法和文档首页,对上述三个步骤的具体验证。
由于大部分情况下,Android的混淆只需要考虑Obfuse这个步骤,因为很多第三方依赖包的混淆规则会把 shrink和optimize去掉(比如友盟)。所以先验证这一步。
下面的验证步骤,涉及三个类,java打包的命令(Java 环境),proguard.jar包(混淆器,进行整个混淆过程的jar包),proguard.pro文件(写入具体混淆的规则)和Intelij(用来查看class文件)等内容。
Obfuse 步骤验证
这个步骤,如上所说,主要是对类,方法进行名字的修改,也是 Android 混淆中最重要的部分。为了验证这个过程,我做了下面的demo操作
- 首先写了3个类:
package com.dove.home;
class HelloWorld {
public HelloWorld(){
System.out.println("Hello World");
}
}
package com.dove.home;
class HelloWorld2 {
public HelloWorld2(){
System.out.println("Hello World2");
}
}
package com.dove.home;
class Main {
public static void main(String[] args) {
HelloWorld helloWorld = new HelloWorld();
}
}
- 然后编译,打包
javac com/dove/home/Main.java
javac com/dove/home/HelloWorld2.java
javac com/dove/home/HelloWorld.java
//注意在进行下面步骤的时候,我把 com/dove/home 下的 java源码删了
jar -cvf main_source.jar com

- 然后使用混淆器,混淆器其具体使用方法,主要是调用
proguard.jar包,然后配置proguard.pro文件进行具体的参数设置。
下面是我proguard.pro文件内容
# 源码文件
-injars main_source.jar
# 混淆后输出文件
-outjars main_source_out.jar
# java 核心 jar 不能混淆
-libraryjars /lib/rt.jar
-libraryjars /lib/jce.jar
# 全部不混淆,即三个class文件都会保持原样
-keep class com.dove.home.Main{*;}
-keep class com.dove.home.HelloWorld{*;}
-keep class com.dove.home.HelloWorld2{*;}
具体的混淆命令,同时参考下图(该步骤会生成混淆后的jar包)
java -jar proguard.jar @proguard.pro
注意:然后修改 proguard.pro 文件,内容如下
-injars main_source.jar
# 注意输出包的名字改了
-outjars main_source_proguard_out.jar
-libraryjars /lib/rt.jar
-libraryjars /lib/jce.jar
-keep class com.dove.home.Main{*;}
# 删除了HelloWorld的 keep
-keep class com.dove.home.HelloWorld2{*;}
同样运行上面的混淆命令,生成另一个混淆后的包
最后对三个包进行对比,通过代码逆向,进行验证,最快的方式是把生成的 jar 包,当做第三方依赖包直接导入Intellij 中(有decode的功能),如下图,三个包的区别
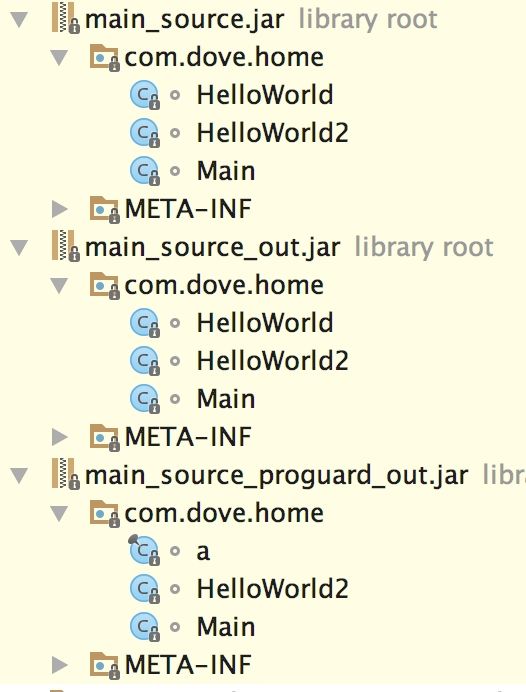
最初是的源码包和保留HelloWorld,HelloWorld2以及Main入口点的包是一样的,不同的是最后没有保留HelloWorld入口点的包,它的HelloWorld变成了a,而Main和HelloWorld2都正常没有被修改
Optimize 步骤验证
同样,修改 proguard.pro 文件,内容如下,然后运行混淆命令,生成新的 jar 包
-injars main_source.jar
# 输出包名改了,方便对比
-outjars main_source_proguard_not_optimize_out.jar
-libraryjars /lib/rt.jar
-libraryjars /lib/jce.jar
# 加上不进行优化的限制
-dontoptimize
-keep class com.dove.home.Main{*;}
-keep class com.dove.home.HelloWorld2{*;}
同上,导入IntelliJ,对比上一步中混淆后的 jar 包,发现名字没啥变化,但内容不一样了

首先是没有添加 -dontoptimize
package com.dove.home;
final class a {
public a() {
System.out.println("Hello World");
}
}
然后是添加了 -dontoptimize
package com.dove.home;
class a {
public a() {
System.out.println("Hello World");
}
}
如上述译文中所说,optimize 会进行代码优化,不是入口点的代码,会变成final,private等等,该步骤验证完毕。
Shrink 步骤验证
修改 proguard.pro 文件,进行压缩,同时不对 HelloWorld,HelloWorld2进行入口点的保留
-injars main_source.jar
-outjars main_source_proguard_shrink_out.jar
-libraryjars /lib/rt.jar
-libraryjars /lib/jce.jar
-keep class com.dove.home.Main{*;}
# 注意对比之前,删除了HelloWorld和HelloWorld2的 keep
修改 proguard.pro 文件,不进行压缩,同样不对 HelloWorld,HelloWorld2进行入口点的保留
-injars main_source.jar
-outjars main_source_proguard_not_shrink_out.jar
-libraryjars /lib/rt.jar
-libraryjars /lib/jce.jar
# 添加不进行压缩
-dontshrink
-keep class com.dove.home.Main{*;}
其结果对比
添加了 -dontshrink标志

未添加 -dontshrink标志

此处消失的b其实就是HelloWorld2,而留下的a则是HelloWorld,原因很简单,因为Main里面持有了HelloWorld的引用,而HelloWorld2则从未被用到,所以就被抛弃了。
由此验证,shrink阶段,Proguard(混淆器)会把无用类文件等删除,一些被动态获取的类就需要注意了,需要进行-keep操作,使其成为入口点。
以上就是对混淆整个过程的验证
对于 Android 混淆,一些需要注意的东西,会在下一篇文章中记录