接着上一篇的内容,我们继续来梳理分布式系统之中的副本机制与副本一致。上文我们聊到了在可用性与一致性之间的一个折中的一致性等级:最终一致性。我们顺着上篇的内容,由用户来分析一致性等级。
1. 客户端的困扰
上篇文章我们提到了数据系统常用的模型,当提交新数据时,必须将它发送给Leader节点,但是当用户查询数据时,可以从一个Follower节点读取该数据。
这样的模型使十分适合Web应用的读多写少的特点。
读写一致性
但是倘若Leader与Follower之间以异步的方式复制的话,会存在一些问题。如下图所示:如果用户数据刚刚写入,而新的数据可能尚未达到Follower节点的副本。在用户的角度,他们提交的数据看起来似乎丢失了。

在这种情况下,我们需要读写一致性。对于用户来说,总是能看到它们最新更新的数据。而其他用户的更新可能需要一定的时间之后才可见。现在新的问题来了,我们如何实现Leader-Follower机制下的读写一致性呢?
这里有一个最简单粗暴的规则是:用户可以选择总是从Leader节点那里读取自己写入的数据,然后选择自从Follower节点处读取其他用户写入的数据。(注:这里的技巧十分巧妙,十分适合在多用户下的隔离,但是仅仅适用于每个用户都仅仅修改自己数据的场景。)
所以更好的方式是时间戳机制,客户端可以通过记录最近一次写入的时间戳,然后数据系统需要确保为该用户提供的任何读取的副本至少在该时间戳之后更新。如果一个副本还没有达到最新的时间戳,则该读取需要由另一个副本处理,或者等待可本节点的副本跟进到满足要求的时间戳。时间戳可以是逻辑时间戳(表示写入顺序的命令,如日志序列号)或实际系统时钟(强依赖系统时钟的话,需要处理时钟回拨等问题,十分麻烦~~~)。
单调读一致性
解决了读写一致性,我们再来看看下面的这个场景:
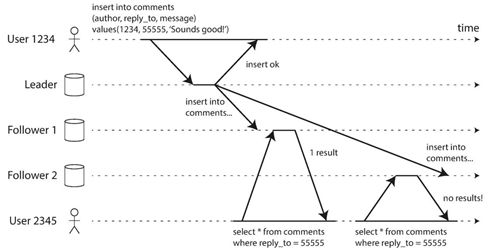
因为用户可以从多个不同的副本进行多次读取,则可能发生这种情况。如上图所示,用户2345进行了两次相同的查询,第一次访问了Follower1节点,第二次查询访问了Follower2节点。第一次查询返回一个最近由用户1234添加的注释,但是第二次查询并没有上次查询的注释了,因为滞后的Follower还没有同步到之前的写入注释的操作。如果用户2345第一次看到用户1234的注释出现,然后再次查询它时却消失了,这对用户2345来说是非常令人困惑的。
单调读一致性来是保证这种异常不会发送。当客户读到的数据,保证不会看到一个旧的数据。要满足单调读一致性。实现单调读取的一种方法是确保每个用户总是从同一副本中读取(不同的用户可以从不同的副本读取)。例如,可以根据用户ID散列选择副本,而不是随机选择。
多数据中心下的交叉设备读:
在多个数据中心的环境下,问题会变的更加复杂。任何需要由Leader节点服务的请求都必须路由转发到包含Leader的数据中心。当同一用户从多个设备访问服务时,另一个复杂的问题出现了,例如桌面Web浏览器和移动应用程序。在这种情况下,您可能希望在读写一致性的基础之上提供交叉设备读:如果用户输入某个设备上的一些信息,然后在另一个设备上查看,则应该看到他们刚刚输入的信息。如果需要提供交叉设备读,记录用户上次更新的时间戳是十分困难的,因为一个设备不知道其他设备上发生了什么更新。假如你的副本分布在不同的数据中心,也不能保证不同设备的连接将被路由引导到同一数据中心。
小结:当使用一个最终一致性的数据系统时,如果复制延迟增加到几分钟甚至几小时,就需要考虑应用程序的行为。如果答案是“没有问题”,那太好了。但如果应用程序对一致性敏感,则应用程序需要提供额外的处理逻辑来处理特殊的场景,如对某些特殊的读取操作,可以限定只对Leader节点执行某些类型的读取。但是,在应用程序代码中处理这些问题会很复杂,很容易出错。事务确保了许多一致性模型,使应用程序更简单。然而,在向分布式的环境之中,许多数据系统放弃了对事务的支持,因为事务会大大降低分布式环境之中系统的性能与可用性。所以,最终一致性能够使用的场景有限,我们还是要按需选择,避免踩坑。
2. 多Leader机制
在多数据中心的环境下,如果仅仅只有一个Leader,所以每次写操作都必须访问同一个数据中心,这将会导致延迟大大提高。所以我们可以考虑多Leader的机制。在多Leader机制可以在每个数据中心中设置一个Leader。下图展示了多Leader机制的结构:

在数据中心内部,保持前文提到的Leader-Follower机制。而跨数据中心的Leader之间通过冲突协调进行数据同步。我们来梳理一下多Leader机制的一些特点
- 性能
在多Leader机制中,每个写操作可以在本地数据中心进行处理,再异步复制到其他的数据中心。因此可以大大降低跨数据中心的网络延迟,性能表现显然会更好。
- Leader失效
在单Leader的机制里,如果数据中心失效,则故障转移可以使另一个数据中心中的Follower成为Leader。而多Leader机制,每个数据中心可以独立于其他数据中心继续运行。
- 网络的延迟与故障
数据中心之间的通信通常依托于公共互联网,它相比数据中心内的本地网络更加不可靠。显然具有异步复制特性的多Leader机制可以更好地容忍跨数据中心通信的延迟与故障。
写冲突
虽然多Leader机制具备了很多优势,它也有一个大缺点是:相同的数据可以在两个不同的数据中心,一旦数据同时被修改就必须要有机制来解决写冲突的问题。如下图所示,考虑一个同时由两个用户编辑的wiki页面。User1将页面标题从A改为B,User2同时将标题从A改为C。每个用户的更改都分别成功提交给了Leader1与Leader2。当进行异步复制时,系统会检测到冲突:

在一个单Leader的数据系统之中,User2要么阻塞,等待第一次写入完成,要么中止第二个写事务,迫使User2重试写入。而在多Leader机制之中,两个写入操作都是成功的,并且冲突只是在稍后的某个时间点异步检测到的。有什么办法可以解决这样的问题呢?
- 避免冲突
避免冲突:如果应用程序可以确保某个特定记录的所有写入都由同一个Leader处理,那么冲突就不会发生。由于多Leader机制处理冲突十分复杂,避免冲突是经常推荐的方法。(在用户可以编辑自己的数据的应用程序中,可以确保特定用户的请求总是路由到同一个数据中心,并使用该数据中心中的Leader处理读写请求。不过这只是一种鸵鸟策略,用户地理位置的转移,或者是路由系统的更新,冲突协调仍然不可避免。)
收敛到一致状态
在单Leader的机制中:如果对同一个字段有多个更新,最后一个写入确定字段的最终值。。而在多Leader的机制中,没有定义的写入顺序,因此不清楚最终值应该是什么。所以数据系统必须以收敛的方式解决冲突,这意味着当所有更改都被复制时,所有副本必须到达相同的最终值。可以为每个写操作分配一个唯一的ID(例如,一个时间戳,一个长的随机数,一个UUID或散列的键和值),最高的ID值认为是最终值,这种技术被称为Last Write Win(LWW)。(强依赖系统时间又会造成很多问题,唉,这真的很烦)自定义冲突消解的逻辑
最合适的解决冲突的方法可能取决于应用程序,该代码可以在写或读时执行:一旦数据系统检测到复制更改日志中的冲突,它就调用冲突处理程序。或是在应用程序读取的阶段检测到冲突时,会将这些数据的多个版本将返回应用程序。应用程序可以提示用户或自动解决冲突,并将结果写入数据库。(Cassandra与CouchDB就是采取了这种机制)
多Leader机制的复制拓扑
两个Leader进行同步时,拓扑结构十分简单。但是一旦扩展到4,5个Leader,之后多个Leader之间的同步结构又应该是怎么样的呢?(虽然在实践中,很少采用这样的架构)
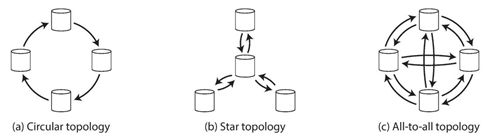
最一般的拓扑结构是图(c),其中每个节点都将其写入传递给所有的节点。而(a)或(b)采用了环形或星型的结构来减少网络的流量。在环形和星形拓扑中,在到达所有副本之前,写入可能需要经过几个节点。因此,节点需要转发它们从其他节点接收到的数据更改。为了防止无限复制循环,每个节点都被赋予唯一的标识符,并且在复制日志中,每个写入都用它经过的所有节点的标识符标记。当一个节点接收一个带有自己标识符的数据更改时,该数据更改将被忽略,因为节点知道它已经被处理了。
环形和星形结构存在的一个问题是,如果有一个节点失效,会中断其他节点之间的同步消息流,而因为它不允许消息沿着不同的路径传播,造成了单点故障。但是All pass的结构也会带来一些新的问题,由于网络拥塞的原因,各个节点的信息接收顺序不一致,如下图所示:
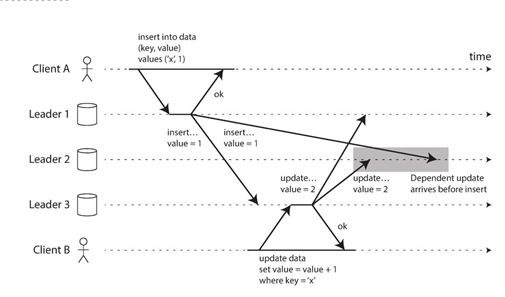
Client A将行插入到一个Leader 1的表,和Client B在Leader 3之中进行更新。而Leader 2收到了不同顺序的写操作:update操作出现在了insert操作之前。为了正确地排列这些事件,我们可以使用一种称为多版本向量控制(MVCC)的技术。至于什么是MVCC,我们下一篇继续来梳理~~( 不是我故意卖关子啊,只是怕写的太长你们懒得看~~~)