如今,推荐系统已经成为各大电商平台的重要流量入口,谁才能够做到比用户更懂用户,谁占据了新零售时代的主动权。手机淘宝的推荐更是淘宝最大的流量入口和最大的成交渠道之一,其背后是最为复杂的业务形态和最复杂的场景技术,那么究竟如何打造手淘背后的推荐系统呢?本次首席技术官大数据专享会上,阿里巴巴搜索推荐事业部资深算法专家欧文武(三桐)为大家解密了淘宝的推荐实战。 手淘推荐简介 手淘推荐的快速发展源于2014年阿里“All in 无线”战略的提出。在无线时代,手机屏幕变小,用户无法同时浏览多个视窗,交互变得困难,在这样的情况下,手淘借助个性化推荐来提升用户在无线端的浏览效率。经过近几年的发展,推荐已经成为手淘上面最大的流量入口,每天服务数亿用户,成交量仅次于搜索,成为了手淘成交量第二大入口。
今天的推荐不仅仅包含商品,还包含了直播、店铺、品牌、UGC,PGC等,手淘整体的推荐物种十分丰富,目前手淘的整体推荐场景有上百个。推荐与搜索不同,搜索中用户可以主动表达需求,推荐很少和用户主动互动,或者和用户互动的是后台的算法模型,所以推荐从诞生开始就是大数据+AI的产品。 手淘推荐特点 相比于其他推荐产品,手淘推荐也有自身的如下特点: 1.购物决策周期:手淘推荐的主要价值是挖掘用户潜在需求和帮助用户购买决策,用户的购物决策周期比较长,需要经历需求发现,信息获取,商品对比和下单决策的过程,电商推荐系统需要根据用户购物状态来做出推荐决策。 2.时效性:我们一生会在淘宝购买很多东西,但是这些需求通常是低频和只在很短的时间窗口有效,比如手机1~2才买一次但决策周期只有几小时到几天,因此需要非常强的时效性,需要快速地感知和捕获用户的实时兴趣和探索未知需求,因此,推荐诞生之初就与Flink、Blink实时计算关系非常紧密。 3.人群结构复杂:手淘中会存在未登录用户、新用户、低活用户以及流式用户等,因此需要制定差异化的推荐策略,并且针对性地优推荐模型。 4.多场景:手淘推荐覆盖了几百个场景,每个场景都独立进行优化显然是不可能的,而且每个场景的条件不同,因此超参也必然不同,无法依靠人工逐个优化场景模型的参数,因此需要在模型之间进行迁移学习以及自动的超参学习等,通过头部场景的迁移学习来服务好尾部场景。 5.多目标和多物种。

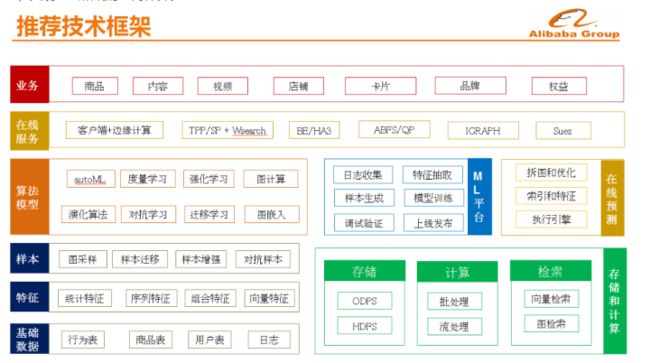
推荐技术框架 如下图所示的是手淘推荐的技术框架。2019年双11,整个阿里巴巴的业务全部实现上云,因此手淘推荐的技术架构也是生长在云上的。推荐的A-B-C包括了推荐算法和模型、原始日志和基于日志加工出来的特征和离在线计算及服务能力,比如向量检索、机器学习平台、在线排序服务等。除了云,今年我们通过把深度学习模型部署到了端上,实现了云和端的协同计算。
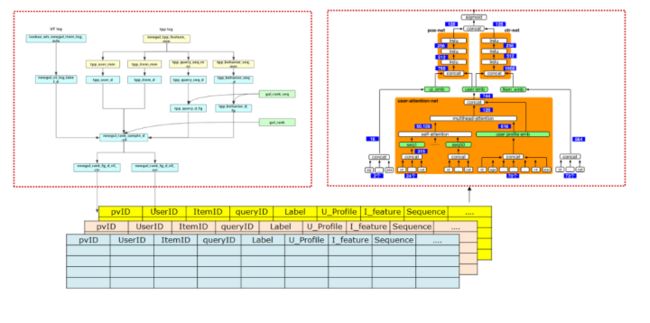
接下来将主要围绕数据、基础设施以及算法模型进行介绍。 数据-基础数据 手淘的推荐数据主要包括几种,即描述型数据比如用户画像,关系数据比如二部图或稀疏矩阵,行为序列和图数据等。基于用户行为序列推荐模型在手淘商品推荐应用最为广泛,图模型则是近两年发展较快的模型,因为序列通常只适合于同构的数据,而在手淘里面,用户的行为有很多种,比如看视频、搜索关键词等,通过graph embedding 等技术可以将异构图数据对齐或做特征融合。

数据-样本 数据样本主要包含两部分元素,label和特征。label一般在手淘推荐中有几类,比如曝光、点击、成交以及加购等。特征则比较多了,比如用户自己的特征、用户上下文特征、商品本身特征以及两两组合特征等。根据用户的特征和行为日志做Join就形成样本表,这些表格存储的时候就是按照稀疏矩阵方式进行存储,一般而言是按天或者按照时间片段形成表格,样本生成需要占用很大一部分离线计算资源。
离线计算-计算模式 离线计算主要有三种模式,即批处理、流处理和交互式查询。批处理中比较典型的就是MapReduce,其特点是延迟高但并行能力强,适合数据离线处理,比如小时/天级别特征计算,样本处理和离线报表等。流计算的特点是数据延迟低,因此非常适合进行事件处理,比如用户实时点击,实时偏好预测,在线学习的实时样本处理和实时报表等。交互式查询则主要用于进行数据可视化和报表分析。

离线计算-模型训练 模型训练也有三种主要的模式,即全量学习、增量学习和在线学习。全量学习这里是指模型初始化从0开始学习,如果日志规模比较小,模型简单并不需要频繁更新时,可以基于全量日志定期训练和更新模型,但当日志和模型参数规模较大时,全量学习要消耗大量计算资源和数天时间,性价比很低,这时通常会在历史模型参数基础上做增量学习,用小时/天日志增量训练模型和部署到线上,降低资源消耗和较高的模型更新频率。如果模型时效性非常强需要用秒/分钟级别样本实时更新模型,这是就需要用到在线学习,在学习和增量学习主要差别是依赖的数据流不一样,在线学习通常需要通过流式计算框架实时产出样本。

离线计算-训练效率 因为机器资源总是不够的,训练优化是如何用更快的速度,更少的计算和更少的数据训练出更好的模型,这里为大家提供一些加速训练的方式: 1.热启动:模型需要不断升级和优化,比如新加特征或修改网络结构,由于被修复部分模型参数是初始值,模型需要重新训练,热启动就是在模型参数只有部分修改时如何用少量的样本让模型收敛。 2.迁移学习:前面提到手淘推荐的场景非常多,而某些场景的日志非常少,因此无法实现大规模模型的训练,这是可以基于样本较多的大场景做迁移学习。 3.蒸馏学习:手淘用来做级联模型学习,比如精排模型特征更多模型更加精准,通过精排和粗排特征蒸馏,提升粗排模型精度,除此之外也可以用来做模型性能优化; 4.低精度、量化和剪枝:随着模型越来越复杂,在线存储和预测成本也在成倍增加,通过这些方式降低模型存储空间和预测速度,另外是端上模型通常对大小有强要求;

离线计算-端到端闭环 因为手淘推荐日志很大,特征来源很复杂,离线和在线的细微变动都可能导致样本出错或离线在线特征/模型不一致,影响迭代效率甚至造成生产故障,我们的解决办法是做一个端到端的开发框架,开发框架对日志,特征和样本做抽象,减低人工开发成本和出错的可能,并在框架嵌套debug 和数据可视化工具,提高问题排查效率。目前手淘搜索推荐已经基本上做到了从最原始日志的收集、到特征抽取以及训练模型的验证、模型的发布,再到线上部署以及实时日志的收集形成整体的闭环,提升了整体模型的迭代效率。

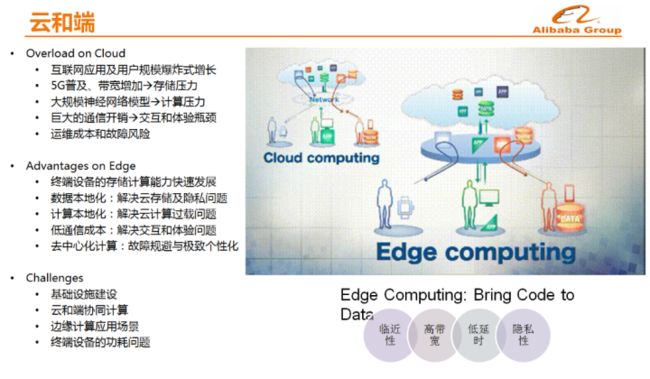
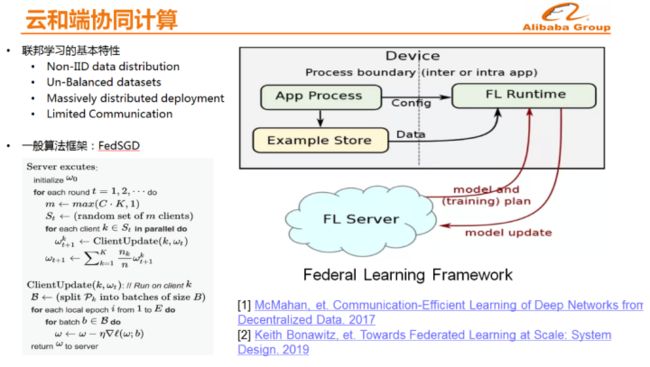
云和端 随着5G和IOT的发展数据会出现爆炸式的膨胀,将数据放在云上集中存储和计算,这样做是否是一个最合理的方式呢?一些数据和计算能否放在端上来做?端上相对于云上而言,还有几个较大的优势,首先延时低,其次是隐式性,各个国家对于隐私的保护要求越来越严厉,因此需要考虑当数据不能发送到云端的时候如何做个性化推荐。
云和端协同计算 在云和端协同计算方面,阿里巴巴已经做了大量的尝试,比如云和端如何实现协同推理,这里包括几个部分,比如手机端上拥有更加丰富的用户行为如用户滑屏速度、曝光窗口时长以及交互时长等,因此第一步是端上的用户行为模式感知的模型。第二步就是在端上决策,比如预测用户何时会离开APP,并在用户离开之前改变一些策略提高用户的浏览深度。此外,手淘还在端上做了一个小型推荐系统,因为目前云上推荐都是一次性给多个结果比如20多个,而手机一次仅能够浏览4到6个推荐结果,当浏览完这20个结果之前,无论用户在手机端做出什么样的操作,都不会向云端发起一次新的请求,因此推荐结果是不变化的,这样就使得个性化推荐的时效性比较差。现在的做法就是一次性将100个结果放在手机端上去,手机端不断地进行推理并且更新推荐结果,这样使得推荐能够具有非常强的时效性,如果这些任务全部放在云端来做,那么就需要增加成千上万台机器。

除了推理之外,还有云和端的协同训练。如果想要实现个人的隐私保护,云和端协同训练是非常重要的,只有这样才能够不将用户的所有原始数据全部加载到云上,大部分训练都在手机端完成,在云端只是处理一些不可解释的用户向量,从而更好地保护用户的隐私数据。
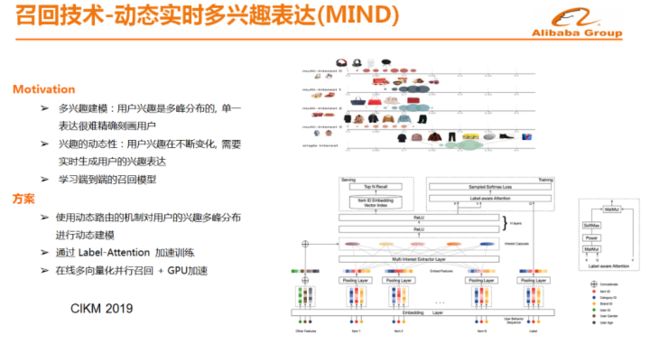
召回技术-动态实时多兴趣表达(MIND) 早些年大家在做推荐协同过滤可能使用Item2Vec召回、标签召回等,比如像Item2Vec召回而言,确实比较简单,而且时效性非常好,在很长一段时间内主导了推荐技术发展的进程,后续才诞生了矩阵分解等。但是Item2Vec召回存在很大的问题,如果商品的曝光点不多其实是很难被推荐出来的,因此推荐的基本上都是热门的Item。其次Item2Vec召回认为每个点击都是独立的,缺少对于用户的全局认知,此时需要做的是就是将用户的行为和标签进行全局感知并做召回。基于这样的出发点,我们提出了基于行为序列的召回模型,但这种方式存在的问题就是用户的兴趣不会聚焦在同一个点,单个向量召回通常只能召回一个类目或者兴趣点,因此如何通过深度学习做用户的多需求表达等都是挑战。这样的问题,阿里巴巴已经解决了,并且将论文发表在CIKM 2019上面。现在,淘宝所使用的是在线多向量化并行召回。
CTR模型 手淘推荐的CTR模型也经历了几个重要的变革,第一个模型是FTRL+LR,其优点是模型简单,能够支持千亿级别特征。第二个模型是XNN,对LR离散特征做embedding,并引入多层神经网络,由于引入新的参数,模型学习能力更强。第三个模型是Self-attention CTR,也就是基于图和用户行为序列实现的。

推荐序列优化-生成式推荐 推荐一般都是基于打分的,打完分之后在做一个贪心排序和打散,这样的做法得到的结果其实并不是最优的,因为这样做并没有考虑结果与结果之间的依赖性,使用贪心算法得到的结果并不是最优的。推荐本质上应该是对于集合而不是序列的优化,因此手淘推荐是用的是生成式排序模型。更多可以参考我们在KDD 2019发表的论文。

多目标均衡优化 在推荐时,大家往往会遇到多目标均衡问题,比如商品推荐的浏览深度,点击和成交,由于目标量纲不一致,不存在全局唯一最优解,需要同时优化多个目标或在多个目标之间做合理取舍,对此我们提出了基于帕累托的多目标优化排序模型。更多可参考我们发表在RecSys 2019的文章。
上云就看云栖号:更多云资讯,上云案例,最佳实践,产品入门,访问:https://yqh.aliyun.com/
本文为阿里云原创内容,未经允许不得转载。