Scrapy框架
什么是scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。
Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度。(Twisted(中文翻译)扭曲)
入门文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html

补充:
阻塞和非阻塞指的是拿到结果之前的状态
异步和同步指的是整个过程
| 功能 | 解释 | scrapy |
|---|---|---|
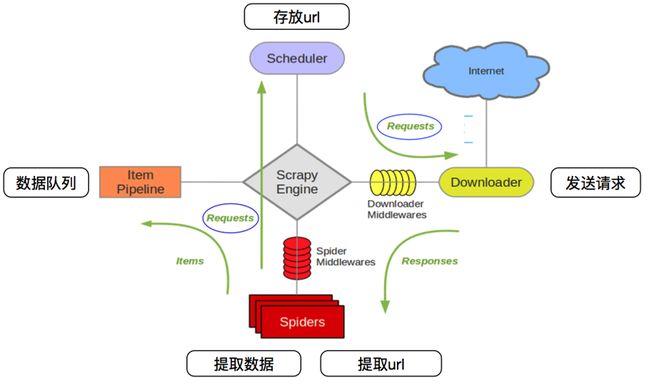
| Scrapy Engine(引擎) | 总指挥:负责数据和信号在不同模块的传递 | scrapy已经实现 |
| Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy已经实现 |
| Downloader(下载器) | 下载把引擎发过来的requests请求,并返回引擎 | scrapy已经实现 |
| Spider(爬虫) | 处理引擎发来的response,提取数据,提取url,并交给引擎 | 需要手写 |
| Item Pipeline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
| Downloader Middlewares(下载中间件) | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
| Spider MiddlewaresSpider(中间件) | 可以自定义requests请求和进行response过滤 | 一般不用手写 |
文件目录
scrapy.cfg #项目的配置文件
items.py #提取要爬取的字段,字典保存爬取到的数据的容器
middlewares #自定义中间件的地方
pipelines.py #管道,保存数据
settings.py #项目的设置文件 设置文件,UA,启动管道
spiders #存储爬虫代码目录
itcast.py #写爬虫的文件
爬虫步骤:
1.创建一个scrapy项目
scrapy startproject mySpider #mySpider是项目名字2.生成一个爬虫
scrapy genspider itcast itcast.cn #itcast是爬虫名字,"itcast.cn"限制爬虫地址,防止爬到其他网站3.提取数据
完善spiders,使用xpath等方法3.保存数据
pipelines中保存数据
启动爬虫
scrapy crawl 爬虫名字 #crawl(抓取的意思)
启动爬虫不打印日志
scrapy crawl 爬虫名字 --nolog
run.py启动爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl lagou".split())
spider内容
spider翻页
# -*- coding: utf-8 -*-
import scrapy
#导入items
from tencent.items import TencentItem
#自定义spider类,继承自scrapy.Spider
class ItcastSpider(scrapy.Spider):
name = 'itcast' #爬虫名字<爬虫启动时候使用:scrapy crawl itcast>
#允许爬取的范围,防止爬虫爬到了别的网站
allowed_domains = ['tencent.com']
#开始爬取的地址,下载中间件提取网页数据
start_urls = ['https://hr.tencent.com/position.php']
#数据提取方法,接收下载中间件传过来的response(响应)
def parse(self, response):
#处理start_url地址对应的响应
#提取数据
# reti = response.xpath("//div[@class='tea_con']//h3/text()").extract()
# print(reti)
#分组,[1:-1]切片,不要第一条数据
li_list = response.xpath("//table[@class="tablelist"]/tr")[1:-1]
for li in li_list:
#在item中定义要爬取的字段,以字典形式传入
item = TencentItem()
item["name"] = li.xpath(".//h3/text()").extract_first()
item["title"] = li.xpath(".//h4/text()").extract_first()
#yield可以返回request对象,BaseItem(items.py中的类),dict,None
yield item #yield传到pipeline
#找到下一页url地址
next_url = response.xpath('//a[@id="next"]/@href').extract_first()
#如果url地址的href="地址"不等于javascript:;
if next_url != "javascript:;":
next_url = "https://hr.tencent.com/"+ next_url
#把next_url的地址通过回调函数callback交给parse方法处理
yield scrapy.Request(next_url,callback=self.parse)
提取数据
response.xpath('//a[@id="next"]/@href')body = response.text.replace('\n', '').replace('\r', '').replace('\t', '')
re.findall('
从选择器中提取字符串:
- extract() 返回一个包含有字符串数据的列表
- extract_first()返回列表中的第一个字符串
注意:
- spider中的parse方法名不能修改
- 需要爬取的url地址必须要属于allow_domain(允许_域)下的连接
- respone.xpath()返回的是一个含有selector对象的列表
为什么要使用yield?
让整个函数变成一个生成器,变成generator(生成器)有什么好处?
每次遍历的时候挨个读到内存中,不会导致内存的占用量瞬间变>高python3中range和python2中的xrange同理
scrapy.Request常用参数为
callback = xxx:指定传入的url交给那个解析函数去处理
meta={"xxx":"xxx"}:实现在不同的解析函数中传递数据,配合callback用
dont_filter=False:让scrapy的去重不会过滤当前url,默认开启url去重
headers:请求头
cookies:cookies,不能放在headers中,独立写出来
method = "GET":请求方式,(GET和POST)
爬取详细页和翻页
# -*- coding: utf-8 -*-
import scrapy
from yangguang.items import YangguangItem
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4&page=0']
def parse(self, response):
tr_list = response.xpath("//div[@class='greyframe']/table[2]/tr/td/table/tr")
for tr in tr_list:
item = YangguangItem()
item["title"] = tr.xpath("./td[2]/a[@class='news14']/@title").extract_first()
item["href"] = tr.xpath("./td[2]/a[@class='news14']/@href").extract_first()
item["publish_date"] = tr.xpath("./td[last()]/text()").extract_first()
#执行进入url地址,再把item传到下面parse_detail,提取详细页的内容
yield scrapy.Request(item["href"],callback=self.parse_detail,meta={"item":item})
#翻页
#获取url地址
next_url = response.xpath("//a[text()='>']/@href").extract_first()
#如果下一页url地址不为空,进入下一页连接
if next_url is not None:
yield scrapy.Request(next_url,callback=self.parse)
#处理详情页
def parse_detail(self,response):
#item接收meta传过来的item,在item字典里继续为item添加内容
item = response.meta["item"]
#拿到详细页的内容
item["content"] = response.xpath("//div[@class='c1 text14_2']//text()").extract()
#拿到详细页的图片地址
item["content_img"] = response.xpath("//div[@class='c1 text14_2']//img/@src").extract()
#给图片前面加上http://wz.sun0769.com
item["content_img"] = ["http://wz.sun0769.com" + i for i in item["content_img"]]
#把item传给pipeline
yield item
items(存储爬取字段)
import scrapy
#scrapy.Item是一个字典
class TencentItem(scrapy.Item):
#scrapy.Field()是一个字典
url = scrapy.Field()
name = scrapy.Field()
使用pipeline(管道)
from demo1 import settings
import pymongo
class Demo1Pipeline(object):
def __init__(self):
#连接mongodb数据库(数据库地址,端口号,数据库)
client = pymongo.MongoClient(host=settings.MONGODB_HOST, port=settings.MONGODB_PORT)
#选择数据库和集合
self.db = client[settings.MONGODB_DBNAME][settings.MONGODB_DOCNAME]
def process_item(self, item, spider):
data = dict(item)
self.db.insert(data)
#完成pipeline代码后,需要在setting中设置开启
ITEM_PIPELINES = {
#开启管道,可以设置多个管道,'管道地址数值':越小越先执行
'mySpider.pipelines.MyspiderPipeline': 300,
}
# MONGODB 主机环回地址127.0.0.1
MONGODB_HOST = '127.0.0.1'
# 端口号,默认是27017
MONGODB_PORT = 27017
# 设置数据库名称
MONGODB_DBNAME = 'DouBan'
# 存放本次数据的表名称
MONGODB_DOCNAME = 'DouBanMovies'
第二种:
class MyspiderPipeline(object):
def __init__(self):
#连接mongodb数据库(数据库地址,端口号,数据库)
client = pymongo.MongoClient(host=settings.MONGODB_HOST, port=settings.MONGODB_PORT)
#选择数据库和集合
self.db = client[settings.MONGODB_DBNAME]
#实现存储方法,item是spider传过来的,spider就是自己写的爬虫
def process_item(self, item, spider):
table = ''
#通过spider参数,可以针对不同的Spider进行处理
#spider.name爬虫的名字
if spider.name == "itcast":
#如果爬虫的名字为itcast执行这里面的东西
table = self.db.表名
#如果爬虫的名字为itcast2执行这里面的东西
elif spider.name == "itcast2":
table = self.db.表名
table.insert(dict(item))
#也可以通过item参数,可以针对不同的Item进行处理
table = ''
if isinstance(item, 爬虫名字):
table = self.db.表名
table.insert(dict(item))
mysql存储
from pymysql import connect
import pymysql
class TxPipeline(object):
def __init__(self):
self.conn=connect(host='localhost',port=3306,db='txzp',user='root',passwd='root',charset='utf8')
self.cc = self.conn.cursor()
def process_item(self, item, spider):
print(item["title"],item["href"],item["number"],item["time"],item["duty"])
aa = (item["title"],item["href"],item["number"],item["time"],item["duty"],item["requirement"])
sql = '''insert into tx values (0,"%s","%s","%s","%s","%s","%s")'''
self.cc.execute(sql%aa)
self.conn.commit()#提交
# self.cc.close() #关闭游标会报错
注意
- pipeline中process_item方法名不能修改,修改会报错
- pipeline(管道)可以有多个
- 设置了pipelines必须开启管道,权重越小优先级越高
为什么需要多个pipeline:
- 可能会有多个spider,不同的pipeline处理不同的item的内容
- 一个spider的内容可能要做不同的操作,比如存入不同的数据库中
简单设置LOG(日志)
为了让我们自己希望输出到终端的内容能容易看一些:
我们可以在setting中设置log级别
在setting中添加一行(全部大写):
LOG LEVEL="WARNING"
默认终端显示的是debug级别的log信息
logging模块的使用
scrapy中使用logging
#settings中设置
LOG_LEVEL=“WARNING”
LOG_FILE="./a.log" #设置日志保存的位置,设置会后终端不会显示日志内容
#打印logging日志
import logging
#实例化logging,显示运行文件的名字,不写不会显示运行文件的目录
logging = logging.getLogger(__name__)
#日志输出打印
logging.warning(item)
#打印内容(日志创建时间,运行文件的目录,日志级别,打印的内容)
2018-10-31 15:25:57 [mySpider.pipelines] WARNING: {'name': '胡老师', 'title': '高级讲师'}
普通项目中使用logging
具体参数信息:https://www.cnblogs.com/bjdxy/archive/2013/04/12/3016820.html
#a.py文件
import logging
#level: 设置日志级别,默认为logging.WARNING
logging.basicConfig(level=logging.INFO,
format=
#日志的时间
'%(asctime)s'
#日志级别名称 : 当前行号
' %(levelname)s [%(filename)s : %(lineno)d ]'
#日志信息
' : %(message)s'
#指定时间格式
, datefmt='[%Y/%m/%d %H:%M:%S]')
#实例化logging,显示当前运行文件的名字,不写不会显示运行文件的目录
logging=logging.getLogger(__name__)
if __name__ == '__main__':
#日志级别打印信息
logging.info("this is a info log")
b.py文件使用a.py文件的logging(日志)
#b.py文件
from a import logging #导入a.py中的实例logging
if __name__ == '__main__':
#warning级别大于info也可以打印,debug级别小于info,不可以打印
logger.warning("this is log b")
日志级别:
- debug #调试
- info #正常信息
- warning #警告
- error #错误
如果设置日志级别为info,warning级别比info大,warning也可以打印,debug比info小不可以打印
如果设置日志级别为warning,info和debug都比warning小,不可以打印
把数据保存到mongodb中
#导入mongodb的包
from pymongo import MongoClient
#实例化client,建立连接
client = MongoClient(host='127.0.0.1',port = 27017)
#选择数据库和集合
collection = client["tencent"]["hr"]
class TencentPipeline(object):
def process_item(self, item, spider):
#传过来的数据是对象,把item转化为字典
item = dict(item)
#把数据存入mongodb数据库
collection.insert(item)
print(item)
return item
scrapy shell
Scrapy shell是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath表达式
使用方法:
命令行输入:
scrapy shell http://www.itcast.cn/channel/teacher.shtml
常用参数:
response.url:当前响应的url地址
response.request.url:当前响应对应的请求的url地址
response.headers:响应头
response.body:响应体,也就是html代码,默认是byte类型
response.body.decode():变为字符串类型
response.request.headers:当前响应的请求头
response.xpath("//h3/text()").extract():调试xpath,查看xpath可不可以取出数据
setting设置文件
为什么需要配置文件:
- 配置文件存放一些公共的变量(比如数据库的地址,账号密码等)
- 方便自己和别人修改
- 一般用全大写字母命名变量名SQL_HOST='192.168.0.1'
参考地址:https://blog.csdn.net/u011781521/article/details/70188171
#常见的设置
#项目名
BOT_NAME = 'yangguang'
#爬虫位置
SPIDER_MODULES = ['yangguang.spiders']
NEWSPIDER_MODULE = 'yangguang.spiders'
#遵守robots协议,robots.txt文件
ROBOTSTXT_OBEY = True
#下载延迟,请求前睡3秒
DOWNLOAD_DELAY = 3
# 默认请求头,不能放浏览器标识
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"Cookie": "rfnl=https://www.guazi.com/sjz/dazhong/; antipas=2192r893U97623019B485050817",
}
#项目管道,保存数据
ITEM_PIPELINES = {
'yangguang.pipelines.YangguangPipeline': 300,
}
spiders文件使用settings的配置属性
#第一种
self.settings["MONGO_HOST"]
#第二种
self.settings.get("MONGO_HOST")
pipelines文件使用settings的配置属性
spider.settings.get("MONGO_HOST")
Scrapy中CrawlSpider类
深度爬虫
#创建CrawlSpider爬虫,就多加了-t crawl
scrapy genspider -t crawl cf gov.cn
第一种用法:提取内容页和翻页
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from tengxun.items import TengxunItem
class TxSpider(CrawlSpider):
name = 'tx'
allowed_domains = ['hr.tencent.com']
#第一次请求的url
start_urls = ['https://hr.tencent.com/position.php']
#rules自动提取url地址
rules = (
# 内容页,交给parse_item处理数据
Rule(LinkExtractor(allow=r'position_detail\.php\?id=\d+&keywords=&tid=0&lid=0'), callback='parse_item'),
# 翻页
Rule(LinkExtractor(allow=r'position\.php\?&start=\d+#a'), follow=True),
)
#处理内容页的数据
def parse_item(self, response):
item = TengxunItem()
#爬取标题
item["bt"] = response.xpath('//td[@id="sharetitle"]/text()').extract_first()
#爬取工作要求
item["gzyq"] = response.xpath('//div[text()="工作要求:"]/../ul/li/text()').extract()
yield item
第二种用法:提取标题页,内容,翻页
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from tengxun.items import TengxunItem
class Tx2Spider(CrawlSpider):
name = 'tx2'
allowed_domains = ['hr.tencent.com']
start_urls = ['https://hr.tencent.com/position.php']
rules = (
#翻页
Rule(LinkExtractor(allow=r'position\.php\?&start=\d+#a'), callback='parse_item', follow=True),
)
#标题页内容
def parse_item(self, response):
tr_list = response.xpath('//table[@class="tablelist"]/tr')[1:-1]
for tr in tr_list:
item = TengxunItem()
#爬取标题
item['bt'] = tr.xpath('./td/a/text()').extract_first()
#爬取url
item['url'] = tr.xpath('./td/a/@href').extract_first()
item['url'] = "https://hr.tencent.com/" + item['url']
yield scrapy.Request(
item['url'],
callback=self.parse_detail,
meta={"item":item}
)
#爬取内容
def parse_detail(self,response):
item = response.meta['item']
item['gzyq'] = response.xpath('//div[text()="工作要求:"]/../ul/li/text()').extract()
yield item
#LinkExtractor 连接提取器,提取url地址
#callback 提取出来的url地址的response会交给callback处理
#follow 当前url地址的响应是否重新进过rules来提取url地址
#提取详细页的url
#CrawlSpider会自动把url补充完整
Rule的匹配细节
Rule(LinkExtractor(allow=r'position_detail\.php\?id=\d+&keywords=&tid=0&lid=0'), callback='parse_item'),
#这里把该匹配的东西写成正则
#?和.别忘了转义\? \.
#LinkExtractor 连接提取器,提取url地址
#callback 提取出来的url地址的response会交给callback处理
#follow 当前url地址的响应是否重新进过rules来提取url地址
#提取详细页的url
#CrawlSpider会自动把url补充完整
注意点:
- 用命令创建一个crawlspider的模板:scrapy genspider-t crawl 爬虫名字 域名,也可以手动创建
- CrawiSpider中不能再有以parse为名字的数据提取方法,这个方法被CrawlSpider用来实现基础url提取等功能)
- 一个Rule对象接收很多参数,首先第一个是包含url规则的LinkExtractor对象,常用的还有calback(制定满足规则的url的解析函数的字符串)和follow(response中提取的链接是否需要跟进)
- 不指定callback函数的请求下,如果follow为True,满足该rule的url还会继续被请求
- 如果多个Rule都满足某一个url,会从rules中选择第一个满足的进行操作
CrawlSpider补充(了解)
LinkExtractor更多常用链接
LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm')
allow:满足括号中"正则表达式"的URL会被提取,如果为空,则全部匹配.
deny:满足括号中"正则表达式"的URL一定不提取(优先级高于allow).
allow_domains:会被提取的链接的domains.
deny_domains:一定不会被提取链接的domains.
restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接,级xpath满足范围内的uri地址会被提取
rule常见参数:
Rule(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item', follow=False),
LinkExtractor:是一个Link Extractor对象,用于定义需要提取的链接.
callback:从link_extractor中每获取到链接时,参数所指定的值作为回调函数
follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进.如果callback为None,follow 默认设置为True,否则默认为False.
process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数,该方法主要用来过滤url.
process_request:指定该spider中哪个的函数将会被调用,该规则提取到每个request时都会调用该函数,用来过滤request
Scrapy分布式爬虫
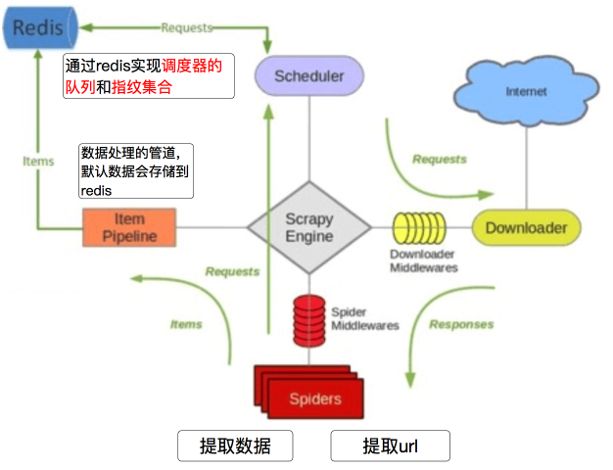
Scrapy_redis之domz
domz相比于之前的spider多了持久化和request去重的功能
domz就是Crawlspider去重和持久化版本
不能分布式
可以分布式的是RedisSpider和RedisCrawlspider
Scrapy redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:reqeust去重,爬虫持久化,和轻松实现分布式
官方站点:https://github.com/rmax/scrapy-redis
#spiders文件夹
爬虫内容和自己写的CrawlSpider没有任何区别
settings.py
#写上下面东西Crawlspider就可以去重了
#还可以持久化爬虫,关闭后,在开启继续爬取
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #去重
SCHEDULER = "scrapy_redis.scheduler.Scheduler" #重写调度器(scheduler)
SCHEDULER_PERSIST = True #不清楚缓存,队列中的内容是否持久保存(开启后爬虫关闭后,下次开启从关闭的位置继续爬取)
ITEM_PIPELINES = {
#将数据保存到redis中,屏蔽这条命令
#'scrapy_redis.pipelines.RedisPipeline': 400,
}
#指定redis地址
REDIS_URL = 'redis://127.0.0.1:6379'
#也可以写成下面形式
#REDIS_HOST = "127.0.0.1"
#REDIS_PORT = 6379
我们执行domz的爬虫,会发现redis中多了一下三个键:
dmoz:requests (zset类型)(待爬取)
Scheduler队列,存放的待请求的request对象,获取的过程是pop操作,即获取一个会去除一个dmoz:dupefilter (set)(已爬取)
指纹集合,存放的是已经进入scheduler队列的request对象的指纹,指纹默认由请求方法,url和请求体组成dmoz:items (list类型)(item信息)
存放的获取到的item信息,在pipeline中开启RedisPipeline才会存入
Scrapy_redis之RedisSpider
from scrapy_redis.spiders import RedisSpider
#继承RedisSpider
class MySpider(RedisSpider):
#指定爬虫名
name='myspider_redis'
#指定redis中start_urls的键,
#启动的时候只需要往对应的键总存入url地址,不同位置的爬虫就会来获取该url
#所以启动爬虫的命令分类两个步骤:
#(1)scrapy crawl myspider_redis(或者scrapy runspider myspider_redis)让爬虫就绪
#(2)在redis中输入lpush myspider:start_urls"http://dmoztools.net/"让爬虫从这个ur开始爬取
redis_key ='myspider:start_urls'
#手动指定allow_domain,执行爬虫范围
#可以不写
allow_doamin=["dmoztools.net"]
def parse(self, response):
#普通scrapy框架写法
...
启动
#爬虫名字
scrapy runspider myspider
或(2选1)
#蜘蛛文件名字
scrapy runspider myspider.py
redis运行
#redis 添加 键:值 "爬取的网址"
redis-c1i lpush guazi:start_urls "http://ww.guazi.com/sjz/dazhong/"
Scrapy_redis之RedisCrawlSpider
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisCrawlSpider
#继承RedisCrawlSpider
class MyCrawler(RedisCrawlSpider):
#爬虫名字
name='mycrawler_redis'
#start_url的redis的键
redis_key='mycrawler:start_urls'
#手动制定all_domains,可以不写
allow_domains=["dmoztools.net"]
#和crawl一样,指定url的过滤规则
rules=(
Rule(LinkExtractor(),callback='parse_page',follow=True)
启动
#爬虫名字
scrapy runspider myspider
或(2选1)
#蜘蛛文件名字
scrapy runspider myspider.py
redis运行
#redis 添加 键:值 "爬取的网址"
redis-c1i lpush guazi:start_urls "http://ww.guazi.com/sjz/dazhong/"
快速启动爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl guazicrawl".split())
# import redis
#
# r=redis.StrictRedis()
# r.lpush("myspider:start_urls",[])
其他参数
- 如果抓取的url不完整,没前面的url,可以使用下面方法
import urllib
a = http://www.baidu.com?123
b = ?456
#在程序中a可以使用response.url(响应地址)
#在pycharm中parse颜色会加深,不过没事
b = urllib.parse.urljoin(a,b)
print("b=%s"%b)
#b=http://www.baidu.com?456
存多个url或其他东西,可以用列表存储
#比如存图片连接,一个网页中有很多图片连接
item["img_list"] =[]
#extend追加的方式,注意后面用.extract()
item["img_list"].extend(response.xpath('//img[@class="BDE_Image"]/@src').extract())