【原创】Helenykwang 于2018-01-13 18:10:18编写
不用maven,不用sbt,只需三个库
一、环境说明
集群:Spark 2.1.2 + hadoop2.3
开发机OS:win7
Jdk 1.8.0_151
下载jre即可 http://www.oracle.com/technetwork/java/javase/downloads/index.html
注:JDK是一个平台特定的软件,有针对Windows,Mac和Unix系统的不同的安装包。 可以说JDK是JRE的超集,它包含了JRE的Java编译器,调试器和核心类
scala 2.11.8 http://www.scala-lang.org/download/
IntelliJ IDEA 2017.3
spark 源码spark-2.1.2-bin-hadoop2.3
二、环境搭建
1. 基本配置
安装java、scala,配置环境变量JAVA_HOME、SCALA_HOME为对应安装路径
PATH后面添加%JAVA_HOME%\jre\bin; %SCALA_HOME%\bin
【WIN】%JAVA_HOME%
【Linux】$JAVA_HOME
注意:scala 安装路径不能有空格,否则会报错
>>找不到或无法加载主类scala.tools.nsc.MainGenericRunner
检验标准
打开CMD,分别执行java、scala命令。

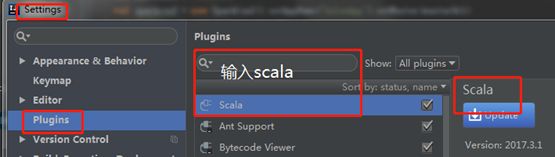
2. 安装配置IntelliJ IDEA 2017.3
初始化后,在file –settings 中添加scala插件,重启
三、开发示例
1. 新建工程
其实这里选个java工程就行了,不用搞那么复杂,记住关键是依赖库java、scala、spark源码库添加好就行。
下图展示了创建工程时添加java-sdk、scala-sdk的过程。

创建一些必需的目录,我的demo的目录树如下:
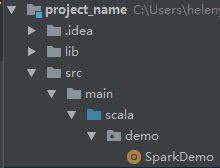
在scala目录右键mark Directory as -- Source Root

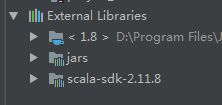
2. 添加spark源码依赖
从File – Project Structure 进入,添加Lib,按下图操作完毕后,点击apply – ok

文件树的外部库会出现以下三个:分别是java、spark、scala【重点强调唷~ 三者必备,其他随意】
3. 编写程序
新建一个scala文件SparkDemo.scala,代码如下:
package demo
importorg.apache.spark._
objectSparkDemo{
def main(args: Array[String]): Unit = {
val masterUrl = "local[1]"
val sparkconf = newSparkConf().setAppName("helenApp").setMaster(masterUrl)
//spark配置,建议保留setMaster(local)
//调试的时候需要,在实际集群上跑的时候可在命令行自定义
val sc = new SparkContext(sparkconf)
val rdd=sc.parallelize(List(1,2,3,4,5,6)).map(_*3) //将数组(1,2,3,4,5,6)分别乘3
rdd.filter(_>10).collect().foreach(println) //打印大于10的数字
println(rdd.reduce(_+_)) //打印 和
println("hello world") // demo必备的一句代码!!! [认真脸]
}
}
此时,scala编辑界面可能出现这句话,点击setup scala SDK就可以了。
依赖库添加成功的检验标准是,import org.apache.spark._不报错。
点击绿色三角形,run~
在console界面正常输出!(*^__^*)

4. 打包jar包
依旧是从老朋友File–Project Structure 进入,在Artifacts下添加jar。
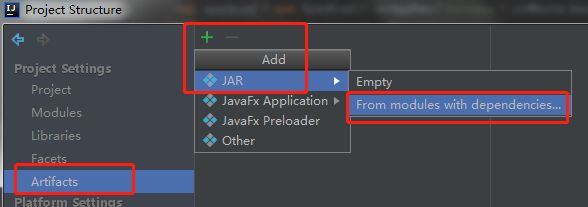

注意:打包的jar包不需要把spark源码也搞进去的,因为集群上本身就有spark代码,所以就留下以下这两个文件即可~~~ 点击apply –ok

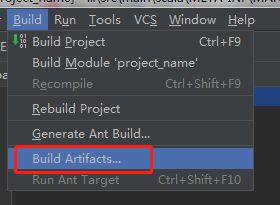
在主界面,Build—Build Artifacts。开始编译~~~ 编译OK后会多出一个out目录,里面有最终jar包
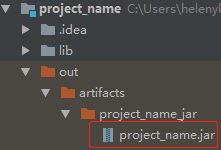
查看主类,MANIFEST.MF文件内容如下:
Manifest-Version:1.0
Main-Class:demo.SparkDemo
5. 集群上运行jar包
Jar包放到/home/hadoop目录下
>>spark-submit --class demo.SparkDemo--master spark://:7077 project_name.jar
说明:--class <主类名> 最后跟的参数是我们的jar包。--master指定了集群master,中间还可以自定义一些spark配置参数,例如:
--num-executors 100 \
--executor-memory6G \
--executor-cores4 \
--driver-memory1G \
--confspark.default.parallelism=1000 \
--confspark.storage.memoryFraction=0.5 \
--confspark.shuffle.memoryFraction=0.3 \
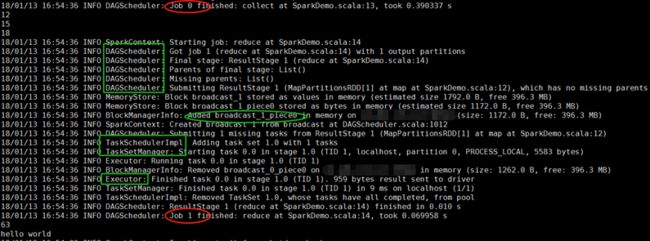
集群上运行成功~~~
总结
其实看了很多什么maven工程、scala工程构建方法,其实大同小异,重点无非是java、spark、scala的依赖搞好,这才是核心问题。
注意版本一致性,包括:
· 开发机和集群的spark源码版本一致
· 开发IDE中scala插件和系统安装的scala和集群上scala版本一致
· scala 和spark 版本匹配。(spark2.x 相比 1.x 有很多不同,请使用scala 2.11+版本)
===================分割线=======================
踩过的坑 ~~~ (๑ŐдŐ)b,欢迎小伙伴们和我分享遇到的问题 (*^__^*) ~~~
错误集锦
出错情况:
命令行运行scala时,找不到或无法加载主类scala.tools.nsc.MainGenericRunner
出错原因:
scala安装目录出现了空格。
问题解决:
将Scala 移动到没有空格的文件夹下。重新设置SCALA_HOME。文件解决。
出错情况:
编写程序时,调用rdd.saveAsTextFile 报错NullPointerException
出错原因:
和hadoop文件输出配置有关,下个补丁,配置一下即可
解决方法:
1)下载文件winutils.exe
2) 将此文件放置在某个目录下,比如D:\hadoop\bin\中。
3)在scala程序的一开始声明:System.setProperty("hadoop.home.dir","D:\\hadoop\\")
出错情况:
maven初始化工程时,连接https://repo.maven.apache.org/maven2超时失败
出错原因:
PC网络自身的问题。不能访问外网。
解决方法:
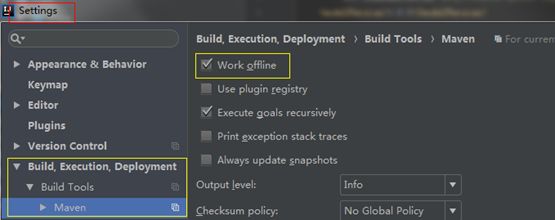
使用maven离线模式,手动把依赖库导入 <用户目录>\\.m\\ repository
Q:什么时候需要maven离线模式呢?
A:没有网络,只有本地库,又是用maven来管理项目,在编译或者下载第三方Jar的时候,老是去中央仓库上自动下载,导致出问题。
1) 全局设置Work offline 如下图所示
2) 编辑 <用户目录>\\.m\\ settings.xml,写一行: