2018.01.20
堆栈原理:
问题描述
编程语言书籍中经常解释值类型被创建在栈上,引用类型被创建在堆上,但是并没有本质上解释这堆和栈是什么。我仅有高级语言编程经验,没有看过对此更清晰的解释。我的意思是我理解什么是栈,但是它们到底是什么,在哪儿呢(站在实际的计算机物理内存的角度上看)?
在通常情况下由操作系统(OS)和语言的运行时(runtime)控制吗?
1、它们的作用范围是什么?
2、它们的大小由什么决定?
3、哪个更快?
4、每一个线程都有一个栈,但是每一个应用程序通常都只有一个堆(尽管为不同类型分配内存使用多个堆的情况也是有的)。
直接回答你的问题:
- 当线程创建的时候,操作系统(OS)为每一个系统级(system-level)的线程分配栈。通常情况下,操作系统通过调用语言的运行时(runtime)去为应用程序分配堆。
- 栈附属于线程,因此当线程结束时栈被回收。堆通常通过运行时在应用程序启动时被分配,当应用程序(进程)退出时被回收。
- 当线程被创建的时候,设置栈的大小。在应用程序启动的时候,设置堆的大小,但是可以在需要的时候扩展(分配器向操作系统申请更多的内存)。
- 栈比堆要快,因为它存取模式使它可以轻松的分配和重新分配内存(指针/整型只是进行简单的递增或者递减运算),然而堆在分配和释放的时候有更多的复杂的 bookkeeping 参与。另外,在栈上的每个字节频繁的被复用也就意味着它可能映射到处理器缓存中,所以很快(译者注:局部性原理)。
多线程篇:
Runloop是事件接收和分发机制的一个实现,每一个线程都有其对应的RunLoop,但是默认非主线程的RunLoop是没有运行的。一般情况下我们是没有必要去启用线程的RunLoop的,除非你在一个单独的线程中需要长久的检测某个事件。
主线程��默认有Runloop。当自己启动一个线程,如果只是用于处理单一的事件,则该线程在执行完之后就退出了。所以当我们需要让该线程监听某项事务时,就得让线程一直不退出,runloop就是这么一个循环,没有事件的时候,一直卡着,有事件来临了,执行其对应的函数
Runloop接收两种源事件:input sources和timer sources。
input sources 传递异步事件,通常是来自其他线程和不同的程序中的消息;
timer sources(定时器) 传递同步事件(重复执行或者在特定时间上触发)。Runloop工作的特点:
1> 当有事件发生时,Runloop会根据具体的事件类型通知应用程序作出响应;
2> 当没有事件发生时,Runloop会进入休眠状态,从而达到省电的目的;
3> 当事件再次发生时,Runloop会被重新唤醒,处理事件
 线程所占空间.png
线程所占空间.png
2017.12.04
- id obj = [NSMutableArray array] 生成对象但不持有,相当于
-- (id)object{
id obj = [NSMutableArray array];
[obj autorelease];
return obj;
} - NSZone是防止内存碎片化而引入的结构,对内存分配的区域进行多重化管理。
- 苹果对引用计数的实现是将引用计数保存在引用计数表中,对象用内存块无需考虑内存块头部,引用计数表各记录中存有内存块地址,可从各记录追溯到各对象的内存块。这一特性在调试时有着很大作用。
2017.10.23
associatedObject又称关联对象。顾名思义,就是把一个对象关联到另外一个对象身上。使两者能够产生联系。目前关联对象的使用场景有如下几点:
- 运行时给cagetory添加getter和setter。因为category中添加的property不会生成带下划线"_"的成员变量以及getter和setter的实现。所以可以通过关联对象实现getter和setter。
- 有时需要在对象中存储一些额外的信息,我们通常会从对象所属的类中继承一个子类。然后给这个子类添加额外的属性,改用这个子类。然而并非所有的情况都能这么做,有时候类的实例可能是由某种机制创建的,而开发者无法另这种机制创建出自己所写的子类实例。此时可以使用“关联对象”。
- 有时只是给某个类添加一个额外的属性,完全没有必要继承出来一个子类。此时可以使用“关联对象”。
- delegate回调的方法中使用关联对象。有时候在一些delegate回调的方法中需要处理一些回调任务。比如发起网络请求和在delegate回调的方法中做UI的更新。这样一来,发起网络请求和在回调中更新UI的代码被分散到了两个地方,不利于管理和阅读。此时可以使用“关联对象”。
2017.10.20
1、直接访问相关变量与通过属性的点语法来访问有几个区别:
- 直接访问变量由于不经过OC的方法派发步骤,所以直接访问实例变量的速度当然比较快。这种情况下,编译器所生成的代码会直接访问板寸对象实例变量的那块内存。
- 直接访问实例变量时,不会调用设置方法,这就绕过了为相关属性所定义的“内存管理语义”,比如直接访问copy属性,并不会拷贝该属性。
- 直接访问实例变量时,不会触发键值观测KVO通知。
有一种合理的折中方案,那就是:在写入变量时通过“设置方法”来做,而在读取实例变量时,则直接访问之。但是在初始化方法中要注意:一般直接访问实例变量,因为子类可能会覆写设置方法。但是某些情况下又必须在初始化方法中调用设置方法:1、如果待初始化的实例变量声明在父类中,而我们又无法在子类中直接访问此实例变量的话,那么久需要调用设置方法了。2、懒加载的情况必须通过“获取方法”来访问属性。
2017.08.29
1、自定义对象的复制
使用copy和mutableCopy复制对象的副本使用起来确实方便,那么我们自定义的类是否可调用copy与mutableCopy方法来复制副本呢?我们先定义一个Person类,代码如下:
@interface Person : NSObject
@property (nonatomic, assign) NSInteger age;
@property (nonatomic, copy) NSString *name;
@end
然后尝试调用Person的copy方法来复制一个副本:
Person *person1 = [[Person alloc] init];//创建一个Person对象
person1.age = 20;
person1.name = @"张三";
Person *person2 = [person1 copy];//复制副本
运行程序,将会发生崩溃,并输出以下错误信息:
[Person copyWithZone:]: unrecognized selector sent to instance 0x608000030920
上面的提示:Person找不到copyWithZone:方法。我们将复制副本的代码换成如下:
Person *person2 = [person1 mutableCopy];//复制副本
再次运行程序,程序同样崩溃了,并输出去以下错误信息:
[Person mutableCopyWithZone:]: unrecognized selector sent to instance 0x600000221120
上面的提示:Person找不到mutableCopyWithZone:方法。大家可能会觉得疑惑,程序只是调用了copy和mutableCopy方法,为什么会提示找不到copyWithZone:与mutableCopyWithZone:方法呢?其实当程序调用对象的copy方法来复制自身时,底层需要调用copyWithZone:方法来完成实际的复制工作,copy返回实际上就是copyWithZone:方法的返回值;mutableCopy与mutableCopyWithZone:方法也是同样的道理。那么怎么做才能让自定义的对象进行copy与mutableCopy呢?需要做以下事情:
1.让类实现NSCopying/NSMutableCopying协议。
2.让类实现copyWithZone:/mutableCopyWithZone:方法
所以让我们的Person类能够复制自身,我们需要让Person实现NSCopying协议;然后实现copyWithZone:方法:
@interface Person : NSObject
@property (nonatomic, assign) NSInteger age;
@property (nonatomic, copy) NSString *name;
@end
#import "Person.h"
@implementation Person
- (id)copyWithZone:(NSZone *)zone {
Person *person = [[[self class] allocWithZone:zone] init];
person.age = self.age;
person.name = self.name;
return person;
}
@end
运行之后发现我们实现了对象的复制:
 122030896-af5a229f764d9214
122030896-af5a229f764d9214
同时需要注意的是如果对象中有其他指针类型的实例变量,且只是简单的赋值操作:person.obj2 = self.obj2,其中obj2是另一个自定义类,如果我们修改obj2中的属性,我们会发现复制后的person对象中obj2对象中的属性值也变了,因为对于这个对象并没有进行copy操作,这样的复制操作不是完全的复制,如果要实现完全的复制,需要将obj2
对应的类也要实现copy,然后这样赋值:
person.obj2 = [self.obj2 copy]
如果对象很多或者层级很多,实现起来还是很麻烦的。如果需要实现完全复制同样还有另有一种方法,那就是归档:
Person *person2 = [NSKeyedUnarchiver unarchiveObjectWithData:[NSKeyedArchiver archivedDataWithRootObject:person1]];
这样我们就实现了自定义对象的复制,需要指出的是如果重写copyWithZone:方法时,其父类已经实现NSCopying协议,并重写过了copyWithZone:方法,那么子类重写copyWithZone:方法应先调用父类的copy方法复制从父类继承得到的成员变量,然后对子类中定义的成员变量进行赋值:
- (id)copyWithZone:(NSZone *)zone {
id obj = [super copyWithZone:zone];
//对子类定义的成员变量赋值
...
return obj;
}
关于mutableCopy的实现与copy的实现类似,只是实现的是NSMutableCopying协议与mutableCopyWithZone:方法。对于自定义的对象,在我看来并没有什么可变不可变的概念,因此实现mutableCopy其实是没有什么意义的,在此就不详细介绍了。
2、定义属性的copy指示符
如下段代码,我们在定义属性的时候使用了copy指示符:
#import
@interface Person : NSObject
@property (nonatomic, copy) NSMutableString *name;
@end
使用如下代码来进行测试:
Person *person1 = [[Person alloc] init];//创建一个Person对象
person1.name = [NSMutableString stringWithString:@"苏小妖"];
[person1.name appendString:@"123"];
运行程序会崩溃,并且提示以下信息:
*** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: 'Attempt to mutate immutable object with appendString:'
这段错误提示不允许修改person的name属性,这是因为程序定义name属性时使用了copy指示符,该指示符置顶调用setName:方法时(通过点语法赋值时,实际上是调用对应的setter方法),程序实际上会使用参数的副本对name实际变量复制。也就是说,setName:方法的代码如下:
- (void)setName:(NSMutableString *)name {
_name = [name copy];
}
copy方法默认是复制该对象的不可变副本,虽然程序传入的NSMutableString,但程序调用该参数的copy方法得到的是不可变副本。因此,程序赋给Person对象的name实例变量的值依然是不可变字符串。
注意:定义合成getter、setter方法时并没有提供mutableCopy指示符。因此即使定义实例变量时使用了可变类型,但只要使用copy指示符,实例变量实际得到的值总是不可变对象。
2017.08.28
1、 用@property声明的NSString(或NSArray,NSDictionary)经常使用copy关键字,为什么?如果改用strong关键字,可能造成什么问题?
- 因为父类指针可以指向子类对象,使用 copy 的目的是为了让本对象的属性不受外界影响,使用 copy 无论给我传入是一个可变对象还是不可对象,我本身持有的就是一个不可变的副本.
- 如果我们使用是 strong ,那么这个属性就有可能指向一个可变对象,如果这个可变对象在外部被修改了,那么会影响该属性.
- copy 此特质所表达的所属关系与 strong 类似。然而设置方法并不保留新值,而是将其“拷贝” (copy)。 当属性类型为 NSString 时,经常用此特质来保护其封装性,因为传递给设置方法的新值有可能指向一个 NSMutableString 类的实例。这个类是 NSString 的子类,表示一种可修改其值的字符串,此时若是不拷贝字符串,那么设置完属性之后,字符串的值就可能会在对象不知情的情况下遭人更改。所以,这时就要拷贝一份“不可变” (immutable)的字符串,确保对象中的字符串值不会无意间变动。只要实现属性所用的对象是“可变的” (mutable),就应该在设置新属性值时拷贝一份。
1. 对非集合类对象的copy操作:
在非集合类对象中:对 immutable 对象进行 copy 操作,是指针复制,mutableCopy 操作时内容复制;对 mutable 对象进行 copy 和 mutableCopy 都是内容复制。用代码简单表示如下:
[immutableObject copy] // 浅复制
[immutableObject mutableCopy] //深复制
[mutableObject copy] //深复制
[mutableObject mutableCopy] //深复制
2. 集合类对象的copy与mutableCopy
集合类对象是指 NSArray、NSDictionary、NSSet ... 之类的对象。下面先看集合类immutable对象使用 copy 和 mutableCopy 的一个例子:
NSArray *array = @[@[@"a", @"b"], @[@"c", @"d"]];
NSArray *copyArray = [array copy];
NSMutableArray *mCopyArray = [array mutableCopy];
查看内容,可以看到 copyArray 和 array 的地址是一样的,而 mCopyArray 和 array 的地址是不同的。说明 copy 操作进行了指针拷贝,mutableCopy 进行了内容拷贝。但需要强调的是:此处的内容拷贝,仅仅是拷贝 array 这个对象,array 集合内部的元素仍然是指针拷贝。
在集合类对象中,对 immutable 对象进行 copy,是指针复制, mutableCopy 是内容复制;对 mutable 对象进行 copy 和 mutableCopy 都是内容复制。但是:集合对象的内容复制仅限于对象本身,对象元素仍然是指针复制。用代码简单表示如下:
[immutableObject copy] // 浅复制
[immutableObject mutableCopy] //单层深复制
[mutableObject copy] //单层深复制
[mutableObject mutableCopy] //单层深复制
用 @property 声明 NSString、NSArray、NSDictionary 经常使用 copy 关键字,是因为他们有对应的可变类型:NSMutableString、NSMutableArray、NSMutableDictionary,他们之间可能进行赋值操作,为确保对象中的字符串值不会无意间变动,应该在设置新属性值时拷贝一份。
2017.08.25
@synthesize和@dynamic分别有什么作用?
- @property有两个对应的词,一个是 @synthesize,一个是 @dynamic。如果 @synthesize和 @dynamic都没写,那么默认的就是@syntheszie var = _var;
- @synthesize 的语义是如果你没有手动实现 setter 方法和 getter 方法,那么编译器会自动为你加上这两个方法。
- @dynamic 告诉编译器:属性的 setter 与 getter 方法由用户自己实现,不自动生成。(当然对于 readonly 的属性只需提供 getter 即可)。假如一个属性被声明为 @dynamic var,然后你没有提供 @setter方法和 @getter 方法,编译的时候没问题,但是当程序运行到 instance.var = someVar,由于缺 setter 方法会导致程序崩溃;或者当运行到 someVar = var 时,由于缺 getter 方法同样会导致崩溃。编译时没问题,运行时才执行相应的方法,这就是所谓的动态绑定。
之前记录:
一.内存管理:
1.在使用命令行进行编译链接文件的时候,通常是把.m文件单文件编译,然后再把所有的目标文件链接,但是在Xcode中,是把所有的.m文件都进行编译链接的,如果出现重复定义的错误,那大部分问题根源应该就是文件内容被重复包含或者是包含.m文件所引起的。
2.可以说.h和.m文件时完全独立的,只是为了要求有较好的可读性,才要求两个文件的文件名一致,这也是把接口和实现分离,让调用者不必去关心具体的实现细节。
3.Xcode是写一行编译一行,有简单的修复功能,红色是错误提示,黄色警告。如果在程序中声明了一个变量,但是这个变量没有被使用也会产生警告信息。在调试程序的时候,如果发现整个页面都没有报错,但是一运行就错误,那么一定是链接报错。
4.在每个OC对象内部,都专门有4个字节的存储空间来存储引用计数器
5.栈由编译器管理自动释放的,在方法中(函数体)定义的变量通常是在栈内,因此如果你的变量要跨函数的话就需要将其定义为成员变量。
栈区(stack):由编译器自动分配释放,存放函数的参数值,局部变量等值。
堆区(heap):一般由程序员分配释放,若程序员不释放,则可能会引起内存泄漏。注堆和数据结构中的堆栈不一样,其类是与链表。
6.在编译效率方面考虑,如果你有100个头文件都#import了同一个头文件,或者这些文件是依次引用的,如A–>B, B–>C, C–>D这样的引用关系。当最开始的那个头文件有变化的话,后面所有引用它的类都需要重新编译,如果你的类有很多的话,这将耗费大量的时间。而是用 @class则不会。
7.备注:#import 就是把被引用类的头文件走一遍,即把.h文件里的变量和方法包含进来一次,且仅一次,而@class不用,所以后者编译效率更高。
8.备注:实践证明,A,B相互#import不会出现编译错误。能在实现文件中#import,就不在头文件中#import。
9.提示:字符串是特殊的对象,但不需要使用release手动释放,这种字符串对象默认就是autorelease的,不用额外的去管内存
ios中堆栈的区别
管理方式:
对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来讲,释放工作有程序员控制,容易产生memory Leak。
申请大小:
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存区域。这句话的意思是栈顶上的地址和栈的最大容量是系统预先规定好的,在Windows下,栈的大小是2M(也有的说1M,总之是编译器确定的一个常数),如果申请的空间超过了栈的剩余空间时候,就overflow。因此,能获得栈的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大笑受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
碎片的问题:
对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存快从栈中弹出。
分配方式:
堆都是动态分配的,没有静态分配的堆。栈有两种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配是有alloc函数进行分配的,但是栈的动态分配和堆是不同的,他的动态分配由编译器进行释放,无需我们手工实现。
分配效率:
栈是机器系统提供的数据结构,计算机会在底层堆栈提供支持,分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是C/C++函数库提供的,他的机制是很复杂的。
操作系统ios 中应用程序使用的计算机内存不是统一分配空间,运行代码使用的空间在三个不同的内存区域,分成三个段:“text segment “,“stack segment ”,“heap segment ”。
段“text segment ”是应用程序运行时应用程序代码存在的内存段。每一个指令,每一个单个函数、过程、方法和执行代码都存在这个内存段中直到应用程序退出。
“heap” 段也称为”data” 段,提供一个保存中介贯穿函数的执行过程,全局和静态变量保存在“heap”中,直到应用退出。
为了访问你创建在heap 中的数据,你最少要求有一个保存在stack 中的指针,因为你的CPU 通过stack 中的指针访问heap 中的数据。
你可以认为stack 中的一个指针仅仅是一个整型变量,保存了heap 中特定内存地址的数据。实际上,它有一点点复杂,但这是它的基本结构。
简而言之,操作系统使用stack 段中的指针值访问heap 段中的对象。如果stack 对象的指针没有了,则heap 中的对象就不能访问。这也是内存泄露的原因。
stack 栈****对象的创建
只要栈的剩余空间大于stack 对象申请创建的空间,操作系统就会为程序提供这段内存空间,否则将报异常提示栈溢出。
heap 堆****对象的创建
操作系统对于内存heap 段是采用链表进行管理的。操作系统有一个记录空闲内存地址的链表,当收到程序的申请时,会遍历链表,寻找第一个空间大于所申请的heap 节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。
例如:
NSString 的对象就是stack 中的对象,NSMutableString 的对象就是heap 中的对象。前者创建时分配的内存长度固定且不可修改;后者是分配内存长度是可变的,可有多个owner, 适用于计数管理内存管理模式。
两类对象的创建方法也不同,前者直接创建“NSString * str1=@"welcome"; “,而后者需要先分配再初始化“ NSMutableString * mstr1=[[NSMutableString alloc] initWithString:@"welcome"]; ”。
二、变量作用域
1.变量的作用域主要分为四种:
(1)@public (公开的)在有对象的前提下,任何地方都可以直接访问。
(2)@protected (受保护的)只能在当前类和子类的对象方法中访问
(3)@private (私有的)只能在当前类的对象方法中才能直接访问
(4)@package (框架级别的)作用域介于私有和公开之间,只要处于同一个框架中就可以直接通过变量名访问
2.变量的作用域补充
(1)在类的实现即.m文件中也可以声明成员变量,但是因为在其他文件中通常都只是包含头文件而不会包含实现文件,所以在这里声明的成员变量是@private的。在.m中定义的成员变量不能喝它的头文件.h中的成员变量同名,在这期间使用@public等关键字也是徒劳的。
(2)在@interface @end之间声明的成员变量如果不做特别的说明,那么其默认是protected的。
(3)一个类继承了另一个类,那么就拥有了父类的所有成员变量和方法,注意所有的成员变量它都拥有,只是有的它不能直接访问。
2017.05.05
在OC中,所有跟角度相关的数值,都是弧度值,180° = M_PI
正数表示顺时针旋转
负数表示逆时针旋转
提示:由于transform属性可以基于控件的上一次的状态进行叠加形变,例如,先旋转再平移。因此在实际动画开发中,当涉及位置、尺寸形变效果时,大多修改控件的transform属性,而不是frame、bounds、center 。
15 // instancetype会让编译器检查实例化对象的准确类型
16 // instancetype只能用于返回类型,不能当做参数使用
3.instancetype & id的比较
(1) instancetype在类型表示上,跟id一样,可以表示任何对象类型
(2) instancetype只能用在返回值类型上,不能像id一样用在参数类型上
(3) instancetype比id多一个好处:编译器会检测instancetype的真实类型
- 使用KVC间接修改对象属性时,系统会自动判断对象属性的类型,并完成转换。如该程序中的“23”.
- KVC按照键值路径取值时,如果对象不包含指定的键值,会自动进入对象内部,查找对象属性
- 蓝色文件夹(folder)一般作为资源文件夹使用,与黄色文件夹的主要区别是不参与编译,所以说如果你在这些文件夹下编写的逻辑代码是不参与编译的,其他文件也不能直接引用它们,若引用其中文件需要全路径。
- 黄色文件夹(group)是逻辑文件夹,主要是为了逻辑上的分组,如果手动创建(通过New Group选项)group并不会真正创建一个文件夹文件,该文件夹下的文件则会散乱的存放在工程根目录下。当然我们通常会让Xcode中的文件树与实际工程文件中的文件树保持一致。
既然两种都可以对状态栏进行管理,那么什么时候该用什么呢?
如果状态栏的样式只设置一次,那就用UIApplication来进行管理;
如果状态栏是否隐藏,样式不一样那就用控制器进行管理。
UIApplication来进行管理有额外的好处,可以提供动画效果。
程序启动原理
UIApplicationMain
main函数中执行了一个UIApplicationMain这个函数
intUIApplicationMain(int argc, char *argv[], NSString *principalClassName, NSString *delegateClassName);
argc、argv:直接传递给UIApplicationMain进行相关处理即可
principalClassName:指定应用程序类名(app的象征),该类必须是UIApplication(或子类)。如果为nil,则用UIApplication类作为默认值
delegateClassName:指定应用程序的代理类,该类必须遵守UIApplicationDelegate协议
UIApplicationMain函数会根据principalClassName创建UIApplication对象,根据delegateClassName创建一个delegate对象,并将该delegate对象赋值给UIApplication对象中的delegate属性
接着会建立应用程序的Main Runloop(事件循环),进行事件的处理(首先会在程序完毕后调用delegate对象的application:didFinishLaunchingWithOptions:方法)
程序正常退出时UIApplicationMain函数才返回
系统入口的代码和参数说明:
argc:系统或者用户传入的参数
argv:系统或用户传入的实际参数
1.根据传入的第三个参数,创建UIApplication对象
2.根据传入的第四个产生创建UIApplication对象的代理
3.设置刚刚创建出来的代理对象为UIApplication的代理
4.开启一个事件循环(可以理解为里面是一个死循环)这个时间循环是一个队列(先进先出)先添加进去的先处理
四、程序启动的完整过程
1.main函数
2.UIApplicationMain
- 创建UIApplication对象
- 创建UIApplication的delegate对象
3.delegate对象开始处理(监听)系统事件(没有storyboard)
- 程序启动完毕的时候, 就会调用代理的application:didFinishLaunchingWithOptions:方法
- 在application:didFinishLaunchingWithOptions:中创建UIWindow
- 创建和设置UIWindow的rootViewController
- 显示窗口
3.根据Info.plist获得最主要storyboard的文件名,加载最主要的storyboard(有storyboard)
- 创建UIWindow
- 创建和设置UIWindow的rootViewController
- 显示窗口
代理的内存警告:当application发生一些事情的时候(接收到内存警告的时候),会先通知它的代理,之后代理会通知它的window,window会通知它的根控制器,根控制器会通知它的子控制器。内存警告是由上往下一层一层往下传的。
应用程序启动之后,先创建Application,再创建它的代理,之后创建UIwindow。UIWindow继承自UIview。
当用户点击应用程序图标的时候,先执行Main函数,执行UIApplicationMain(),根据其第三个和第四个参数创建Application,创建代理,并且把代理设置给application(看项目配置文件info.plist里面的storyboard的name,根据这个name找到对应的storyboard),开启一个事件循环,当程序加载完毕,他会调用代理的didFinishLaunchingWithOptions:方法。在调用didFinishLaunchingWithOptions:方法之前,会加载storyboard,在加载的时候创建一个window,接下来会创建箭头所指向的控制器,把该控制器设置为UIWindow的根控制器,接下来再将window显示出来,即看到了运行后显示的界面。(提示:关于这部分可以查看story的初始化的文档)
[UIApplication sharedApplication].windows 在本应用中打开的UIWindow列表,这样就可以接触应用中的任何一个UIView对象(平时输入文字弹出的键盘,就处在一个新的UIWindow中)
[UIApplication sharedApplication].keyWindow(获取应用程序的主窗口)用来接收键盘以及非触摸类的消息事件的UIWindow,而且程序中每个时刻只能有一个UIWindow是keyWindow。
提示:如果某个UIWindow内部的文本框不能输入文字,可能是因为这个UIWindow不是keyWindowview.window获得某个UIView所在的UIWindow
控制器的view是延迟加载的:用到时再加载
可以用isViewLoaded方法判断一个UIViewController的view是否已经被加载
控制器的view加载完毕就会调用viewDidLoad方法
2017.05.08
属性列表是一种XML格式的文件,拓展名为plist
● 如果对象是NSString、NSDictionary、NSArray、NSData、 NSNumber等类型,就可以使用writeToFile:atomically:⽅法 直接将对象写到属性列表文件中
plist只能存储系统自带的一些常规的类, 也就是有writeToFile方法的对象才可以使用plist保存数据 字符串/字典/数据/NSNumber/NSData ...
Documents:保存应⽤运行时生成的需要持久化的数据,iTunes同步设备时会备份该目录。例如,游戏应用可将游戏存档保存在该目录
tmp:保存应⽤运行时所需的临时数据,使⽤完毕后再将相应的文件从该目录删除。应用没有运行时,系统也可能会清除该目录下的文件。iTunes同步设备时 不会备份该目录
Library/Caches:保存应用运行时⽣成的需要持久化的数据,iTunes同步设备时不会备份该目录。⼀一般存储体积大、不需要备份的非重要数据
Library/Preference:保存应用的所有偏好设置,iOS的Settings(设置) 应⽤会在该⺫录中查找应⽤的设置信息。iTunes同步设备时会备份该目录
● 沙盒根目录:NSString *home = NSHomeDirectory(); ● Documents:(2种⽅方式)
● 利用沙盒根目录拼接”Documents”字符串NSString *home = NSHomeDirectory();NSString *documents = [home stringByAppendingPathComponent:@"Documents"]; // 不建议采用,因为新版本的操作系统可能会修改目录名
● 利⽤NSSearchPathForDirectoriesInDomains函数// NSUserDomainMask 代表从用户文件夹下找// YES 代表展开路径中的波浪字符“~”NSArray *array = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, NO); // 在iOS中,只有一个目录跟传入的参数匹配,所以这个集合里面只有一个元素
NSString *documents = [array objectAtIndex:0];
● tmp:NSString *tmp = NSTemporaryDirectory();
● Library/Caches:(跟Documents类似的2种⽅方法)
● 利用沙盒根目录拼接”Caches”字符串
● 利⽤NSSearchPathForDirectoriesInDomains函数(将函数的第2个参数改 为:NSCachesDirectory即可)
● Library/Preference:通过NSUserDefaults类存取该目录下的设置信息
一、ios应用常用的数据存储方式
1.plist(XML属性列表归档)Documents
2.偏好设置 Library/Preference
3.NSKeydeArchiver归档(存储自定义对象)
4.SQLite3(数据库,关系型数据库,不能直接存储对象,要编写一些数据库的语句,将对象拆开存储)
5.Core Data(对象型的数据库,把内部环节屏蔽)
#import "YYPerson.h"
@implementation YYPerson
-(void)encodeWithCoder:(NSCoder *)aCoder
{NSLog(@"调用了encodeWithCoder:方法");
[aCoder encodeObject:self.name forKey:@"name"];
[aCoder encodeInteger:self.age forKey:@"age"];
[aCoder encodeDouble:self.height forKey:@"height"]; } // 当从文件中读取一个对象的时候就会调用该方法 //
在该方法中说明如何读取保存在文件中的对象 // 也就是说在该方法中说清楚怎么读取文件中的对象
-(id)initWithCoder:(NSCoder *)aDecoder {
NSLog(@"调用了initWithCoder:方法");//注意:在构造方法中需要先初始化父类的方法
if (self=[super init]) {
self.name=[aDecoder decodeObjectForKey:@"name"];
self.age=[aDecoder decodeIntegerForKey:@"age"];
self.height=[aDecoder decodeDoubleForKey:@"height"];
}
return self;
}
NSString *docPath=[NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES)lastObject];
NSString *path=[docPath stringByAppendingPathComponent:@"person.yangyang"];
1.将自定义的对象保存到文件中 [NSKeyedArchiver archiveRootObject:s toFile:path];
2.从文件中读取对象 YYstudent *s=[NSKeyedUnarchiver unarchiveObjectWithFile:path];
3.遵守NSCoding协议,并实现该协议中的两个方法。
4.如果是继承,则子类一定要重写那两个方法。因为person的子类在存取的时候,会去子类中去找调用的方法,没找到那么它就去父类中找,所以最后保存和读取的时候新增加的属性会被忽略。需要先调用父类的方法,先初始化父类的,再初始化子类的。
5.保存数据的文件的后缀名可以随意命名。
6.通过plist保存的数据是直接显示的,不安全。通过归档方法保存的数据在文件中打开是乱码的,更安全。
先重新切换到消息界面,one控制器直接即将显示,没有进行加载证明了第一个view移除后并没有被销毁(因为它的控制器还存在,有一个强引用引用着它),且two的view移除后也没有被销毁。无论怎么切换,控制器和view都不会被销毁。
UINavigationController和UITabBarController一个通过栈来管理,一个通过普通的数组来进行管理。提示在实际的开发中,如果控制器之间的关系紧密一般用导航控制器,如果控制器之间的关系不是很紧密就用modal
利用UIKit框架提供的控件,拼拼凑凑,能搭建和现实一些简单、常见的UI界⾯
但是,有些UI界面极其复杂、⽽且⽐较个性化,⽤普通的UI控件无法实现,这时可以利用Quartz2D技术将控件内部的结构画出来,自定义控件的样子
其实,iOS中⼤部分控件的内容都是通过Quartz2D画出来的
(1)为什么要实现drawRect:方法才能绘图到view上?
因为在drawRect:方法中才能取得跟view相关联的图形上下文
(2)drawRect:方法在什么时候被调用?
当view第一次显示到屏幕上时(被加到UIWindow上显示出来)
**调用view的setNeedsDisplay或者setNeedsDisplayInRect:时 **
注意:不要直接调用 drawRect
. 如果你需要更新视图,调用 setNeedsDisplay()
方法
setNeedsDisplay()
不会自己调用 drawRect
方法,但是会标记视图,让视图通过 drawRect
重绘在下一次循环更新的时候。 所以当你在一个方法里面多次调用 setNeedsDisplay()
的时候,你实际上也只是调用了一次 drawRect
Quartz 2D是⼀个二维绘图引擎,同时支持iOS和Mac系统,Quartz 2D能完成的工作:
- 绘制图形 : 线条\三角形\矩形\圆\弧等
- 绘制文字
- 绘制\生成图片(图像)
- 读取\生成PDF
- 截图\裁剪图片
- 自定义UI控件
Quartz2D的API是纯C语⾔言的Quartz2D的API来自于Core Graphics框架
数据类型和函数基本都以CG作为前缀
CGContextRefCGPathRefCGContextStrokePath(ctx);
在drawRect:方法中取得上下文后,就可以绘制东西到view上
View内部有个layer(图层)属性,drawRect:方法中取得的是一个Layer Graphics Context,因此,绘制的东西其实是绘制到view的layer上去了
View之所以能显示东西,完全是因为它内部的layer
// NSMutableDictionary *md = [NSMutableDictionary dictionary]; // // 设置文字颜色 //
md[NSForegroundColorAttributeName] =[UIColor redColor]; // // 设置文字背景颜色 //
md[NSBackgroundColorAttributeName] = [UIColor greenColor];// // 设置文字大小
// md[NSFontAttributeName] = [UIFont systemFontOfSize:20];// 将文字绘制到指点的位置
[str drawAtPoint:CGPointMake(10, 10) withAttributes:md]; // 将文字绘制到指定的范围内, 如果一行装不下会自动换行, 当文字超出范围后就不显示
[str drawInRect:CGRectMake(50, 50, 100, 100) withAttributes:nil];
// 利用drawAsPatternInRec方法绘制图片到layer, 是通过平铺原有图片[image drawAsPatternInRect:CGRectMake(0, 0, 320, 480)];
// 利用drawInRect方法绘制图片到layer, 是通过拉伸原有图片16 [image drawInRect:CGRectMake(0, 0, 200, 200)];
// 将图片绘制到指定的位置24
[image drawAtPoint:CGPointMake(100, 100)];
程序启动,显示自定义的view。当程序第一次显示在我们眼前的时候,程序会调用drawRect:方法,在里面获取了图形上下文(在内存中拥有了),然后利用图形上下文保存绘图信息,可以理解为图形上下文中有一块区域用来保存绘图信息,有一块区域用来保存绘图的状态(线宽,圆角,颜色)。直线不是直接绘制到view上的,可以理解为在图形上下文中有一块单独的区域用来先绘制图形,当调用渲染方法的时候,再把绘制好的图形显示到view上去。
//保存一份最初的图形上下文 6CGContextSaveGState(ctx);
//还原开始的时候保存的那份最纯洁的图形上下文CGContextRestoreGState(ctx);
注意:在栈里保存了几次,那么就可以取几次(比如不能保存了1次,取两次,在取第二次的时候,栈里为空会直接挂掉)
CGContextRef ctx=UIGraphicsGetCurrentContext(); //矩阵操作
注意点:设置矩阵操作必须要在添加绘图信息之前 //旋转45度 CGContextRotateCTM(ctx, M_PI_4);
提示:旋转的时候,是整个layer都旋转了。
drawRect:方法不能由我们自己手动调用,只能由系统来调用。
drawRect:调用的时机:当第一次显示或者一个重绘事件发生时调用。
setNeedsDisplay方法:重新绘制,调用这个方法就会通知自定义的view重新绘制画面,调用drawRect:。
提示:当一个view从xib或storyboard创建出来时,会调用awakefromnib方法。
- NSTimer一般用于定时的更新一些非界面上的数据,告诉多久调用一次
- 使用定时器,使用该定时器会出现卡顿的现象
[NSTimer scheduledTimerWithTimeInterval:0.1 target:self selector:@selector(updateImage) userInfo:nil repeats:YES];
CADisplayLink刷帧,默认每秒刷新60次,该定时器创建之后,默认是不会执行的,需要把它加载到消息循环中
CADisplayLink *display= [CADisplayLink displayLinkWithTarget:self selector:@selector(updateImage)];
[display addToRunLoop:[NSRunLoop mainRunLoop] forMode:NSDefaultRunLoopMode];
以前的方法是点的位置添加到ctx(图形上下文信息)中,ctx 默认会在内部创建一个path用来保存绘图信息。
在图形上下文中有一块存储空间专门用来存储绘图信息,其实这块空间就是CGMutablePathRef。
- 注意:但凡通过Quartz2D中带有creat/copy/retain方法创建出来的值都必须要释放,
CGMutablePathRef path=CGPathCreateMutable(); //2.2把绘图信息添加到路径里
CGPathMoveToPoint(path, NULL, 20, 20);
CGPathAddLineToPoint(path, NULL, 200, 300);
//把绘制直线的绘图信息保存到图形上下文中
CGContextAddPath(ctx, path);
但凡通过quarzt2d中带有creat/copy/retain方法创建出来的值都必须手动的释放
有两种方法可以释放前面创建的路径:
(1)CGPathRelease(path);
(2)CFRelease(path);
说明:CFRelease属于更底层的cocafoundation框架
2017.05.10
CAAnimation是所有动画类的父类,但是它不能直接使用,应该使用它的子类
Core Animation的动画执行过程都是在后台操作的,不会阻塞主线程。不阻塞主线程
使用它需要先添加QuartzCore.framework框架和引入主头文件
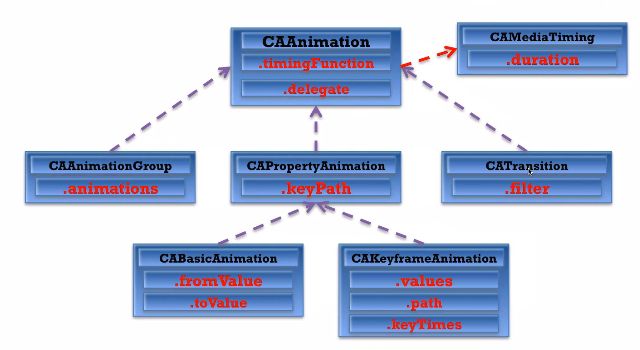
能用的动画类只有4个子类:CABasicAnimation、CAKeyframeAnimation、CATransition、CAAnimationGroup
CAMediaTiming是一个协议(protocol)。
CABasicAnimation和CAKeyframeAnimation
它有个NSString类型的keyPath属性,你可以指定CALayer的某个属性名为keyPath,并且对CALayer的这个属性的值进行修改,达到相应的动画效果。
比如,指定@"position"为keyPath,就会修改CALayer的position属性的值,以达到平移的动画效果
说明:CABasicAnimation可看做是最多只有2个关键帧的CAKeyframeAnimation
CABasicAnimation只能从一个数值(fromValue)变到另一个数值(toValue),而CAKeyframeAnimation会使用一个NSArray保存这些数值
使用UIView和CALayer都能实现动画效果,但是在真实的开发中,一般还是主要使用UIView封装的动画,而很少使用CALayer的动画。
CALayer核心动画与UIView动画的区别:UIView封装的动画执行完毕之后不会反弹。即如果是通过CALayer核心动画改变layer的位置状态,表面上看虽然已经改变了,但是实际上它的位置是没有改变的。
2017.05.11
iOS开发的建议
所有属性都声明为nonatomic
尽量避免多线程抢夺同一块资源
尽量将加锁、资源抢夺的业务逻辑交给服务器端处理,减小移动客户端的压力
那又为什么只有线程thread2退出呢?(注:每次退出的线程是不确定的)因为当线程thread2退出了,并没有执行完@synchronized里的方法,线程thread1和线程thread3还在等thread2执行完了,它们好去执行呢。但是线程thread2已经死了,不可能再执行了。这就造成线程thread1和线程thread3一直都在内存里,没有被退出,造成了CPU不必要的开销,所以我们最好不要在@synchronized里面退出线程。
主队列里的任务必须在异步函数中执行。
OC在定义属性时有nonatomic和atomic两种选择atomic:原子属性,为setter方法加锁(默认就是atomic)nonatomic:非原子属性,不会为setter方法加锁atomic加锁原理复制代码1
@property (assign, atomic) int age;
- (void)setAge:(int)age {
@synchronized(self) {
_age = age;
}
}

GCD的数据类型在ARC的环境下不需要再做release。
CF(core Foundation)的数据类型在ARC环境下还是需要做release。
异步函数具备开线程的能力,但不一定会开线程
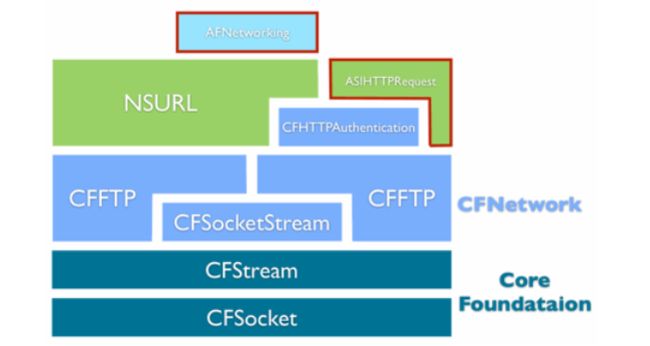
在项目开发中,通常都需要对数据进行离线缓存的处理,如新闻数据的离线缓存等。说明:离线缓存一般都是把数据保存到项目的沙盒中。有以下几种方式:
- 归档:NSCodeing、NSKeyedArchiver
- 偏好设置:NSUserDefaults
- Plist存储:writeToFile
提示:上述三种方法都有一个致命的缺点,那就是都无法存储大批量的数据,有性能的问题。举例:使用归档两个问题:
(1)数据的存取都必须是完整的,要求写入的时候要一次性写入,读取的时候要一次性全部读取,这涉及到应用的性能问题。
(2)如果有1000条数据,此时要把第1001条数据存入,那么需要把所有的数据取出来,把这条数据加上去之后,再存入。
说明:以上的三种技术不能处理大批量数据的存储,大批量数据通常使用数据库来进行存储。
static的第一个作用是,也是最重要的一条:隐藏
static的第二个作用是保持变量内容的持久
static的第三个作用是默认初始化为0
先调用试图控制器的viewWillLayoutSubviews 以及viewDidLayoutSubviews,然后调用view的layoutSubviews、layoutSubviews 。最后调用drawRect
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<