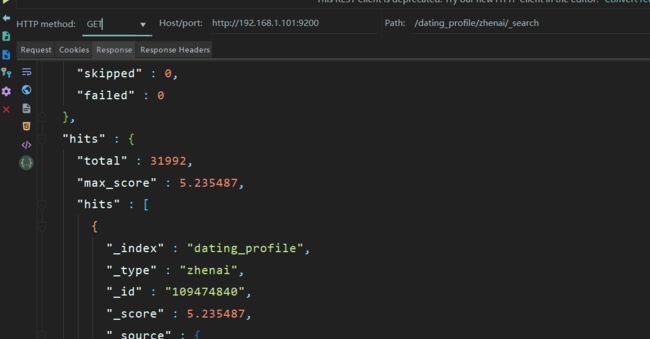
golang爬取珍爱网,爬到了3万多用户信息,并存到了elasticsearch中,如下图,查询到了3万多用户信息。
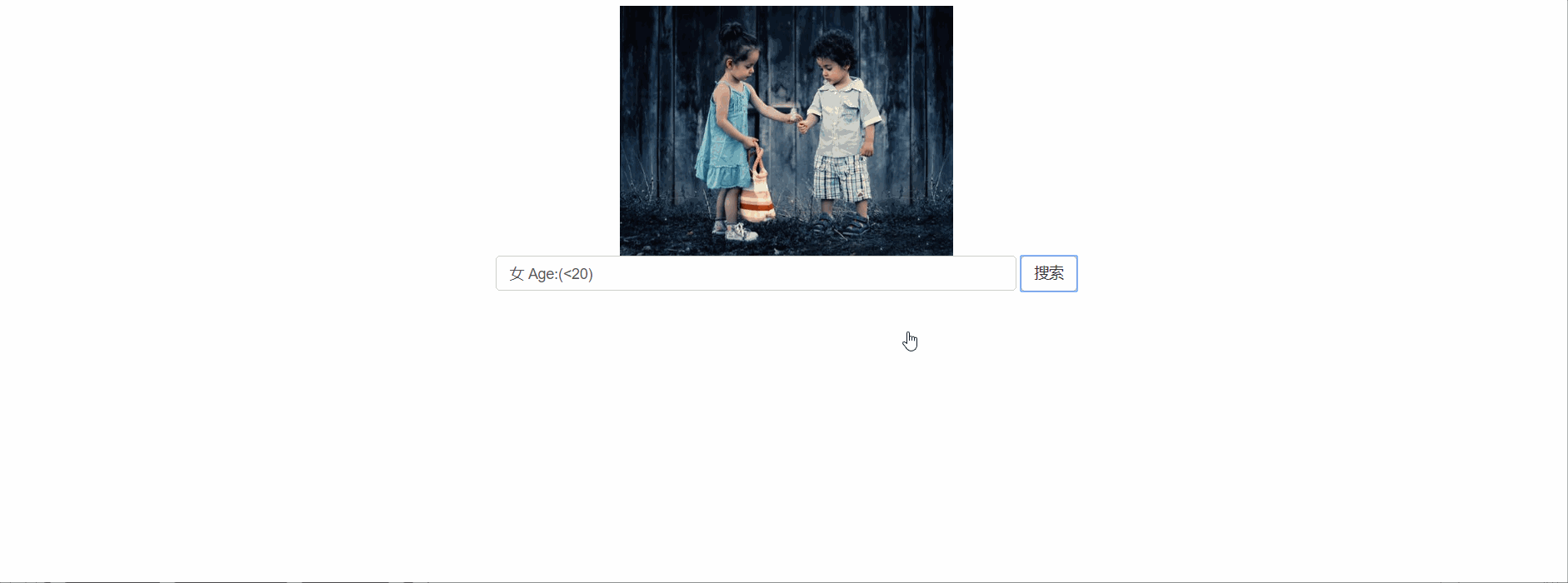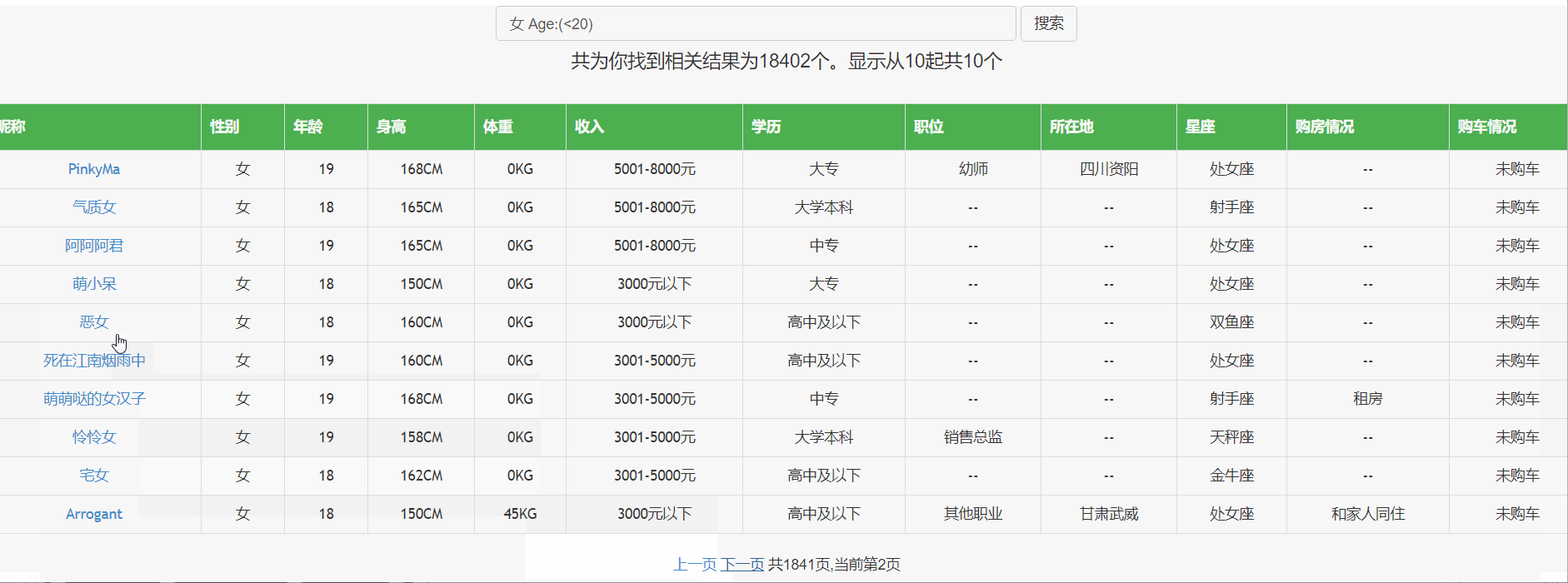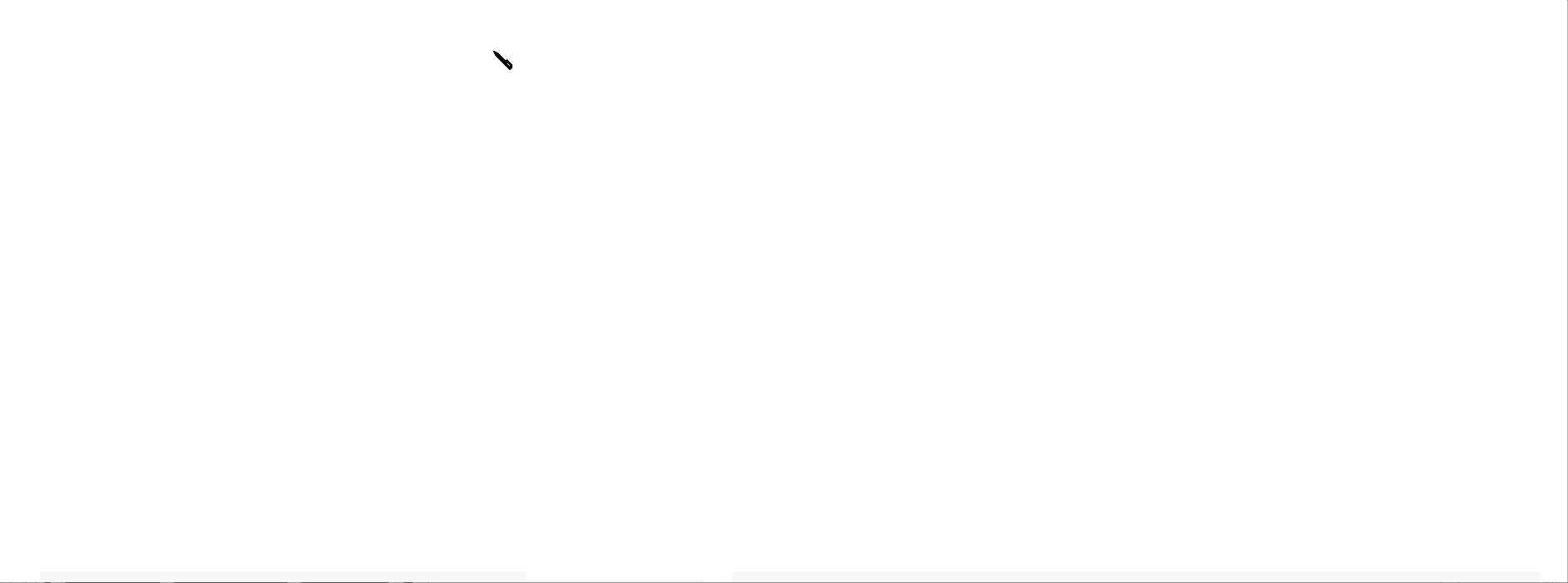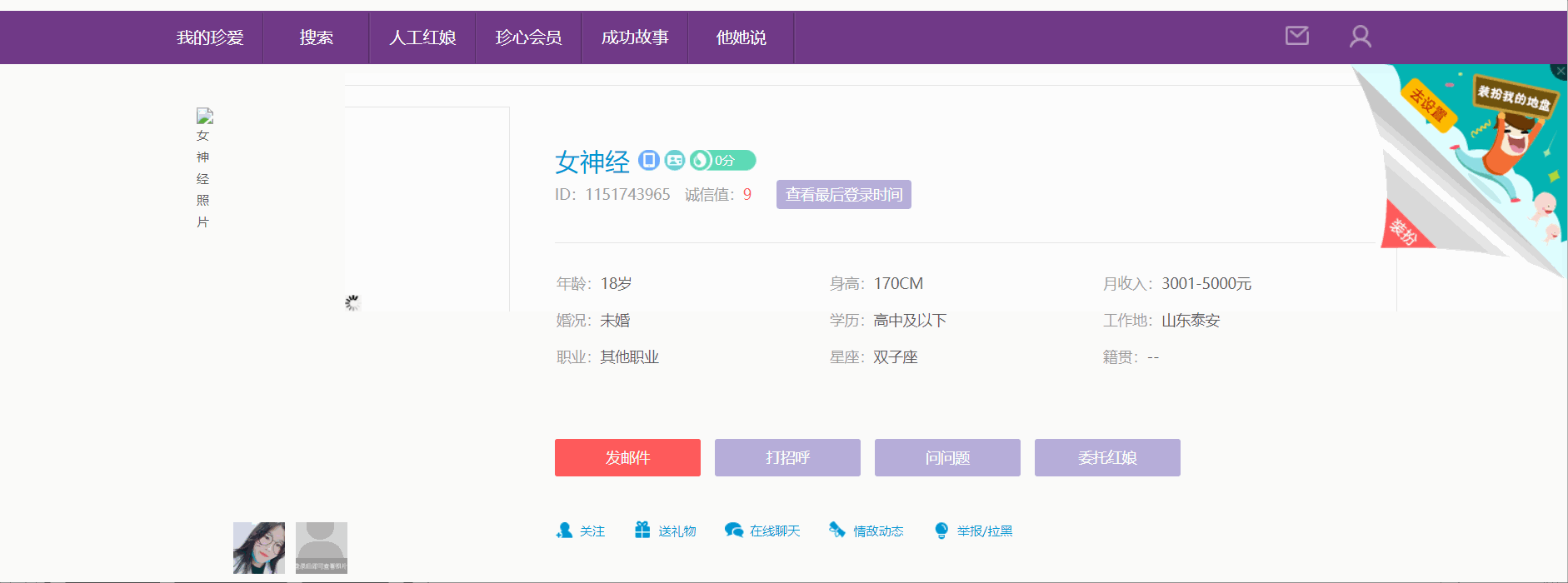
先来看看最终效果:
利用到了go语言的html模板库:
执行模板渲染:
func (s SearchResultView) Render (w io.Writer, data model.SearchResult) error {
return s.template.Execute(w, data)
}
model.SearchResult数据结构如下:
type SearchResult struct {
Hits int64
Start int
Query string
PrevFrom int
NextFrom int
CurrentPage int
TotalPage int64
Items []interface{}
//Items []engine.Item
}
```html
Love Search
共为你找到相关结果为{{.Hits}}个。显示从{{.Start}}起共{{len .Items}}个
昵称
性别
年龄
身高
体重
收入
学历
职位
所在地
星座
购房情况
购车情况
{{range .Items}}
{{.Payload.Name}}
{{with .Payload}}
{{.Gender}}
{{.Age}}
{{.Height}}CM
{{.Weight}}KG
{{.Income}}
{{.Education}}
{{.Occupation}}
{{.Hukou}}
{{.Xinzuo}}
{{.House}}
{{.Car}}
{{end}}
{{else}}
没有找到相关用户
{{end}}
其中用到了模板语法中的变量、函数、判断、循环;
模板函数的定义:
上面模板代码中的上一页、下一页的a标签href里用到了自定义模板函数Add和Sub分别用于获取上一页和下一页的页码,传到后台(这里并没有用JavaScript去实现)。
html/template包中提供的功能有限,所以很多时候需要使用用户定义的函数来辅助渲染页面。下面讲讲模板函数如何使用。template包创建新的模板的时候,支持.Funcs方法来将自定义的函数集合导入到该模板中,后续通过该模板渲染的文件均支持直接调用这些函数。
函数声明
// Funcs adds the elements of the argument map to the template's function map.
// It panics if a value in the map is not a function with appropriate return
// type. However, it is legal to overwrite elements of the map. The return
// value is the template, so calls can be chained.
func (t *Template) Funcs(funcMap FuncMap) *Template {
t.text.Funcs(template.FuncMap(funcMap))
return t
}
Funcs方法就是用来创建我们模板函数了,它需要一个FuncMap类型的参数:
// FuncMap is the type of the map defining the mapping from names to
// functions. Each function must have either a single return value, or two
// return values of which the second has type error. In that case, if the
// second (error) argument evaluates to non-nil during execution, execution
// terminates and Execute returns that error. FuncMap has the same base type
// as FuncMap in "text/template", copied here so clients need not import
// "text/template".
type FuncMap map[string]interface{}
使用方法:
在go代码中定义两个函数Add和Sub:
//减法,为了在模板里用减1
func Sub(a, b int) int {
return a - b
}
//加法,为了在模板里用加1
func Add(a, b int) int {
return a + b
}
模板绑定模板函数:
创建一个FuncMap类型的map,key是模板函数的名字,value是刚才定义函数名。
将 FuncMap注入到模板中。
filename := "../view/template_test.html"
template, err := template.New(path.Base(filename)).Funcs(template.FuncMap{"Add": Add, "Sub": Sub}).ParseFiles(filename)
if err != nil {
t.Fatal(err)
}
模板中如何使用:
如上面html模板中上一页处的:
{{Sub .CurrentPage 1}}
把渲染后的CurrentPage值加1
注意:
1、函数的注入,必须要在parseFiles之前,因为解析模板的时候,需要先把函数编译注入。
2、Template object can have multiple templates in it and each one has a name. If you look at the implementation of ParseFiles, you see that it uses the filename as the template name inside of the template object. So, name your file the same as the template object, (probably not generally practical) or else use ExecuteTemplate instead of just Execute.
3、The name of the template is the bare filename of the template, not the complete path。如果模板名字写错了,执行的时候会出现:
error: template: “…” is an incomplete or empty template
尤其是第三点,我今天就遇到了,模板名要用文件名,不能是带路径的名字,看以下代码:
func TestTemplate3(t *testing.T) {
//filename := "crawler/frontend/view/template.html"
filename := "../view/template_test.html"
//file, _ := os.Open(filename)
t.Logf("baseName:%s\n", path.Base(filename))
tpl, err := template.New(filename).Funcs(template.FuncMap{"Add": Add, "Sub": Sub}).ParseFiles(filename)
if err != nil {
t.Fatal(err)
}
page := common.SearchResult{}
page.Hits = 123
page.Start = 0
item := engine.Item {
Url: "http://album.zhenai.com/u/107194488",
Type: "zhenai",
Id: "107194488",
Payload: model.Profile{
Name: "霓裳",
Age: 28,
Height: 157,
Marriage: "未婚",
Income: "5001-8000元",
Education: "中专",
Occupation: "程序媛",
Gender: "女",
House: "已购房",
Car: "已购车",
Hukou: "上海徐汇区",
Xinzuo: "水瓶座",
},
}
page.CurrentPage = 1
page.TotalPage = 10
page.Items = append(page.Items, item)
afterHtml, err := os.Create("template_test1.html")
if err != nil {
t.Fatal(err)
}
tpl.Execute(afterHtml, page)
}
这里在template.New(filename)传入的是文件名(上面定义时是带路径的文件名),导致执行完代码后template_test1.html文件是空的,当然测试类的通过的,但是将此渲染到浏览器的时候,就会报:
template: “…” is an incomplete or empty template
所以,要使用文件的baseName,即:
tpl, err := template.New(path.Base(filename)).Funcs(template.FuncMap{"Add": Add, "Sub": Sub}).ParseFiles(filename)
这样运行代码后template_test1.html就是被渲染有内容的。
其他语法:变量、判断、循环用法比较简单,我没遇到问题;其他语法,如:模板的嵌套,我目前没用到,在此也不做赘述。
查询遇到的问题:
因为查询每页显示10条记录,查询第1000页是正常的,当查询大于等于1001页的时候,会报如下错误:
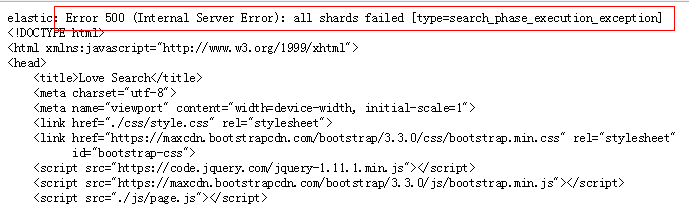
用restclient工具调,错误更明显了:
{
"error" : {
"root_cause" : [
{
"type" : "query_phase_execution_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10010]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "dating_profile",
"node" : "bJhldvT6QeaRTvHmBKHT4Q",
"reason" : {
"type" : "query_phase_execution_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10010]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
]
},
"status" : 500
}
问了谷哥后发现,是由于ElasticSearch的默认 深度翻页 机制的限制造成的。ES默认的分页机制一个不足的地方是,比如有5010条数据,当你仅想取第5000到5010条数据的时候,ES也会将前5000条数据加载到内存当中,所以ES为了避免用户的过大分页请求造成ES服务所在机器内存溢出,默认对深度分页的条数进行了限制,默认的最大条数是10000条,这是正是问题描述中当获取第10000条数据的时候报Result window is too large异常的原因。(因为页面为1001页的时候后台1001-1然后乘以10作为from的值取查询ES,而ES默认需要from+size要小于index.max_result_window: 最大窗口值)。
要解决这个问题,可以使用下面的方式来改变ES默认深度分页的index.max_result_window 最大窗口值
curl -XPUT http://127.0.0.1:9200/dating_profile/_settings -d '{ "index" : { "max_result_window" : 50000}}'
这里的dating_profile为index。
其中my_index为要修改的index名,50000为要调整的新的窗口数。将该窗口调整后,便可以解决无法获取到10000条后数据的问题。
注意事项
通过上述的方式解决了我们的问题,但也引入了另一个需要我们注意的问题,窗口值调大了后,虽然请求到分页的数据条数更多了,但它是用牺牲更多的服务器的内存、CPU资源来换取的。要考虑业务场景中过大的分页请求,是否会造成集群服务的OutOfMemory问题。在ES的官方文档中对深度分页也做了讨论
https://www.elastic.co/guide/en/elasticsearch/guide/current/pagination.html
https://www.elastic.co/guide/en/elasticsearch/guide/current/pagination.html
核心的观点如下:
Depending on the size of your documents, the number of shards, and the hardware you are using, paging 10,000 to 50,000 results (1,000 to 5,000 pages) deep should be perfectly doable. But with big-enough from values, the sorting process can become very heavy indeed, using vast amounts of CPU, memory, and bandwidth. For this reason, we strongly advise against deep paging.
这段观点表述的意思是:根据文档的大小,分片的数量以及使用的硬件,分页10,000到50,000个结果(1,000到5,000页)应该是完全可行的。 但是,从价值观上来看,使用大量的CPU,内存和带宽,分类过程确实会变得非常重要。 为此,我们强烈建议不要进行深度分页。
ES作为一个搜索引擎,更适合的场景是使用它进行搜索,而不是大规模的结果遍历。 大部分场景下,没有必要得到超过10000个结果项目, 例如,只返回前1000个结果。如果的确需要大量数据的遍历展示,考虑是否可以用其他更合适的存储。或者根据业务场景看能否用ElasticSearch的 滚动API (类似于迭代器,但有时间窗口概念)来替代。
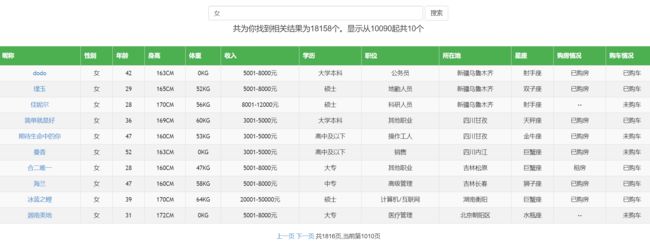
到此展示的问题就解决了:
项目代码见:https://github.com/ll837448792/crawler
最后,csdn资源,收集了海量学习资料,如果你准备入IT坑,励志成为优秀的程序猿,那么这些资源很适合你,包括java、go、python、springcloud、elk、嵌入式 、大数据、面试资料、前端等资源。同时我们组建了一个技术交流群,里面有很多大佬,会不定时分享技术文章,如果你想来一起学习提高,可以关注以下公众号后回复【2】,获取。
我是小碗汤,我们一起学习,扫码关注,精彩内容第一时间推给你

参考文章:
Golang模板函数使用范例:
https://blog.csdn.net/wj199395/article/details/75040723
Go模板入门 | Hugo 21:
http://www.g-var.com/posts/translation/hugo/hugo-21-go-template-primer/
golang 模板(template)的常用基本语法:
https://studygolang.com/articles/8023
解决ElasticSearch深度分页机制中Result window is too large问题
https://blog.csdn.net/lisongjia123/article/details/79041402